After the beating I took last week with Delaware, I decided to go with a little bit easier target this week: Wyoming. Scraping the Wyoming Secretary of State gave some okay data but I was not able to find recent listings.
I was able to fairly easily go through a lot of different data pretty quickly and Wyoming makes it easy to tell which is listing is active. This is the fifth post in the Secretary of States series.
Investigation

Wyoming offers a simple Filing Name or Filing ID search. You can do a “Starts With” or “Contains”. It does show a nice example of the Filing ID – Example: 2000-000123456.

There is a reason, by the way, that I try to target recent listings. Often time these listings are some of the valuable listings because if they are newer businesses, they still need a lot of services, such as business insurance.
I used my trick to try and find recent listings. Often times new businesses create their name with the year in it, especially a memorable year such as 2020. So, I searched for listings containing “2020”.

This is kind of a cool thing. First of all, their results give really good high level information about the businesses. Business status, when it was orignially filed, and name. The filing ID also happens to include the year the registration was filed.
Now, for the bad news. The filing IDs aren’t sequential in any way that I can tell. It doesn’t seem to be possible to just loop through numbers and find brand new listings. The url for this results page also doesn’t seem to be anything to where we can navigate directly.
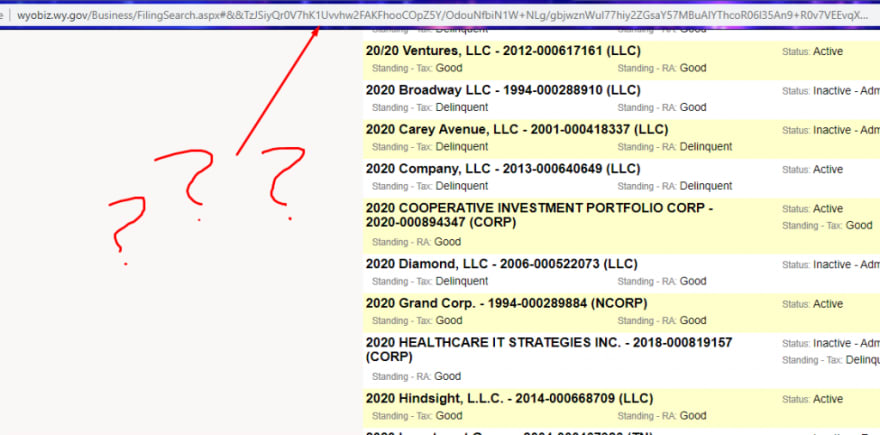
And finally, the query param for the details page has no correlation that I can discern that has anything to do with the filing ID or business. It’s likely some id that just isn’t sequential. Alright, now it’s time to use what I know and get this data.
The code

I think every one of my previous posts talk about Puppeteer OR Axios. This is one of the scenarios where I think they work really well together. Wyoming uses an asp.net form similar to what Delaware has. It leverages viewState and after hours spent unsuccessfully on Delaware’s viewState, I decided I just didn’t want to deal with it this time.
I really need to mention a GREAT comment by Chris Richardson on the Delaware post. It talks about how Chris has handled viewState in the past and it looks like a good way to approach it. Next time I encounter viewState, I’ll give it a whirl. Not today, though. Not today.
So, I use Puppeteer to submit the form and get the list of links and then I use Axios to get to those links. I use a similar strategy to what I did in Oregon and Idaho, where I just loop through the alphabet and do a “Starts With” query for each letter.
const browser = await puppeteer.launch({ headless: false });
const url = 'https://wyobiz.wy.gov/Business/FilingSearch.aspx';
for (let letter of alphabet) {
const context = await browser.createIncognitoBrowserContext();
const page = await context.newPage();
I also leverage Puppeteer’s browser.createIncognitoBrowserContext() for each iteration of the loop/letter. This way I don’t have to worry about any previous letter’s search messing with my new search. Next is getting going to the url, submitting the form with the letter from the loop and then get the number of pages.
await page.goto(url);
await page.type('#MainContent_txtFilingName', letter);
await page.click('#MainContent_cmdSearch');
await page.waitForSelector('#MainContent_lblHeaderPages');
const numberOfPages = await page.$eval('#MainContent_lblHeaderPages', element => element.textContent);
The pagination is another reason for Puppeteer here. Using Axios we’d have to do more viewState magic and post for each page. Puppeteer makes it very easy to just click the submit button and then paginate through.
With the numberOfPages, we loop through them and get the listings. In this piece of code, I just get the “Active” listings because they are generally the only ones we want for business listings.
for (let pageNumber = 1; pageNumber < parseInt(numberOfPages); pageNumber++) {
await page.waitForSelector('ol li');
const rowElements = await page.$$('ol li');
const urls: string[] = [];
for (let i = 0; i < rowElements.length; i++) {
const status = await rowElements[i].$eval('.resFile2', element => element.textContent);
if (status.includes('Active')) {
const href = await rowElements[i].$eval('a', element => element.getAttribute('href'));
const title = await rowElements[i].$eval('.resultField', element => element.textContent);
console.log('title in search screen', title);
urls.push(href);
}
}
console.log('urls', urls);
for (let i = 0; i < urls.length; i++) {
await getDetails(urls[i]);
}
await page.click('#MainContent_lbtnNextHeader');
}
The really nice thing about this scrape (and it seems that many asp.net pages share this) is that the selectors are very easy. They use ids for almost everything and it just makes it so easy to grab the things you want. We get the list of urls that contain “Active” (note that I use the uppercase “Active” so that it doesn’t get confused with “Inactive”). The url that I’m plucking looks like this:
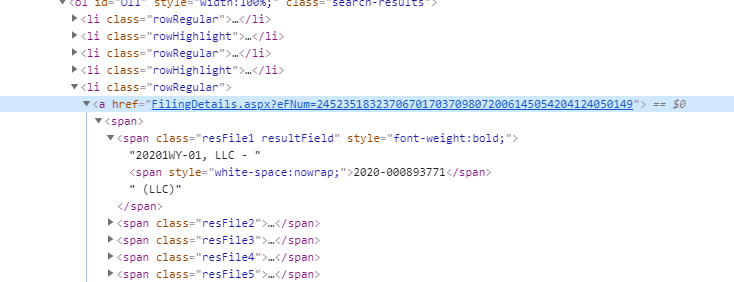
With those urls, I navigate directly to the page with Axios.
export async function getDetails(href: string) {
const baseUrl = 'https://wyobiz.wy.gov/Business/';
const axiosResponse = await axios.get(`${baseUrl}${href}`);
const $ = cheerio.load(axiosResponse.data);
const name = $('#txtFilingName2').text();
const address = $('#txtOfficeAddresss').text();
console.log('name, address', name, address);
}
That is pretty much it. I only grab the name and address here but the other ones are, like I said, very easy to pick out with good CSS selectors.
It should be noted that in the code where I get the urls above, I call the getDetails function with await. This will definitely slow down the scrape, as it’s going to block for all of the urls we call with axios, in order, instead of taking advantage of the multi-threaded I/O nature. This is intentional, since I don’t want to overload their site. I’m not a monster.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of States: Wyoming appeared first on JavaScript Web Scraping Guy.

Top comments (0)