….kind of.
Delaware. Oh, Delaware. Where I was really proud of what I was able to do with the California Secretary of State scrape, I’m almost ashamed of this piece of code with Delaware. This post is part of the Secretary of State scraping series.
Delaware

Delaware is the target for today. The goal is to try and get business listings, preferrably as they get registered or at least with some sort of ability to get a time range. Good news: This goal was mostly accomplished. Bad news: It’s so painful in the time it takes and the potential cost to possibly not be worth it.
Delaware is a special state for businesses. It treats corporations very favorably and has really, really tried hard to make it an appealing place to register your corporation. According to this article more than 50% of publicly traded companies and more than 60% of Fortune 500 companies are incorporated in Delaware. That’s a lot for one state.
This naturally means it’s be a good location for us to target in order to get business listings. Delaware has, whether intentionally or not, made this an incredibly painful process.
How it works

Below is the search form that Delaware offers. Pretty basic, with a captcha. No date range search. The fact that there is a file number is promising. As discussed in the California scrape, file numbers are generally in numerical order, with the bigger numbers being the most recent. This is really the only bright spot of this whole scrape.
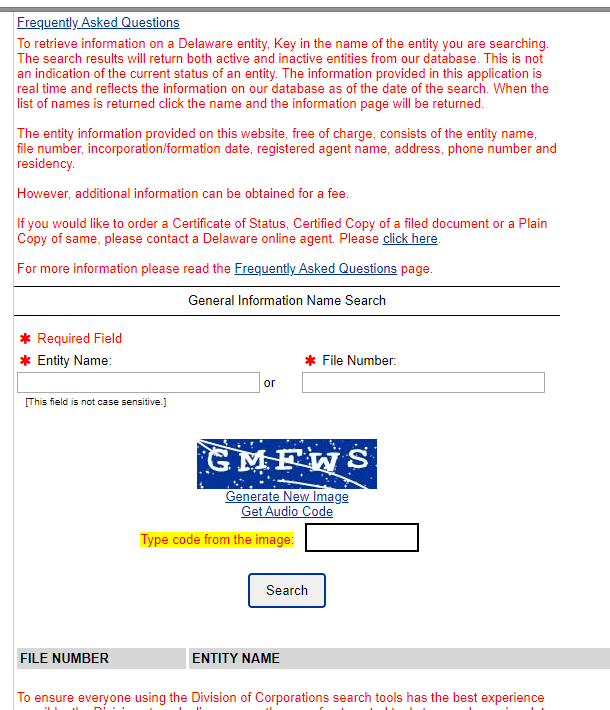
Now for the bad news, and the rest of it is pretty bad. The captcha is required for every search. A lot of times sites will use captchas to verify you aren’t a robot and then once you’ve verified, you’re good to go for pretty much the rest of your session.
Not Delaware. I’m quite sure that this part is intentional. Delaware knows the treasure trove it’s sitting on and is going to protect it. They also charge for more information, such as whether the company is active or not. Honestly, I can’t blame them. Good job, Delaware. They meet the requirements of having business registration public and are able to monetize the rest.
Searching by entity name also only returns 50 results, maximum. Of who knows how many. So if you wanted to just index a whole bunch of the records, it’d be a lot of captchas and a lot of time.
What didn’t work

With all of the other states I’ve scraped, I used axios. While I’ve made it clear that I really, really like puppeteer I typically try to start with axios. It’s going to be quicker than a headless browser and it’s normally very simple since you don’t have to worry about timing.
I really put in probably 3-4 hours trying axios but I just could not get it to work properly. I still feel like I could have gotten it to work with more time but at same point you just have to cut your losses and make something that works.
The site uses viewState for session management. I’ve done a little bit of asp.net but not enough to really understand fully how it works. I believe the basic idea of how I’m pretty sure the forms are designed to work is something like this:
Entity search page -> Contains viewstate as a hidden field, specific to this session. Submitting the form requires the entity number (or name), the captcha, and the viewstate. This POSTs to the same page, just with the fields above.
Entity search page with results -> Page with results at the bottom from the search performed above. Clicking on an entity POSTs the form again but this time with different parmeters, which gives the details on the entity you are searching for. The form POSTs with another viewState and some other fields that tell it to return the entity data.
Well…it didn’t work. I couldn’t get the correct viewState with the correct cookie and whatever. I’m not sure. Maybe someone who reads this will know exactly what I’m doing wrong and can explain it better. I left the code I was using with axios in there. You can find it here.
The final code

Puppeteer was what I ended up using, like I said above. It’s not overly complicated. The selectors were easy, just ids, so I won’t go into that.
Part that worked the best was handling the captcha. I mention how to avoid reCaptchas in another post and there was some criticism about me suggesting using a service to handle captchas. Well, I still stand by that service. It’s an affiliate link but man it’s so inexpensive that it’s crazy good. I used maybe $.30 working on this code. It’s $.85 per 1,000 captchas. 2Captcha. I mean, also, at this price, you can’t really think I’m making bundles (or anything) off of this, can you? I loaded 2Captcha with $10, have used it quite a bit and I still am at $9.64. It’s a good product.
Okay, first we go to the site, input the form information with the solved captcha and then click the button.
const page = await browser.newPage();
const url = 'https://icis.corp.delaware.gov/Ecorp/EntitySearch/NameSearch.aspx';
await page.setViewport({ width: 900, height: 900 });
await page.goto(url);
let captchaUrl = await page.$eval('#ctl00_ContentPlaceHolder1_ctl05_RadCaptcha1_CaptchaImageUP', element => element.getAttribute('src'));
captchaUrl = captchaUrl.replace('..', 'https://icis.corp.delaware.gov/Ecorp');
const captchaResponse = await client.decode({
url: captchaUrl
});
await page.type('#ctl00_ContentPlaceHolder1_frmFileNumber', entityNumber.toString());
await page.type('#ctl00_ContentPlaceHolder1_ctl05_rcTextBox1', captchaResponse._text);
await page.click('#ctl00_ContentPlaceHolder1_btnSubmit');
Pretty simple. Downfall is the captcha solving takes a bit of time so you can’t really cruise through these listings. I’d guess 5-10 seconds each. And we’re only getting one listing per search so that really is prohibitive to getting a large amount of listings.
We had to handle error scenarios as well. Delaware had HUGE chunks of data missing. So while entity number 7861148 had a listing, there were huge chunks of numbers before then that were empty. See below. It made it really hard to find where the valid numbers were. This is me skipping 100 entities at a time.
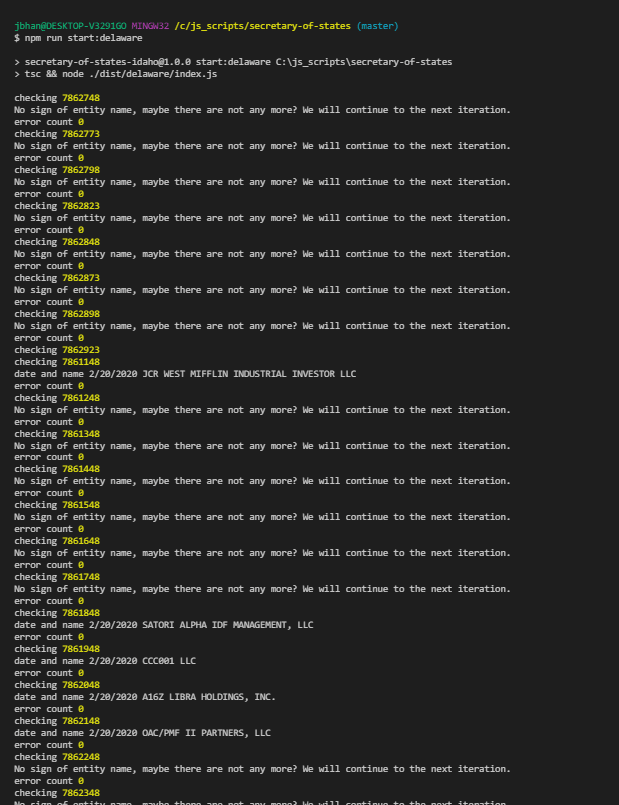
So I put some basic error handling in there to handle if there were no results or if we happened to get a bad captcha value.
// Captcha failure error
try {
const errorMessage = await page.$eval('#ctl00_ContentPlaceHolder1_lblErrorMessage', element => element.textContent, 750);
console.log('we possibly got the captcha wrong, we will try again', errorMessage);
if (errorMessage) {
await page.close();
return await getDelaware(browser, entityNumber, errorCount);
}
}
catch (e) {
}
try {
await page.waitForSelector('#ctl00_ContentPlaceHolder1_rptSearchResults_ctl00_lnkbtnEntityName', { timeout: 750 });
}
catch (e) {
console.log('No sign of entity name, maybe there are not any more? We will continue to the next iteration.');
errorCount = errorCount++;
return await page.close();
}
Then, we have the results. I just grabbed the name and date here but you could easily grab whatever you wanted.
await page.click('#ctl00_ContentPlaceHolder1_rptSearchResults_ctl00_lnkbtnEntityName');
await page.waitForSelector('#ctl00_ContentPlaceHolder1_lblIncDate');
const date = await page.$eval('#ctl00_ContentPlaceHolder1_lblIncDate', element => element.textContent);
const name = await page.$eval('#ctl00_ContentPlaceHolder1_lblEntityName', element => element.textContent);
console.log('date and name', date, name);
Conclusion
As I’m scraping websites, I sometimes wonder what strategies would be the best to prevent unwanted web scraping. My typical thought is that if someone isn’t hurting my website but hitting it too much, I don’t think it’s something worth doing. The more blocks you put in to slow a web scraper, the more you compromise on your user experience and your product suffers.
Delaware is kind of a different scenario. They definitely made it difficult to scrape. If they were a business, I’d say their website is nigh unusable for finding anything but one specific business. But they aren’t. They are a state that I’m sure is legally required to make this information public. How they’ve built this, it does make the information public and they prevent people from scraping their site (well).
So, I think they did a good job of making web scraping painful enough to stop most web scrapers. I don’t think it would work in a for profit business but it works great for them.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of States: Delaware appeared first on JavaScript Web Scraping Guy.

Top comments (0)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.