
Checkout the new npm package!
This simple solution just got easier! I also added some upgrades like the ability to adjusted the size of the range mid stream! Now you can speed up and slow down at will!
https://www.npmjs.com/package/s3-readstream
You can use this package as a drop in replacement for AWS.S3.getObject().createReadStream()!
Original Blog
AWS s3 SDK and NodeJS read/write streams makes it easy to download files from an AWS bucket. However, what if you wanted to stream the files instead?
Before we begin
I am assuming you have used AWS s3 SDK to download files successfully and are now wanting to convert that functionality to a proper stream. As such, I will omit the AWS implementation and instead show a simple example of how, and where, to instantiate this "smart stream" class.
I am also assuming you have a (basic) understanding of NodeJS and NodeJS read/write streams.
The pipe dream
I know that pun was bad, but it's the only one in the article so work with me.
The first solution you will probably come across when implementing your stream (and why I decided to write this article) is to simply take the read stream created off your S3 instance and plug that guy where you need it. Boom streaming!
...not so fast.
There is a timeout on connections to an AWS s3 instance set to 120000ms (2 minutes). Unless you have very small files, this just won't cut it for streaming.
One option is to simply raise that timeout, but then how much should you raise it? Since the timeout is for the total time a connection can last; you would have to either make the timeout some ridiculous amount, or guess how long it will take to stream the file and update the timeout accordingly. This is also not taking into account the stream closing due to HTTP(S)'s own timeout reasons as well.
Bite by Byte
I'm sorry. It was right there... I had too!
Timeouts are not the only things that can cause you problems, there's latency too. You can't be certain that your stream isn't going to slow to a crawl in the middle of it, and everyone hates waiting for the buffer (if you should so choose to stream video). Although this problem can't be solved outright, you can make it a lot easier on yourself.
Instead of just connecting a hose and feeding the beast, you can use a "smart stream" that fetches a range of data in a single request. Grabbing data as you need it can help you avoid latency, while also keeping you away from those nasty timeouts.
Smart Streaming
The idea is to create a stream that uses the power of AWS s3
ability to grab a range of data with a single request. We can then grab another range of data with a new request and so on. This stream will pause when its buffer is full, only requesting new data on an as needed basis. This allows us to take all the time we need to process the data (or pause the video, in the middle of it, to go to the bathroom). When the process is done (and hands are washed), it picks right back up where it left off and the show goes on.
Put your darkest shades on, you're in!
Instead of making guesses and fighting random bugs, we can make use of the NodeJS Stream API and create our very own custom readable stream.
We will start by creating the "smart stream" class:
import {Readable, ReadableOptions} from 'stream';
import type {S3} from 'aws-sdk';
export class SmartStream extends Readable {
_currentCursorPosition = 0; // Holds the current starting position for our range queries
_s3DataRange = 64 * 1024; // Amount of bytes to grab
_maxContentLength: number; // Total number of bites in the file
_s3: S3; // AWS.S3 instance
_s3StreamParams: S3.GetObjectRequest; // Parameters passed into s3.getObject method
constructor(
parameters: S3.GetObjectRequest,
s3: S3,
maxLength: number,
// You can pass any ReadableStream options to the NodeJS Readable super class here
// For this example we wont use this, however I left it in to be more robust
nodeReadableStreamOptions?: ReadableOptions
) {
super(nodeReadableStreamOptions);
this._maxContentLength = maxLength;
this._s3 = s3;
this._s3StreamParams = parameters;
}
_read() {
if (this._currentCursorPosition > this._maxContentLength) {
// If the current position is greater than the amount of bytes in the file
// We push null into the buffer, NodeJS ReadableStream will see this as the end of file (EOF) and emit the 'end' event
this.push(null);
} else {
// Calculate the range of bytes we want to grab
const range = this._currentCursorPosition + this._s3DataRange;
// If the range is greater than the total number of bytes in the file
// We adjust the range to grab the remaining bytes of data
const adjustedRange = range < this._maxContentLength ? range : this._maxContentLength;
// Set the Range property on our s3 stream parameters
this._s3StreamParams.Range = `bytes=${this._currentCursorPosition}-${adjustedRange}`;
// Update the current range beginning for the next go
this._currentCursorPosition = adjustedRange + 1;
// Grab the range of bytes from the file
this._s3.getObject(this._s3StreamParams, (error, data) => {
if (error) {
// If we encounter an error grabbing the bytes
// We destroy the stream, NodeJS ReadableStream will emit the 'error' event
this.destroy(error);
} else {
// We push the data into the stream buffer
this.push(data.Body);
}
});
}
}
}
Let's break this down a bit
We are extending the Readable class from the NodeJS Stream API to add some functionality needed to implement our "smart stream". I have placed underscores (_) before some of the properties to separate our custom implementation from functionality we get, right out of the box, from the Readable super class.
The Readable class has a buffer that we can push data in too. Once this buffer is full, we stop requesting more data from our AWS s3 instance and instead push the data to another stream (or where ever we want the data to go). When we have room in the buffer, we make another request to grab a range of bites. We repeat this until the entire file is read.
The beauty of this simple implementation is that you have access to all of the event listeners and functionality you would expect from a NodeJS readStream. You can even pipe this stream into 'gzip' and stream zipped files!
Now that we have the SmartStream class coded, we are ready to wire it into a program.
Implementing with AWS S3
For this next part, as I am assuming you understand the AWS s3 SDK, I am simply going to offer an example of how to establish the stream.
import {SmartStream} from <Path to SmartStream file>;
export async function createAWSStream(): Promise<SmartStream> {
return new Promise((resolve, reject) => {
const bucketParams = {
Bucket: <Your Bucket>,
Key: <Your Key>
}
try {
const s3 = resolveS3Instance();
s3.headObject(bucketParams, (error, data) => {
if (error) {
throw error;
}
// After getting the data we want from the call to s3.headObject
// We have everything we need to instantiate our SmartStream class
// If you want to pass ReadableOptions to the Readable class, you pass the object as the fourth parameter
const stream = new SmartStream(bucketParams, s3, data.ContentLength);
resolve(stream);
});
} catch (error) {
reject(error)
}
});
}
You can check this out in an HD video streaming app on my github!
The most simple HD video streaming app
Thank you for reading! If you liked this blog let me know in the comments below!
Further Reading
This is only one example of the amazing things you can do with the NodeJS standard Stream API. For further reading checkout the NodeJS Stream API docs!

Top comments (17)
I had some trouble getting this to work with AWS SDK v3 (
@aws-sdk/s3-client). To be precise, I always got an error in this line:The error message told me, that
data.Bodyis of typehttp.IncomingMessagewhich cannot be used as an argument forpush.After some trial and error I found a solution which works for me, maybe this helps someone who is facing a similar problem.
Note that I moved the
s3.headObjectcall into theS3DownloadStreamclass, so the usage of this class is a little different from the article:Nice! Yeah a major version change would bring in some breaking changes.
Awesome!
Thanks for sharing, what would be the best way to send the transfer progress percentage to the browser client?
Thank you for the question!
Since the SmartStream class is just like any NodeJS readStream, you can throw a 'data' event handler on it.
You can then store the
data.ContentLengthvalue returned from thes3.headObjectcall and subtract the chunk length returned from the 'data' event. You can use this value to determine how much data is left, which you can then send to the frontend.The neat thing about NodeJS streams is all of this can be done without editing the SmartStream class!
Thanks for reading and let me know if I can help any more!
sure, but how would you send this information to a client browser, using websockets?, I'm trying to use fetch streams for its simplicity but they don't work very well for me.
fetch-upload-streaming
You can pipe this stream into the response from a http request. I found this article in a quick search that might help. Anywhere you see a
fs.createReadStreamyou can substitute in this readStream!There are numerous ways, including websockets, that this can be done. I would have to put in more research. If this article gets enough traction I could do a part 2 where I send the data to a frontend.
I ended up making an extremely simple front end, not sure if it will help in your case, but it might be a good starting point. You can fork it from my github if you like.
github.com/about14sheep/awsstreaming
I couldn't understand the calculations entirely can u please make me understand?
Since 64kb is _s3DataRange, S3 file size is let's say 128kb, then u will fetch first 64kb
But when modifying the S3StreamParams Range its caculated as bytes = -64kb ( in minus)
That's bit strange for me understand.
My second question is on next iteration it will start from 65th KB. Where exactly this iteration begins? There's no loop here that instructs it to keep repeating till completion of last bit In 128kb file.
For your first question, the Range parameter isn't a calculation. So the (-) hyphen there can be read as, 'grab a range of bytes starting at byte 65(up too)128'. So it wouldn't be negative.
Your second questions is really good. This is where the simplicity of NodeJS Readable Stream API comes in. When this stream is in the
data flowingmode, it will call the_read()method whenever there is room in the buffer (and the stream is not paused). So you don't need to write in a loop, the super classReadablehandles all this for you!Hope this helps! If you have any other questions please let me know!
How can we handle seeking of the video?
I have created a simple video element but I am not able to seek video. Is there anything we have to do in
S3DownloadStreamclass to make it work?I am using Next.js for UI.
@about14sheep
That would need to be handled on the frontend. Once the S3DownloadStream grabs a range, it just pushes it through to the output. Seeking would be handled by the video player
Great guide on using the NodeJS Stream API with AWS S3! I’ve been exploring similar solutions for handling live content, especially for platforms like photocall where streaming efficiency is key. This approach definitely helps with performance and scalability.
Nice
Thank you for reading!
I have added the video range in code and after that I have noticed lot's of video getting declined with out any reason t
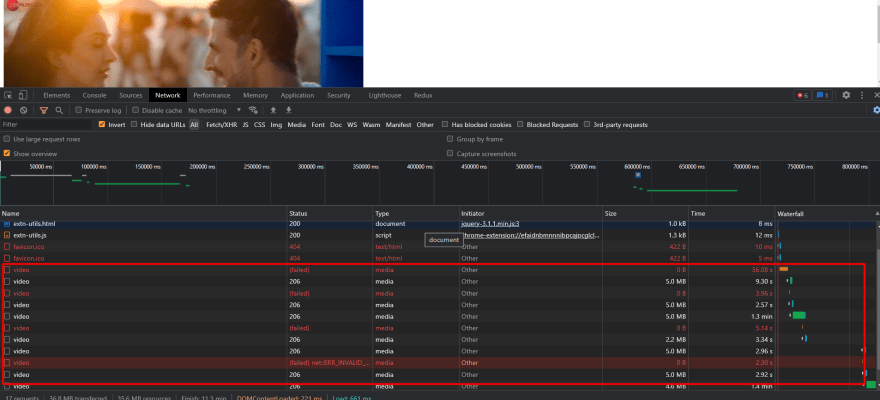
hat's why the video taking some more time to load
can you write it in js?