17. 17th post in the Secretary of State scraping series and today we will be web scraping the Alaska secretary of state. You can find the page to start searching for businesses here.
I have been to Alaska once. It was on a cruise with my parents when I was like 15. We visited a glacier and stopped in Juneau. I thought it was crazy that Juneau, the capital, could only be accessed via plane or boat. And it was honestly just gorgeous.
Before we go any farther,
Investigation

I try to look for the most recently registered businesses. They are the businesses that very likely are trying to get setup with new services and products and probably don’t have existing relationships. I think typically these are going to be the more valuable leads.
If the state doesn’t offer a date range with which to search, I’ve discovered a trick that works pretty okay. I just search for “2020”. 2020 is kind of a catchy number and because we are currently in that year people tend to start businesses that have that name in it.
Once I find one of these that is registered recently, I look for a business id somewhere. It’s typically a query parameter in the url or form data in the POST request. Either way, if I can increment that id by one number and still get a company that is recently registered, I know I can find recently registered business simply by increasing the id with which I search.
Alaska worked this way as well. A nice thing about this one is you can sort by column. And while the sort was not really working (it looks like it’s sorting by the string instead of the number) it still helped enough that I could pluck the largest number out and sure enough, registered August 20th.
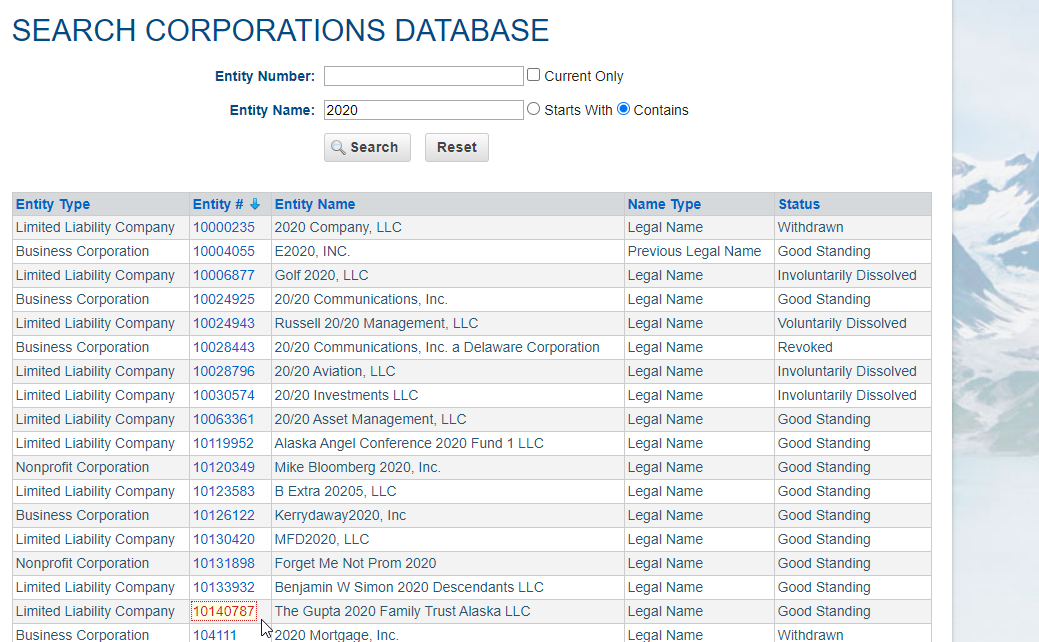
Quickly looking at the page and the url shows that it’s likely we can just make GET requests and increment the id. It also seems that we can easily pluck out the data that we’re looking for.
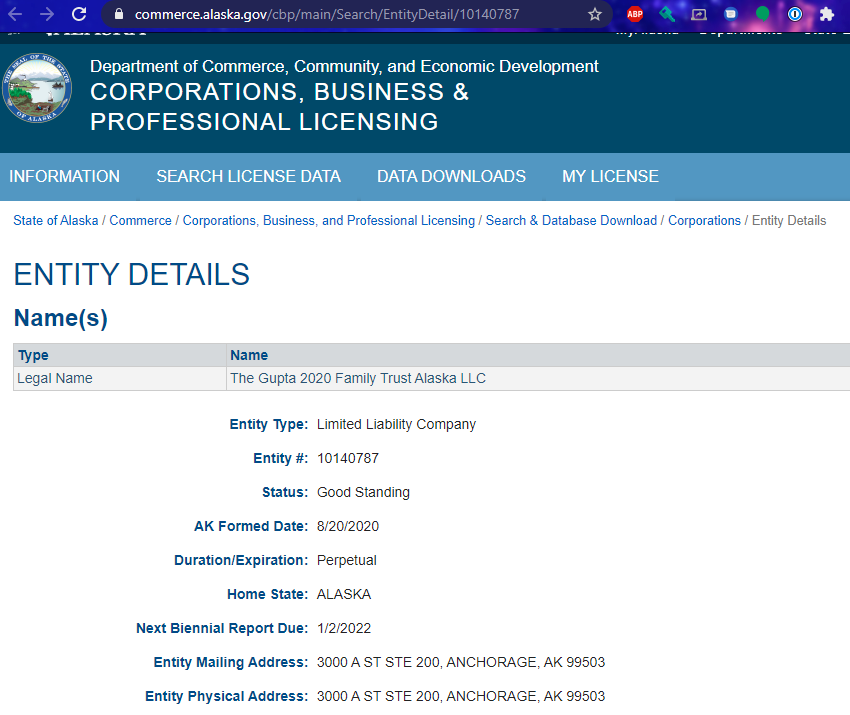
Investigation is pretty simple here so let’s go to the code.
The code

Warning: Alaska does block based on IP. Even with a 1 second timeout per request, they still blocked for a full day. Make sure to slow down your requests before doing any kind of scraping of Alaska. We’ve slowed ours down to 10 seconds between each request.
(async () => {
// Id of 10140911 starts at date of 8/21/2020
const startingId = 10140911;
for (let i = 0; i < 1000; i += 50) {
await getDetails(startingId + i);
// Needed longer than 1 sec timeout due to being IP blocked.
await timeout(10000);
}
})();
We call on Alaska using axios and it was kind of an interesting experience. If an initial http request doesn’t work without any additional headers, I typically start with “user-agent”, “cookie”, and then “origin”. Alaska required only “user-agent” and “referrer”.
headers: {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
// Neither cookie nor host was required.
// cookie: "TScf54ea41077=0890181cafab28006f32628354d352cf523378cc63639069784b9247c73d1e00d516ce4acca56ad0182231c1478e480a08e5d42c4e1720003a8ef360360de55429873b58ef7153195bc458803f992eb4ae2f45f50cd5ec02; TS00000000076=0890181cafab2800a900e3bb2c1075810764ca4d062d0881168269945bb69ad86f268c3860dce7984c4dcb6e5c9550c408ed934d4209d000f2178c6b0e403595484031cf550851dc6a41517cf4204434fb441f7923689c17055b3221df463c3359c5687140f4b69875db34433b99fb1f1f7a776f68b71b8581f6d91f6864a14dcd042d34019798c1c51bedf855cb68e133518ffb83c94c9e2c424f8c8bf6928bd9429b2a71679f084c4bc1a54915c8344aa974b51facc337a52787fb8efd8bb92678eb42d6319595dc4df1cfbacd78969137b575051b02f4ab6fadb2f76ca9de37b5710df929e08e872125c5311bf679e287df2a122e9d9a00a9c4cd0f41c42cbd9109f086bc0983; TSPD_101_DID=0890181cafab2800a900e3bb2c1075810764ca4d062d0881168269945bb69ad86f268c3860dce7984c4dcb6e5c9550c408ed934d42063800da851031b38161ee6213d0618e8c1b768a0158cdd17df5e9e572dea3059211b5a596a4959255c70ffcb61db7dd4f2c007a0169b1cda20e13; TSPD_101=0890181cafab28002fbbf9a9e5e4c77c0a8d7fcaf472145610a06e434d636b12a41145f4c4d0f14618bec011c9fe60e908f3a5e63d0518005776f8ee4dcd81c3ab1015171ce637040290eefc16315a46; TS3c5043ea027=0890181cafab200011e914c8733c1300599ca12d5744ee76ede88fe49896a67b7162201a4eaa186908e17a76781130007e2515bad27bee4104771485c1c52800a12ee9ab88d8ce7b7ecf901e33be2c6e24855cc7123867a72fc5096444b0a02e",
// host: "www.commerce.alaska.gov",
referer: "https://www.commerce.alaska.gov/cbp/main/search/entities"
}
We removed both cookie and host and neither were required. With this, we were set to scrape as we wanted. …as long as we slowed down the requests. Otherwise…BLOCKED.
The code we have here is pretty simple. It just shows an example of grabbing just the title, filing date, and sosId. Check it:
async function getDetails(sosId: number) {
// URL looks like this in the production website https://www.commerce.alaska.gov/cbp/main/Search/EntityDetail/10063361?_=1597181120369
// The query parameter was not needed.
const axiosResponse = await axios.get(`https://www.commerce.alaska.gov/cbp/main/Search/EntityDetail/${sosId}`, {
headers: {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36",
// Neither cookie nor host was required.
// cookie: "TScf54ea41077=0890181cafab28006f32628354d352cf523378cc63639069784b9247c73d1e00d516ce4acca56ad0182231c1478e480a08e5d42c4e1720003a8ef360360de55429873b58ef7153195bc458803f992eb4ae2f45f50cd5ec02; TS00000000076=0890181cafab2800a900e3bb2c1075810764ca4d062d0881168269945bb69ad86f268c3860dce7984c4dcb6e5c9550c408ed934d4209d000f2178c6b0e403595484031cf550851dc6a41517cf4204434fb441f7923689c17055b3221df463c3359c5687140f4b69875db34433b99fb1f1f7a776f68b71b8581f6d91f6864a14dcd042d34019798c1c51bedf855cb68e133518ffb83c94c9e2c424f8c8bf6928bd9429b2a71679f084c4bc1a54915c8344aa974b51facc337a52787fb8efd8bb92678eb42d6319595dc4df1cfbacd78969137b575051b02f4ab6fadb2f76ca9de37b5710df929e08e872125c5311bf679e287df2a122e9d9a00a9c4cd0f41c42cbd9109f086bc0983; TSPD_101_DID=0890181cafab2800a900e3bb2c1075810764ca4d062d0881168269945bb69ad86f268c3860dce7984c4dcb6e5c9550c408ed934d42063800da851031b38161ee6213d0618e8c1b768a0158cdd17df5e9e572dea3059211b5a596a4959255c70ffcb61db7dd4f2c007a0169b1cda20e13; TSPD_101=0890181cafab28002fbbf9a9e5e4c77c0a8d7fcaf472145610a06e434d636b12a41145f4c4d0f14618bec011c9fe60e908f3a5e63d0518005776f8ee4dcd81c3ab1015171ce637040290eefc16315a46; TS3c5043ea027=0890181cafab200011e914c8733c1300599ca12d5744ee76ede88fe49896a67b7162201a4eaa186908e17a76781130007e2515bad27bee4104771485c1c52800a12ee9ab88d8ce7b7ecf901e33be2c6e24855cc7123867a72fc5096444b0a02e",
// host: "www.commerce.alaska.gov",
referer: "https://www.commerce.alaska.gov/cbp/main/search/entities"
}
});
const $ = cheerio.load(axiosResponse.data);
const title = $("h2 + table:nth-of-type(1) tr:nth-of-type(1) td:nth-of-type(2)").text();
const filingDate = $("dl:nth-of-type(1) dd:nth-of-type(4)").text();
const business: any = {};
business.title = title;
business.filingDate = filingDate;
business.sosId = sosId;
console.log("business", business);
}
The only thing that was a little bit trickier was grabbing the business title. There wasn’t a great unique selector without using an advanced CSS selector. If you need help with advanced CSS selectors, I’d recommend our post here.
In the case here, we used the + selector, which allowed us to select the immediate next sibling.
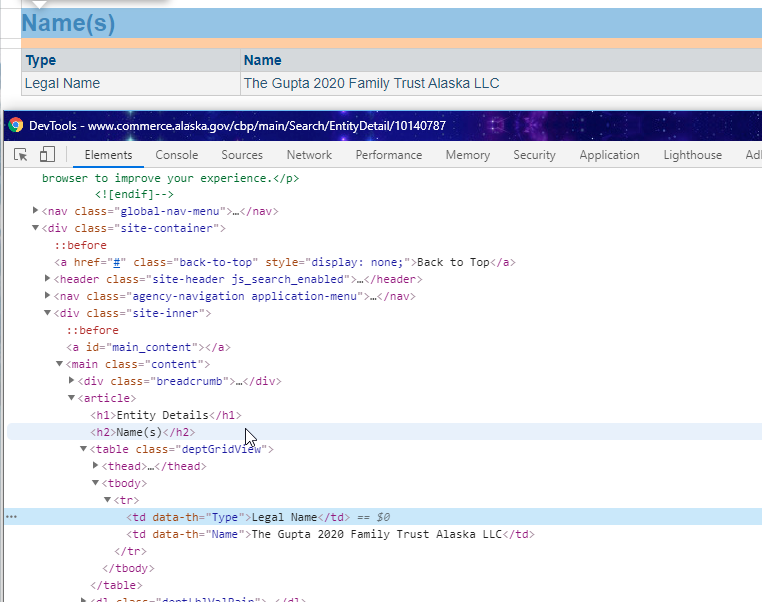
You can see how it works here. Using h2 + table ensured that we only grabbed the table with the title and not any other on the page.
And…that’s it. Alaska DONE.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome web data. Learn more at Cobalt Intelligence!
The post Jordan Scrapes Secretary of State: Alaska appeared first on JavaScript Web Scraping Guy.

Top comments (0)