Warning! Maine is quick to block IP addresses. As of writing this post, I’m still unable to visit their site from my the same IP address I originally started scraping from. If you intend on scraping Maine’s secretary of state, I recommend using a proxy service. I personally use scraperapi (affiliate link) .
Update: Looks like after two days Maine’s site is no longer blocking me. I guess the block isn’t permanent.
Updates 2: Okay, just kidding. It let me in for a second and then blocked me again.
This is my 13th post in the Secretary of State of scraping series. Maine was chosen because I opened a map of the United States and started at the top right and that was Maine.
Investigation

I try to look for the most recently registered businesses. They are the businesses that very likely are trying to get setup with new services and products and probably don’t have existing relationships. I think typically these are going to be the more valuable leads.
If the state doesn’t offer a date range with which to search, I’ve discovered a trick that works pretty okay. I just search for “2020”. 2020 is kind of a catchy number and because we are currently in that year people tend to start businesses that have that name in it.
Once I find one of these that is registered recently, I look for a business id somewhere. It’s typically a query parameter in the url or form data in the POST request. Either way, if I can increment that id by one number and still get a company that is recently registered, I know I can find recently registered business simply by increasing the id with which I search.
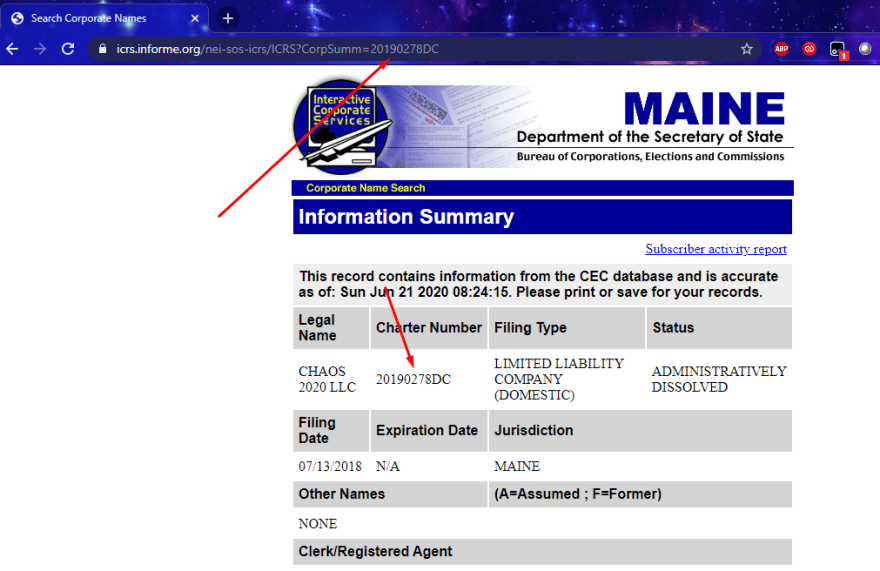
Maine was a bit different in that it had two characters appended to the end of the incrementing id. I believe DC was for someting like “Domestic Company”. It also had FC for what I believe is “Foreign Company”. Once I put this together, it was very simple to just append the type of company I wanted to the end of the id and be in business.
The code

Super simple scrape. Just loop through the ids you want and grab the information. One function for the details and then a function to loop through the ids and increment them.
(async () => {
const startingId = 20207298;
for (let i = 0; i < 20; i++) {
const business = await getDetails(startingId + i);
console.log('Business', business, startingId + i);
await timeout(5000);
}
})();
And here’s the function that gets the data from the details page:
async function getDetails(id: number) {
const url = `https://icrs.informe.org/nei-sos-icrs/ICRS?CorpSumm=${id}DC`;
const axiosResponse = await axios.get(url);
const $ = cheerio.load(axiosResponse.data);
const title = $('table > tbody > tr:nth-of-type(3) > td > table > tbody > tr:nth-of-type(5) td:nth-of-type(1)').text();
const filingDate = $('table > tbody > tr:nth-of-type(3) > td > table > tbody > tr:nth-of-type(7) td:nth-of-type(1)').text();
const agentInformation = $('table > tbody > tr:nth-of-type(3) > td > table > table > tbody > tr:nth-of-type(12) td:nth-of-type(1)').text();
const business = {
title: title,
filingDate: filingDate,
agentInformation: agentInformation
};
return business;
}
As usual, I used axios for the web requests and cheerio for the html parsing. And I literally think that may be it.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of State: Maine appeared first on JavaScript Web Scraping Guy.

Top comments (0)