

Version Control System:
If we see the word Version control system, the meaning which will strike is managing different versions or tracing different versions.
For example take company Amazon or any other company, do you think the entire code of amazon is written in one go? Or one software engineer has written the entire code?
Thousands of software engineer might have contributed. Combined all those code, combining all those versions of code makes one code base of any company.
If I am the only one writing the code, there is no need to maintain the versions of code, but there will be multiple people working on a project. There will be lot of challenges that we may face like
• Conflicts can happen
• Sync problems can happen (One engineer can be working on latest version & another may be working on old version of codebase. While merging both of their commits to the Master branch we will face the problems due to different versions of code base)
Assume that in a project there are 4 versions of code base V1, V2, V3, V4. Let us think about a scenario to move from V4 to V3 (previous version)?
Whenever we get a bug in the production, first thing we check for is what the code changes are made or database changes made in the last few days. If we found out until version V3, the code was functioning properly and there is a bug surfaced now. So we might have missed something like testing or any other think for version V4.
To fix the BUG we can rollback to previous version V3 and continue working on BUG. This is the reason to maintain the history of the project.
Another reason for version control system is to maintain all the code changes done by all the team members, so that in future any bug comes they might approach the person who worked on developing the code to get more details about the feature that he has developed.
Types of Version control system
Centralized VCS: Single server that maintains the complete history of codebase.
• One need to be connected to the server all the time.
• If something happens to the server like server crash etc., then we cannot access codebase or we cannot add or modify the code base. This scenario is called as "Single point of failure"
Example:- Any file on shared server
Distributed VCS: Allows people to work independently offline, no need to connect to the server all the time
• People working on codebase should download codebase to their local machines.
• No "Single point of failure" scenario occurs as the codebase is spread across the local machines
We will discuss about Git as example for Distributed version control system.
• Git - Version control system to track changes
• GitHub - Central repository to host codebase.
With Git we can manage changes to files overtime and you can come back and see what the changes are made. We can see the difference between the versions of codebase and we can view who changed what.
Let us discuss how we can use git by using all its features.
There are 4 git locations
• Working tree - Contains location of local repo. All brand new files added into the project are called "untracked files" & edited files are called "Modified files" in local.
• Staging Area - Sort of filtering zone. Suppose there are 5 files I am working on & I want commit only 2, then only 2 will be moved from working tree to Staging area. Files here are called as staged files
Command to move files from working tree to staging
** git add file1 file2**
Command to move files from Staging area to local git repo –
** git commit -m "message for commit”**
• Local git repo - Files will be saved to git repo locally here after committing
Command to move files from local git repo to remote git repo
** git push origin **
**_But in the above command what is origin?_**
Suppose we have a local project that we want to host on
multiple remote service providers like GitHub, GitLab. I
create repository in GitHub & GitLab.
Now using Git I want to connect to multiple repositories on
different service providers.
GitHub & GitLab give us a link after creating repository
there. The link is the identifier.
Typing the link to connect to remote repo like GitHub or
GitLab is difficult because we have to type in the entire URL.
What we do is we maintain a map in Git for mapping the link.
Example: name is origin & value is "link of GitHub remote
repo"
To map this we have command – git remote add origin "link of GitHub remote repo
Note: Any name we can give while mapping but first name should always be origin
Example: git remote origin2 "GitLab remote repo link"
"Until the above everything is in local"
•Remote git repo (GitHub, GitLab etc) - Central repository to host all codebase.
Git helps us to connect to multiple remote repo because if GitHub gets hacked & all codebase is deleted, we need to maintain some backup for codebase.
Note : "Always remember while designing, always design for failure, always be sure to lookout for failure & have a solution for that"
Let us do the hands on regarding all the above locations
- To turn any project to a local git repository we use command "git init". Now the project will be initialized to Git repository.
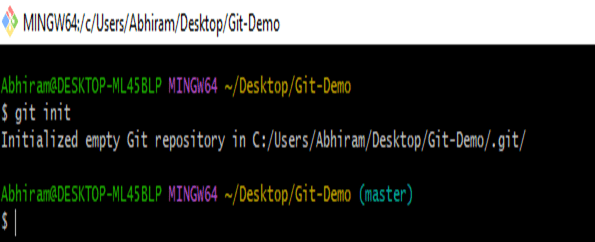
- We have to configure who is the developer for the local repo. For that we use "git config user.name --name" & "git config user.email"

- Let us create few files & we will come across all the above git locations


- Now we have created a new file & we will see which location the file is using "git status" command.

Here we can see the file is called "untracked files" present in working tree (working tree - contains location of local repo).
- Let us move from working tree to staging area using "git add ." command

- Let us see the output of " git status" command

Now we can see “Changed to be committed “which means the file is in staging area & it can be committed.
If we want to send back the file back to working tree from staging area we can see the above command in the image "git rm --cached filename"
- Command to move from staged to local repo we use " git commit -m "message" " command.

- Now if we see git status

- Let us add one more file & let us modify the first file.



- Let us view the git status

- We can see first file is modified & second file is untracked. Now we will move both of them to staging area and we will commit them.

- Let us view the status



Now copy the link of new repo created in GitHub
- Let us connect local repo to remote repo create din GitHub using " git remote add origin "remote repo link" "

- Let us modify the first file again & let us not commit it & we will see if the changes will be reflected or not in remote repo.

- Let us view the status now

- Let us not commit this change, let us push these to remote repo.

- In GitHub if we go to the commits section, but you can see in the first page that the change that we did not commit is not getting reflected. So it did not get pushed to remote repo.


Let us discuss git branches now.
Suppose we have some code & we have deployed it on one server. Now we want to add one more feature we cannot directly modify the code which is running on the server.
Another idea what we can do is get a copy of the code, make changes and replace the code with the copy but the problem is we may face some bugs which did not identify and we may lose some history of the codebase.
To solve this git gives us branches with which we can maintain multiple replicas of code.
- We will use " git branch "branchName " command to create branch. If we use git branch we can see which branch we are using.


- Now if we see the branches we have 2 branches but we are still on master branch. Now will switch to feature 1 branch using " git checkout " command

- But the interesting part we will see now is by using "git status" command. Here we can see the first file is modified as feature1 is new branch.

We can use " git merge " to merge the branch with master
We will create a new branch and we will create one more file but will push a new branch to remote repo & we will create pull request.


- After pushing our branch to remote repo, we will create pull request. We can write the changes that we have made and the changes will be displayed to us. Through this the branch will merged to master in remote repo.

- The thing that we must remember is we should not merge directly to master branch, every time we have to raise a pull request.

Top comments (0)