Web scraping Trulia. Another step in our tour around the real estate world. Last week we did a post on scraping Redfin and this post has the same goal. Get the estimated price for a specific propery.
Investigation

Scraping Trulia.com turns out to be almost exactly like scraping Redfin.com.
Two steps. We need to get the path and then we use that path to get the price.
Getting the path from an address is where we will start. We have the exact address and if we use it in the search and watch the network tab we can see the way to get the path.
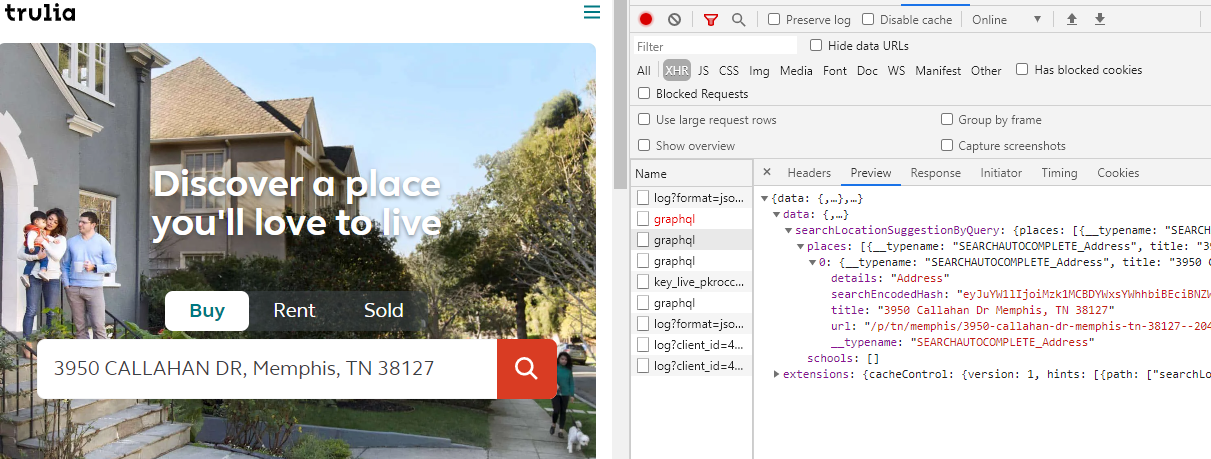
Check the results. See the url? That’s what we’re looking for!
{
"__typename": "SEARCHAUTOCOMPLETE_Address",
"title": "3950 Callahan Dr Memphis, TN 38127",
"details": "Address",
"searchEncodedHash": "eyJuYW1lIjoiMzk1MCBDYWxsYWhhbiBEciBNZW1waGlzLCBUTiAzODEyNyIsImlkIjoiMzk1MCBDYWxsYWhhbiBEciBNZW1waGlzLCBUTiAzODEyNyIsInR5cGUiOiJhZGRyZXNzIiwic3VidHlwZSI6ImFjdGl2ZV9hZGRyZXNzIiwic2NvcmUiOjE4NC41NTAyMDE0MTYwMTU2MiwicHJvcGVydHlJZCI6IjMyMDk1ODQzODIiLCJtYWxvbmVJZCI6IjIwNDEyMTU4MDgiLCJ6cGlkIjoiNDIyMjQwMDIiLCJsYXQiOjM1LjIzMzI0OTY2NDMwNjY0LCJsb24iOi04OS45ODM1MjgxMzcyMDcwMywic3RyZWV0RnVsbCI6IkNhbGxhaGFuIERyIiwiY2l0eSI6Ik1lbXBoaXMiLCJ6aXBDb2RlIjoiMzgxMjciLCJzdGF0ZSI6IlROIiwic3RyZWV0TnVtYmVyIjoiMzk1MCIsInVybFBhdGgiOiIvcC90bi9tZW1waGlzLzM5NTAtY2FsbGFoYW4tZHItbWVtcGhpcy10bi0zODEyNy0tMjA0MTIxNTgwOCJ9",
"url": "/p/tn/memphis/3950-callahan-dr-memphis-tn-38127--2041215808"
}
With that, we go to the details page. I’ve historically always looked at the XHR tab of developer tools first. But where I really should start is the Doc tab. Observe.
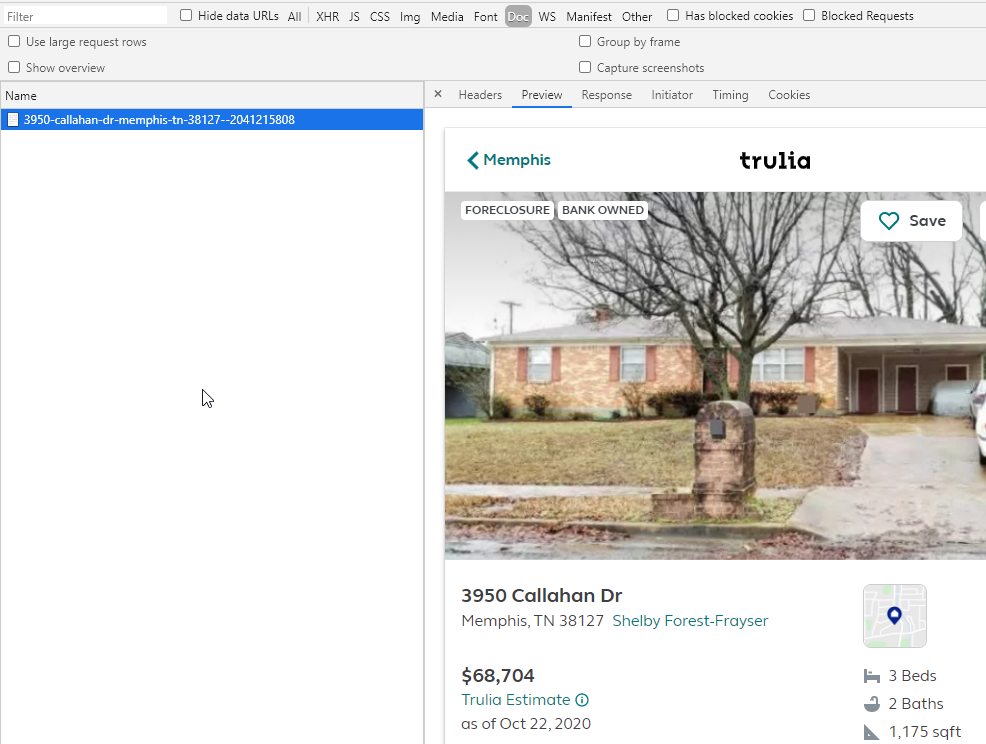
See that the data already is in the Doc means that it is very unlikely that any XHR request will return anything useful. It’s already there, rendered on the page. Why would they use an XHR request to further populate the data?
So. Here we just parse the data with cheerio (HTML parser).
The code

Two main functions. One to get the path, one to get the price.
Here is the meat of the function to get the path.
const payload = {
opeartionName: 'searchBoxAutosuggest',
variables: {
query: `${formattedStreetAddress} ${theRestOfTheAddress}`,
searchType: 'FOR_SALE'
},
query: "query searchBoxAutosuggest($query: String!, $searchType: SEARCHAUTOCOMPLETE_SearchType, $mostRecentSearchLocations: [SEARCHDETAILS_LocationInput]) {\n searchLocationSuggestionByQuery(query: $query, searchType: $searchType, mostRecentSearchLocations: $mostRecentSearchLocations) {\n places {\n __typename\n ...on SEARCHAUTOCOMPLETE_Region{ title details searchEncodedHash }\n ...on SEARCHAUTOCOMPLETE_Address { title details searchEncodedHash url }\n }\n schools { title subtitle details searchEncodedHash }\n \n }\n}"
};
const axiosResponse = await axios.post(url, payload, {
headers: {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
}
});
return axiosResponse.data?.data?.searchLocationSuggestionByQuery?.places[0]?.url;
Without adding the user-agent to the headers, it returned a 403. There is also another bit of code above this that handles the scenario where we somehow have an incorrect street name (like rd instead of st, or dr instead of rd).
It looks like this:
// Location and v are required query parameters
const splitAddress = address.split(',');
// Format the street part so we can remove the last word (hopefully rd/st/dr/etc)
// We probably should only do this if there are more than two words in the street
const splitStreetAddress = splitAddress[0].split(' ');
if (splitStreetAddress.length > 2) {
splitStreetAddress.pop();
}
const formattedStreetAddress = splitStreetAddress.join(' ');
// Get the rest of the address (city, state, and zip)
splitAddress.shift();
const theRestOfTheAddress = splitAddress.join(' ');
What it does is just pop off the last word in the string unless there are only two words (123 Fake should be left alone but 123 Fake St can lose the “St” and still return the correct path).
Here’s a video going into further detail about how this is done.
The next part just plucks the price out. It’s very simple:
async function getPrice(path: string) {
const url = `https://trulia.com${path}`;
const axiosResponse = await axios.get(url, {
headers: {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36',
'cookie': '_pxhd=8c9673c1f4056ee7a77627ded7c8d4cb1e8d42054109dcfdf672184d1e1f55d5:5b1e9741-1205-11eb-b1e9-a7e8d53ee70d; tlftmusr=201019qig7kp1lgl74u9t6o21rwpm022; zjs_user_id=null; _pxvid=5b1e9741-1205-11eb-b1e9-a7e8d53ee70d; zjs_anonymous_id=%22201019qig7kp1lgl74u9t6o21rwpm022%22; s_fid=16ED6EFD94A2BF4E-213974C00E9509F5; s_vi=[CS]v1|2FC6C22D0515A937-60000B66EC7F9CDD[CE]; QSI_S_ZN_aVrRbuAaSuA7FBz=v:0:0; _csrfSecret=DH22skBX8VMM7gABqyjqooKX; s_cc=true; g_state={"i_p":1603374232256,"i_l":1}; trul_visitTimer=1603366896615_1603367532459; OptanonConsent=isIABGlobal=false&datestamp=Thu+Oct+22+2020+05%3A52%3A12+GMT-0600+(Mountain+Daylight+Time)&version=5.8.0&landingPath=NotLandingPage&groups=1%3A1%2C0_234869%3A1%2C3%3A1%2C4%3A1%2C0_234866%3A1%2C0_234867%3A1%2C0_234868%3A1%2C0_240782%3A1%2C0_240783%3A1%2C0_240780%3A1%2C0_234871%3A1%2C0_240781%3A1%2C0_234872%3A1%2C0_234873%3A1%2C0_234874%3A1%2C0_234875%3A1%2C0_234876%3A1%2C0_234877%3A1&AwaitingReconsent=false; _px3=f7d9fac3630e1dd422e475ff793186284795bc5aa6363614943b8bf5cd2b6a73:Pj+xFCVT2i7AyMCUvgrcfd/KjikynxhMnmim3uqRqZ5niEPAyFqN54FutfRPfxD2HTFyDqD8H2ZEdAqf09CxxQ==:1000:ViYMtJksk/0GJJbGnGJz8XSWcTP+533Le6v5P9XTr+YxNhPZCBvCWNRQNkIhXCVQ+E/SJyCxiYr34P5Fir/Dv7kfgnQ72Agl8Gc+zaV5xEpeNnQ8ujJlhvYyIAsGk041Px4/k6JRjhpTIK6dhDwVHo2UEDnzpKQZ5B0I5YoBpTA='
}
});
const $ = cheerio.load(axiosResponse.data);
const price = $('[data-testid="home-details-sm-lg-xl-price-details"] .qAaUO').text();
return price;
}
You will notice that there is a huge cookie in there. A cookie AND user-agent was required for this request in order to not get a 403.
And…that’s all. We did it.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome web data. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Trulia appeared first on Javascript Web Scraping Guy.

Top comments (0)