
In my previous blog post, I wrote about situations when an increase in user traffic could cause your website a lot of trouble. Unexpected popularity, instead of bringing you new customers, could cause the web services to go down. Today I would like to share with you a story from my own experience, a lesson learned from the spectacular crash of a popular startup. How did it happen? How did it recover? And how this spectacular disaster hardened the website and made it ready for the future?
A successful startup gaining traction
SzukamLapka is a very popular polish website that advises on purchasing laptops. It helps both IT newbies, and more tech-savvy customers as well. Its AI-driven algorithms review specs, benchmarks and offers to "understand" the industry and generate personalized rankings of the best gear.
As Accesto, we have been their partners since early, MVP stages of SzukamLapka. This year they are launching a global version under the brand NotebookRank, but a few years ago, they were just a local startup, growing and gaining traction on a polish market. But in the late Monday evening of August 2017, this growth got out of control...
Surviving the hug of death
Almost every country has its equivalent to Reddit or Digg websites - places where users share, rate, and discuss useful links. In Poland, it is Wykop.pl, and on that day, someone who considered SzukamLapka to be very useful shared this knowledge with Wykop users. And it wasn’t the only person who found the named service worth using...
In the first hour after being mentioned the number of visitors doubled, but that was just a beginning. The exponential growth continued for the next 5 hours, reaching almost 10,000% late evening. That is a hundred times more users than usual!
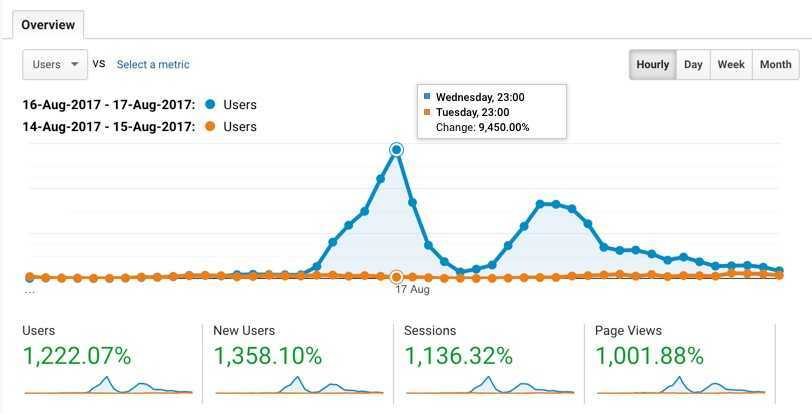
Usually, it is called a Reddit Hug of Death, or a Slashdot Effect, and in Poland... a Wykop Effect. It derives from the names of popular websites that caused many other sites to crash due to the abrupt increase in short term traffic.
So what happened?
Probably you won't be surprised if I tell you that the website crashed. But, to be honest, we were a little bit surprised back then. The website was already prepared to handle quite high volumes of traffic. It was optimized and performed well. Even when we did load testing with 20× more users than on an average day, all the rankings were generated in under 1 second. But sometimes you can't spot the bottlenecks until you see them stuck.
So what may be the bottleneck of a website that displays laptop rankings? The thing is that it isn’t just a simple website. Like most of the modern digital products, it is a complex web application, a multi-layer platform that consists of many services. And the bottleneck emerged between two of such services. The one that does all the complex calculations, and the other that uses these bare technical data and makes them more human-friendly. The question arose, why even though these two were connected via a robust and lightspeed API, the problem occurred?

Both services were performing very well, but sometimes the connection between them was lost for a few short milliseconds. And that was the part that we did not take into account. Although this was a very short break in communication, one of the services, instead of retrying to connect, kept hanging for around 3 minutes. We didn’t notice it in advance as it happened only once every few thousand page views. And of course, we had a few services like this working in parallel. So if one user waited too long, he could easily refresh the page and get the results immediately from another non-hanging service.
But on that day, the volume of users was so high that this quite rare situation of stuck service happened on all the services, and users started to get 504 errors - indicating that the server did not respond in time. The site went completely down.
Solving the problem
The temporary solution was quite simple. When we diagnosed the problem, we quickly increased the number of available services and restarted all the stuck ones. We had to repeat this few times, as new services kept hanging. But in general, that temporarily solved the problem and allowed us to survive till the morning.
The next day, we started by making sure that last night's nightmare won't happen again. We did it in 4 steps.
Step 1: adopt the fail-safe approach in your web application
We already knew that there could be temporary connection issues with the API, and to handle this, we added proper timeouts and retries. So if the connection is lost, service does not wait long, and after a second or so, tries to connect again. And there are few attempts, each with slightly longer timeouts (to get the response even if the network connection is slow for some reason).
According to Murphy's law, if something can fail, it will fail, and it is true also for web applications. It is good practice to take potential failures into account and make web apps ready for them by design. This is known as a fail-safe approach and is especially important if you integrate with some external, third party API’s - which may not always be available, or behave in the way we expect.
Step 2: make sure you calculate same things only once
Although the connection with the API should no longer cause the trouble, we knew that this was the most compute-heavy part of the platform. So the fewer requests are sent to that API, the better the website performance would be. We used Blackfire.io to check how often the web app uses the API and we got interesting results. We noticed that the homepage, the most frequently visited page, used the API twice per each view. Why would a rather static page even require any API calls?

The reason was that on the homepage, there was a small sneak peek of the ranking, to engage users. There were also a couple of statistics shown, as the total number of laptops or offers analyzed. But how often did these numbers and results change? Every few hours. And how often did we calculate them? Every single page view. Huh. Adding an HTML cache for the whole homepage worked like a charm, making it just a static HTML resource, that can be served by servers in a quite effortless way.
Blackfire is a very good tool that helps to find bottlenecks. To learn more, make sure to read our recent blog post “My homepage is slowing down” in which our developer describes how he reduced page loading time by 93% in just 4 hours of work.
Step 3: learn your user's behavior and use it to plan the performance
Another optimization became easy when we analyzed data from Google Analytics. SzukamLapka generates personalized rankings based on the individual needs and preferences of the users. But according to Google Analytics, most of the users go for the predefined presets, like gaming, office, or mobile laptops. So why generate them for every user separately? Adding a Redis cache for most frequently selected rankings reduced the computations by almost 70%.
Step 4: use CDN to cache your static resources
Last but not least - we added Cloudflare. It is a service that provides an additional cache layer in front of the whole website and distributes all its static resources in CDNs. It makes the assets, like images or scripts, highly available for users, and light for the server.

Adding Cloudflare saved around 60% bandwidth traffic, making the website significantly lighter for the server. At the same time, the user experience improved thanks to the reduction of the total load time to less than 1 second! To learn more about caching with Cloudflare, check the blog post of our CTO on "Top 5 hacks to fix slow web applications".
Fast forward
Thanks to this lesson learned, the website was adjusted, and right now can handle a significantly large number of users. After a few years SzukamLapka is playing an important role in consumer decision making in Poland, generating millions in revenue for its partners. This year, SzukamLapka is launching its global version in multiple countries around the world. Thanks to the lessons learned, it is prepared to become popular in the new markets.

How about your web application?
The story of the SzukamLapka startup can happen to almost every online business. If you want to check how your web application can be hardened just drop me a message. At Accesto we look after, monitor, and improve web applications to make sure they are secure, scalable, and ready for growth.

Top comments (0)