I am from Idaho. In Idaho, in the fourth grade, we are supposed to pick a state and do a report on it. I was 41st (I remember this vividly for some reason) and I choose (from the remaining states) Connecticut. I remember very little about that report but now, today, I get to talk a little more about Connecticut as I scrape their secretary of state website.
The scape for this site was very, very simple. I’m going to focus a bit more on finding good CSS selectors for the data today rather than on how to get at the data with scraping. This is mostly due to the fact that getting the data was so easy. But also because finding good CSS selectors is probably one of the most overlooked part of web scraping and can be pretty tricky, especially for those not very comfortable with web scraping.
Investigation

I headed over to the Connecticut secretary of state business search and started the search. Like I’ve mentioned in other posts, I searched for “2020” hoping for a state that was registered this year using 2020 in their name. This way I can get closer to the end of their ids.
With Connecticut, searching is an exact match so it returned only one result. Luckily, Connecticut offers a wild card search!
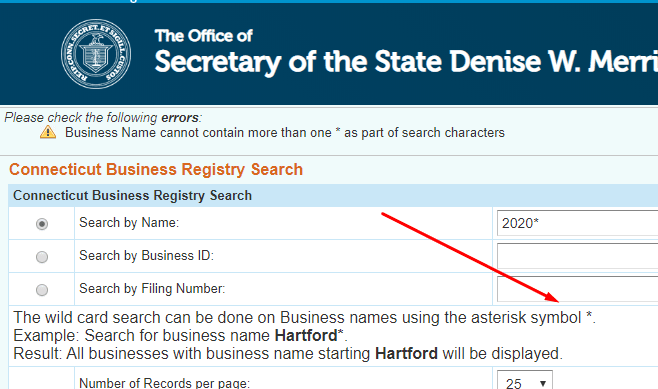
With the wild card search I was able to get a lot more results and find this business – https://www.concord-sots.ct.gov/CONCORD/PublicInquiry?eid=9744&businessID=1329345. From here, I used the trick of looping through, adding 100 to the businessID (1329345) for each iteration of the loop until I ran into the end of the businesses. This is a quick way to find where the business ids end.
This is another of the state’s that has their businessIDs incremented. It makes it very easy to find the most recently registered businesses.
CSS Selectors

Using CSS selectors when doing web scraping can be challenging. I really recommend getting familiar with all the different selectors you can use over at W3 schools. While it can be challenging, I want to make it clear that as of yet, I have never been unable to find the CSS selectors to get the data I want.
Today is a good example of while seemingly simple HTML structure can be difficult to get the unique data. Here is some sample html that is easy to select from:
<table>
<tbody>
<tr>
<td>stuff</td>
</tr>
</tbody>
</table>
Just use tr for your selector and you have your data. Now, what if I have something like this and I only want the data from the second and fourth cell?
<table>
<tbody>
<tr>
<td>stuff</td>
<td>second cell</td>
<td>stuff</td>
<td>fourth cell</td>
</tr>
</tbody>
</table>
There are no unique identifiers for those specific fields. So this time the trick that I have found the most useful is nth-of-type. Like this: td:nth-of-type(2).
CSS selecting a bit harder
Connecticut took it all to another level. Very little unique identifiers and a lot of the same structure. I’ll show an example with pictures:
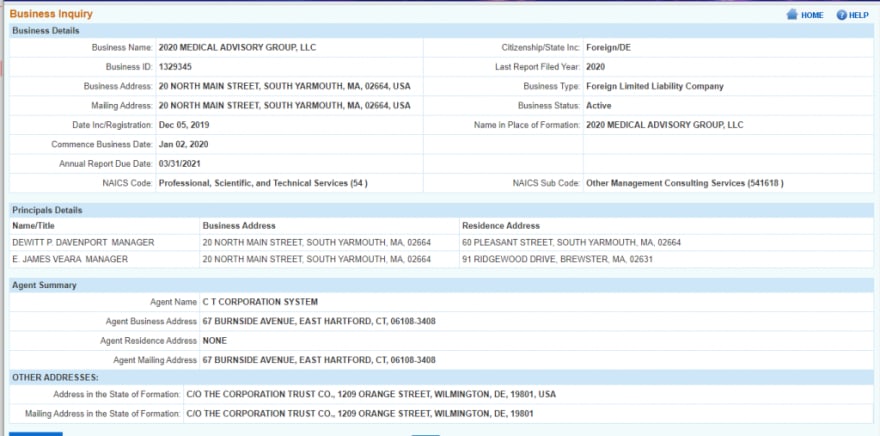
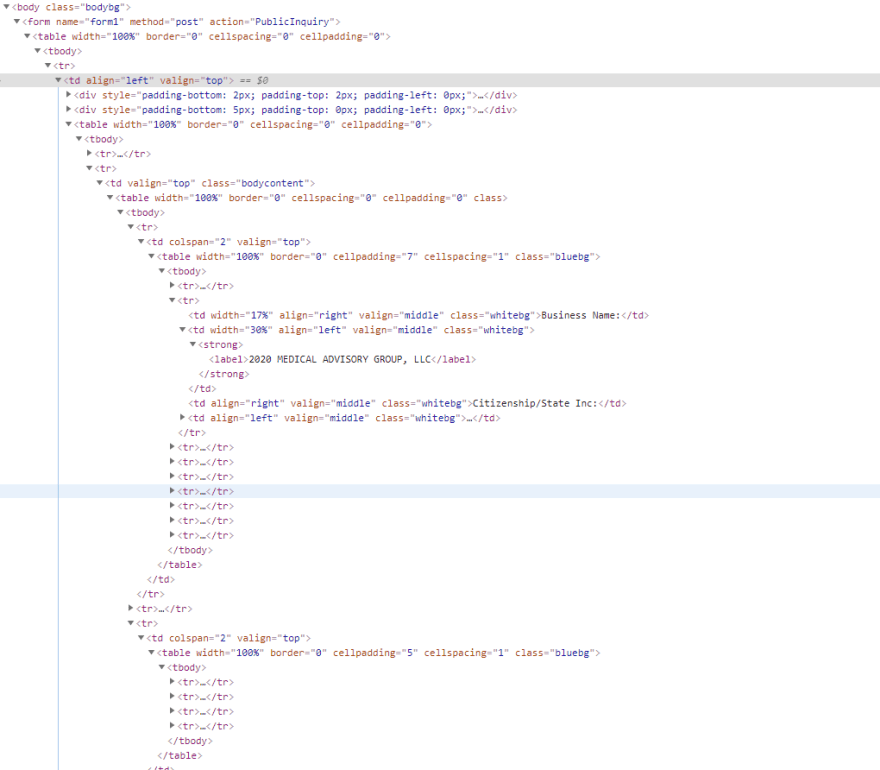
So there are really four sections that are visible with each section built as a <table>. There are also tables that are used to divide each section. If I want to select the business name, this is the piece of HTML I am looking at:

If I just use td:nth-of-type(2) here, it will select all of the times when there is a list of td and they are the second of the type. And in this, there are a lot of them, in every row. So normally I try to get a little more specific and use table tr:nth-of-type(2) td:nth-of-type(2). Well, there are a lot of those too. Tons of tables with a second row and a second cell within that second row.
If I try to use table table table table tr:nth-of-type(2) td:nth-of-type(2), which means I want the fourth child table that has a tr as a child and a td as a child of that. But because there are a bunch of tables four generations deep, this isn’t so good either.
What I had to end up relying on, and which worked really well, was using >. As the W3 documentation states, this selects the item that is the direct child of the element. The final selector looks like this:
form > table > tbody > tr > td > table > tbody > tr:nth-of-type(2) > td > table > tbody > tr:nth-of-type(1) tr:nth-of-type(2) td:nth-of-type(2)
Yeah, it’s huge. It takes direct children of direct children of direct children. This makes sure that we are at the secion that we desire and we aren’t getting convoluted with some of the many other tables. Because the table structure here was pretty uniform, I actually just built the following function.
function baseSelector(section: number, rowWithinSection: number, cellWithinRow: number) {
return `form > table > tbody > tr > td > table > tbody > tr:nth-of-type(2) > td > table > tbody > tr:nth-of-type(${section}) tr:nth-of-type(${rowWithinSection}) td:nth-of-type(${cellWithinRow})`;
}
I just pass in the section I want, along with the row and cell desired. It worked really well.
Conclusion
The final full code ending up looking like this:
async function getDetails(id: number) {
const url = `https://www.concord-sots.ct.gov/CONCORD/PublicInquiry?eid=9744&businessID=${id}`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const title = $(`${baseSelector(1, 2, 2)}`).text();
const state = $(`${baseSelector(1, 2, 4)}`).text();
const businessId = $(`${baseSelector(1, 3, 2)}`).text();
const address = $(`${baseSelector(1, 4, 2)}`).text();
const filingDate = $(`${baseSelector(1, 6, 2)}`).text();
const prinicipalName = $(`${baseSelector(3, 3, 1)}`).text();
const prinicipalBusinessAddress = $(`${baseSelector(3, 3, 2)}`).text();
const prinicipalResidenceAddress = $(`${baseSelector(3, 3, 3)}`).text();
const business = {
title: title.trim(),
state: state,
businessId: businessId,
address: address,
filingDate: filingDate,
prinicipalName: prinicipalName.trim().replace(/\s+/g, " "),
prinicipalBusinessAddress: prinicipalBusinessAddress.trim(),
prinicipalResidenceAddress: prinicipalResidenceAddress.trim()
};
console.log(business);
}
function baseSelector(section: number, rowWithinSection: number, cellWithinRow: number) {
return `form > table > tbody > tr > td > table > tbody > tr:nth-of-type(2) > td > table > tbody > tr:nth-of-type(${section}) tr:nth-of-type(${rowWithinSection}) td:nth-of-type(${cellWithinRow})`;
}
It really was a simple scrape and one I’m pretty happy with.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of States: Connecticut appeared first on JavaScript Web Scraping Guy.

Top comments (0)