This is a bit of code that scrapes the website LeanX.eu. LeanX is a vendor that helps users with their SAP databases. I know very little of SAP beyond that it is pretty serious software that is most often used for databases. This came as a request.
Investigation

The data I was scraping came from pages like this one. The goal was to pluck out all the fields for each table. The table looks like this:
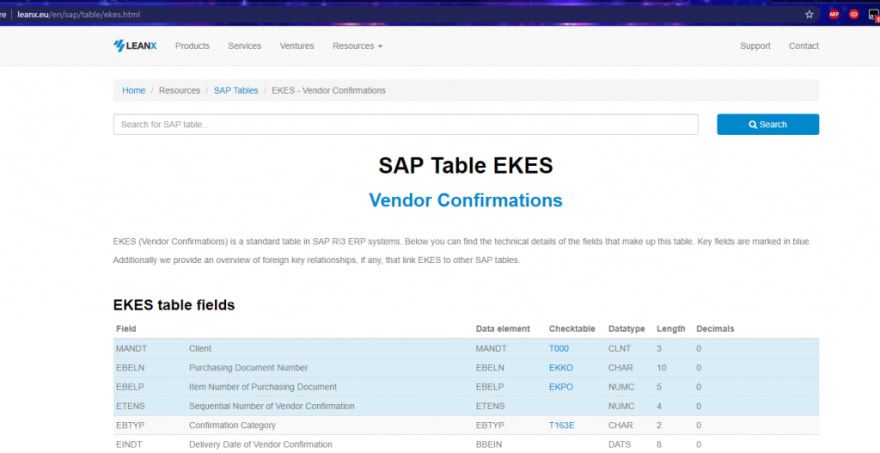
I was provided with an array of hundreds of table names, each one corresponding with a page like this. This was for the table EKES.
Looking at the HTML showed very simple table structure. I would just need to get the list of rows and then the first cell in each row had the data I was looking for.

The one caveat to this is there are occasional fields that have additional possible values and those are needed as well. You can see both the HTML and how it looks the screen here:

Each of these possible values needs to be their own row.
Alright, now we have our requirements. Let’s get into the code.
The code

The difficult part of this code was using some good CSS selectors. If you aren’t too familiar with CSS selectors I recommend my post on advanced CSS selectors.
The base function just loops through the table names, takes the output and pushes them into an array. When it completes, it saves the array to a CSV file using json2csv.
I’m only doing the first ten tables in this example with the full loop commented out. I’m also setting a basic timeout of 1 second between each loop so as not to slam LeanX.
(async () => {
const allFields: any[] = [];
// for (let i = 0; i < tableNames.length; i++) {
for (let i = 0; i < 10; i++) {
const values = await getTableValues(tableNames[i].SAP_Table);
allFields.push(...values);
console.log('values', allFields.length);
await timeout(1000);
}
const csv = json2csv.parse(allFields);
const fileName = 'Table fields.csv';
fs.writeFile(fileName, csv, (err) => {
if (err) {
console.log('error saving file', err);
}
})
})();
At first I selected the rows from the table I was looking for with this:
const rows = $('.table-responsive > table > tbody > tr');
This way I could loop through each row and then pluck the data I wanted from each one. I had a bit of trouble with this because there is actually an additional table with foreign keys that I did not want. This table had the exact same selector as the above.

I ended up using a neat little CSS combinator where I used an adjacent sibling selector. Adjacent in this case means “immediately following”. I often use nth-of-type but since you can’t use that on class selectors and trying to find the exact div I wanted was near impossible. So I just grabbed the first header of the tables I was looking for. The final selector looked like this:
const rows = $('h3:nth-of-type(1) + .table-responsive > table > tbody > tr');
The loop through the rows looks like the following:
for (let i = 0; i < rows.length; i++) {
const row$ = cheerio.load(rows[i]);
const field = row$('td:nth-of-type(1)').first().text();
const possibleValues = row$('.collapse tr');
if (possibleValues.length > 0) {
for (let possibleValueIndex = 0; possibleValueIndex < possibleValues.length; possibleValueIndex++) {
const possibleValue$ = cheerio.load(possibleValues[possibleValueIndex]);
const possibleValue = possibleValue$('td:nth-of-type(2)').text();
fieldValues.push({
table: tableName,
field: field,
value: possibleValue
});
}
}
else {
fieldValues.push({
table: tableName,
field: field,
value: field
});
}
}
The first cool part is where I just load the HTML of the individual row into cheerio and use that to easily select the data I need. The second cool part is where I check if there are any possible values that I need to check for. Fortunately the values for these fields exists in the html on page load, they are just hidden. Hidden is still very pluckable for HTML parsing.
Once I had the data and had looped through the possible values, I just dumped them into an object and then pushed them into my array. And that was it. It was a fun scrape.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Scrapes LeanX appeared first on JavaScript Web Scraping Guy.

Top comments (0)