This is a sponsored blog post by Proxycrawl. All reviews and opinions expressed here are, however, based on my personal experience.
Video walk through: https://www.youtube.com/watch?v=f3cq69lBqAA
Proxycrawl is where we are going today. It has a very robust set of tools for web scrapers and anyone trying to get access to web data in an automated fashion. I’m REALLY excited to share some of the awesome features. You can read more about Proxycrawl crawling tools here.
Proxies

Oh proxies. I spent the first several years of my web scraping life not being able to afford to use them. Now I can’t afford not to use them.
The thing about proxies for me is that it almost seemed like an offense to use them. If I used them then I was failing as a web scraper. I should be able to find creative ways around whatever is preventing me from scraping that website.
Now, while I still try to be creative in how I am scraping websites, it’s just too much saved time and mental energy to use a proxy. Proxycrawl exemplifies that. It’s robust AND incredibly easy to use. Let’s go.
Proxycrawl is fast

Two kinds of fast.
First? Fast to get started. This screenshot I took from their website really shows how simple it is.
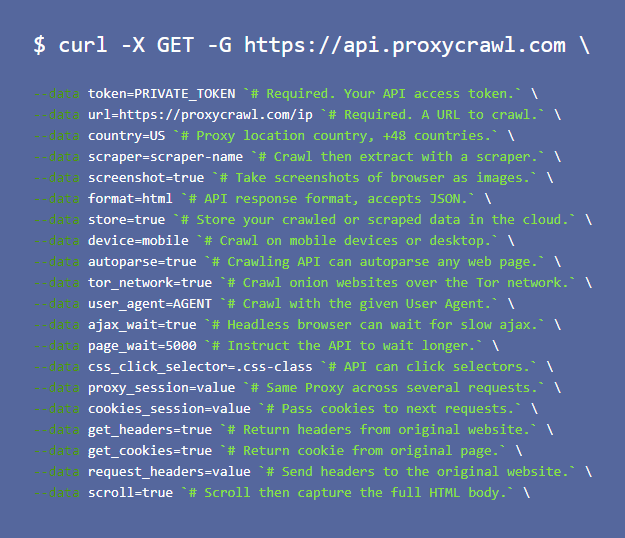
There are your parameters. Add them and it just works. The top items are required, as shown there. The rest is just more robust stuff that you can do. Screenshot, save your proxy session, specific country from which you want your requests to come. It’s all there.
I really didn’t need much more detail than this but in case you do, Proxycrawl has you covered. See their documentation.
Second kind of fast? The requests!
I was very surprised with how fast it was. Proxies have to be slower by default. They are taking more hops to get to your destination. I’ve used other proxies that added 10-15 seconds per request but Proxycrawl added only ~2 seconds. See the time checks.
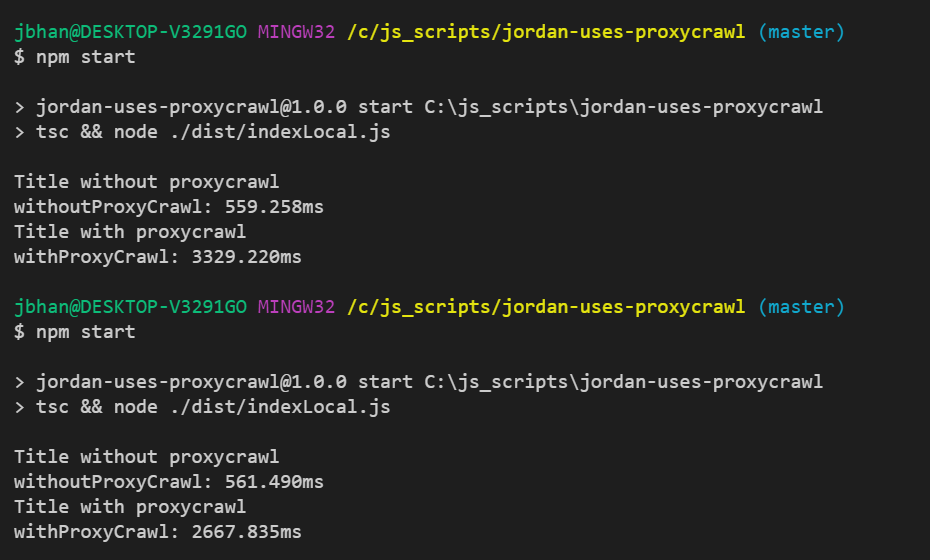
In this example I was going to javascriptwebscrapingguy.com with and without Proxycrawl. See the code here:
// Speed test
try {
console.time('withoutProxyCrawl');
await jsWebScrapingGuy();
console.timeEnd('withoutProxyCrawl');
}
catch (e) {
console.log('An error when trying to call jsWebScrapingGuy', e);
}
try {
console.time('withProxyCrawl');
await jsWebScrapingGuyWithProxyCrawl();
console.timeEnd('withProxyCrawl');
}
catch (e) {
console.log('An error when trying to call jsWebScrapingGuyWithProxyCrawl', e);
}
export async function jsWebScrapingGuy() {
const url = `https://javascriptwebscrapingguy.com/`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const title = $('title').text();
console.log('Title without proxycrawl', title);
return title;
}
export async function jsWebScrapingGuyWithProxyCrawl() {
const url = `https://api.proxycrawl.com/?token=${process.env.proxycrawlCrawlerToken}&url=https://javascriptwebscrapingguy.com/`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const title = $('title').text();
console.log('Title with proxycrawl', title);
return title;
}
Scraping tough sites. Like Google

My first test was against Google.com. I wanted to see how easy it would be to scrape Google.com. As an added check, I scraped this page https://www.google.com/search?q=what+is+my+ip.
See how clever I am? I get to see my proxied IP address AND I get to see if I was blocked or not.
export async function whatIsMyIPGoogle() {
const url = `https://www.google.com/search?q=what+is+my+ip`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const ip = $('.NEM4H.VL3Jfb.BmP5tf:nth-of-type(1) span span').text();
console.log('ip address without proxycrawl', ip);
}
export async function whatIsMyIPGoogleWithProxyCrawl() {
const url = `https://api.proxycrawl.com/?token=${process.env.proxycrawlCrawlerToken}&url=https://www.google.com/search?q=what+is+my+ip`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const ip = $('.NEM4H.VL3Jfb.BmP5tf:nth-of-type(1) span span').text();
console.log('ip address with proxycrawl', ip);
}
And my code to call them:
// Get ip address from google's what is my ip search with and without proxycrawl
try {
await whatIsMyIPGoogle();
}
catch (e) {
console.log('An error when trying to call whatIsMyIPGoogle', e);
}
try {
await whatIsMyIPGoogleWithProxyCrawl();
}
catch (e) {
console.log('An error when trying to call whatIsMyIPGoogleWithProxyCrawl', e);
}
And the results?
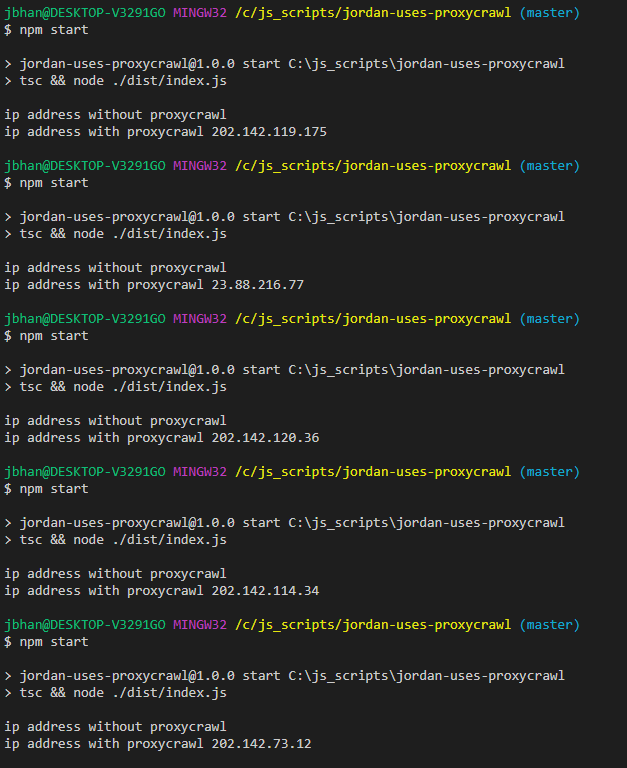
With Proxycrawl I was able to successfully scrape Google each time. Without, I was not. And Google is not a simple site to webscrape. I’ve definitely tried and they do enough to make it so painful that you don’t want to do it without a proxy.
As you can see from the code, I also added no additional things like user-agent or cookies. Proxycrawl took care of everything I needed so it just worked.
Scraping Javascript Sites

Many modern websites use javascript to render all of their data. This can make web scraping very difficult. At the time we make our request, the page has no data yet since the javascript hasn’t rendered it.
Proxycrawl has an option for this. All you have to do is use a different token in your web request and it handles it for you. I used cobaltintelligence.com as an example. I built this site and know that it uses a javascript framework (Angular).
export async function cobaltIntelligence() {
const url = `https://cobaltintelligence.com/`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const homeIntroDesc = $('.home-intro-desc').text();
console.log('homeIntroDesc without proxycrawl', homeIntroDesc);
return homeIntroDesc;
}
export async function cobaltIntelligenceWithProxyCrawl() {
const url = `https://api.proxycrawl.com/?token=${process.env.proxycrawlCrawlerJSToken}&url=https://cobaltintelligence.com/&country=us`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const homeIntroDesc = $('.home-intro-desc').text();
console.log('homeIntroDesc with proxycrawl', homeIntroDesc);
return homeIntroDesc;
}
And the code I used to invoke it:
// JS page test
try {
console.time('withoutProxyCrawl');
await cobaltIntelligence();
console.timeEnd('withoutProxyCrawl');
}
catch (e) {
console.log('An error when trying to call cobaltIntelligence', e);
}
try {
console.time('withProxyCrawl');
await cobaltIntelligenceWithProxyCrawl();
console.timeEnd('withProxyCrawl');
}
catch (e) {
console.log('An error when trying to call cobaltIntelligenceWithProxyCrawl', e);
}
The idea is that if I’m able to get some page content then I’ve succeeded. In this case I’m using a selector to pluck some random data.
Now, as expected, this takes a little bit longer than normal scraping. Waiting to ensure javascript renders is a tricky business.
Check the results.
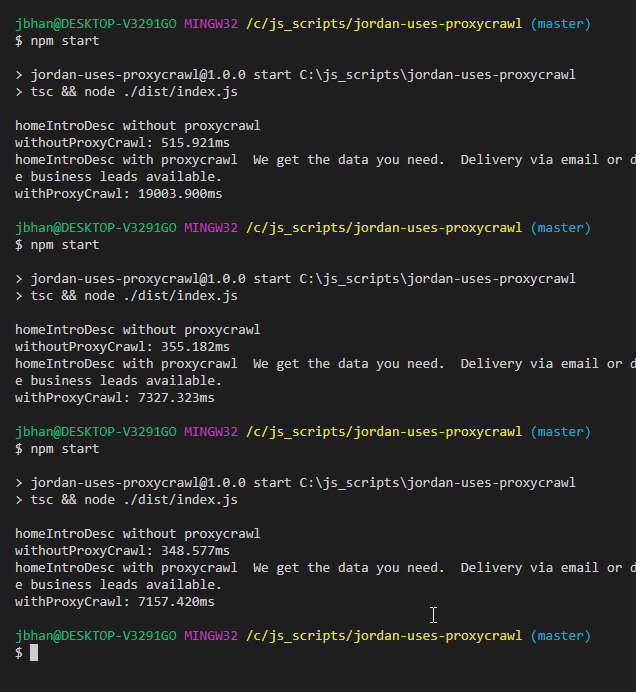
100% success rate when we use Proxycrawl to get our website data. The timing is a bit longer, like I stated above but the last two were only about ~7 seconds longer. That is pretty reasonable.
Conclusion
Proxycrawl is great. It was extremely easy to use and I can’t help but recommend it.
Check out Proxycrawl and all of their crawling tools here. This is an affiliate and if you use it, you’ll get an additional 1,000 free requests!
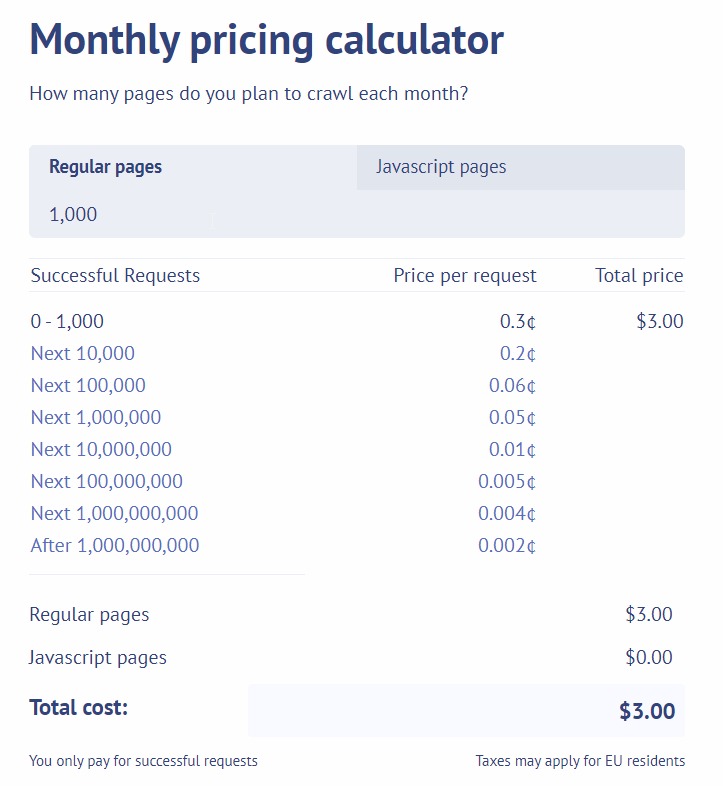
They even have this easy to use pricing calculator. It makes it very simple to understand how much it will cost you.
The post Jordan Uses Proxycrawl appeared first on Javascript Web Scraping Guy.

Top comments (0)