I occasionally put out requests for web scraping targets on reddit. Today’s scrape comes as a result of that request. A user was looking to get the books listed on specific universities’ websites along with prices and other information.
This scrape definitely stretched me. There were a couple of difficulties that I’ll address later in the post but this all was a lot of fun. Really good challenges forces me to think of creative ways with which to solve them.
Getting the courses

This was my starting point. I won’t lie that it was definitely a bit intimidating.
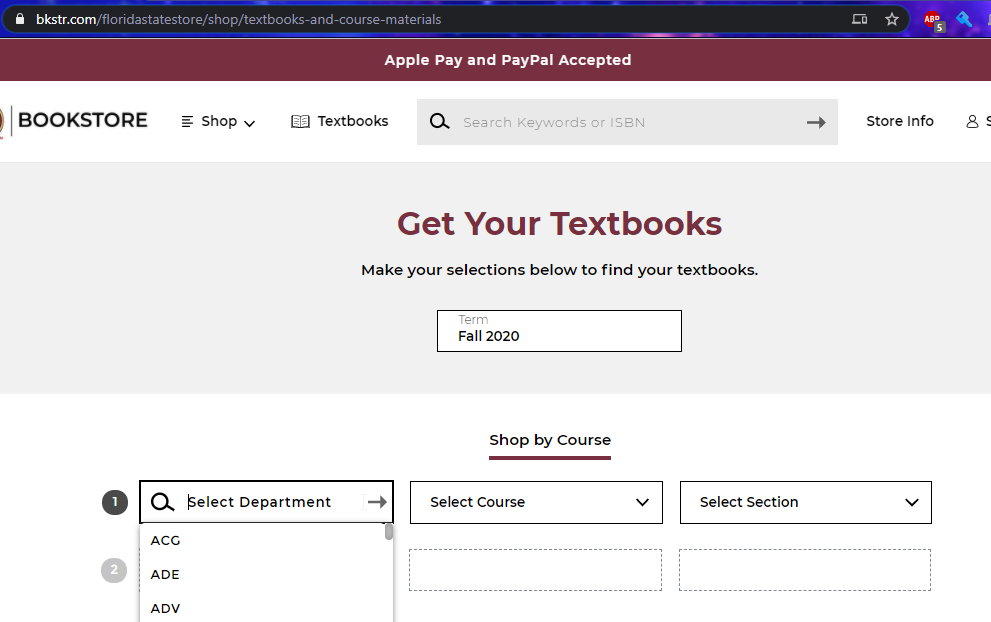
Departments. And courses. And THEN sections. Just for a glimpse, there are 280 departments. I didn’t end up counting how many total sections there were but total books (both digital and print) ended up being 10,736. And there were many sections that didn’t have any required materials.
Fortunately, bkstr.com seems to be a modern website and using Angular 2+. Everything was loaded over XHR and was served in JSON. However, I needed to format the data so it could be used in a spreadsheet. Just for a glimpse of how the structure works (and it makes sense, good job bkstr.com):
interface ISection {
courseId: string;
courseRefId: string;
sectionName: string;
};
interface ICourse {
courseName: string;
section: ISection[];
};
interface IDepartment {
depName: string;
course: ICourse[];
};
But that means that the book information (which lives on the section) is three layers deep.
At first I was watching for XHR requests as I selected department, expecting the course and section data to be loaded in after selecting an item. But no, bkstr.com doesn’t mess around. They front load all of this data. This makes it a lot easier for me. The JSON from this request (https://svc.bkstr.com/courseMaterial/courses?storeId=11003&termId=100063052) looks like this:
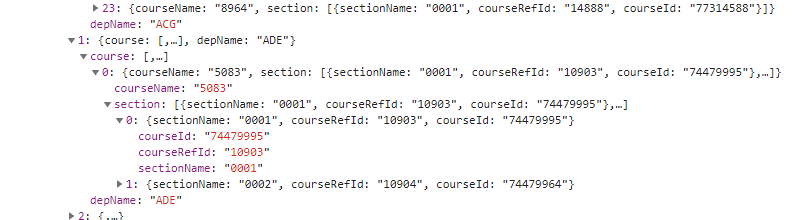
termId makes sense to me here. It defaults to Fall 2020 right now but we could probably swap it out for different semesters. But…storeId? Also…wait. The domain name isn’t anything to do with Florida State. How many other universities does bkstr.com serve?
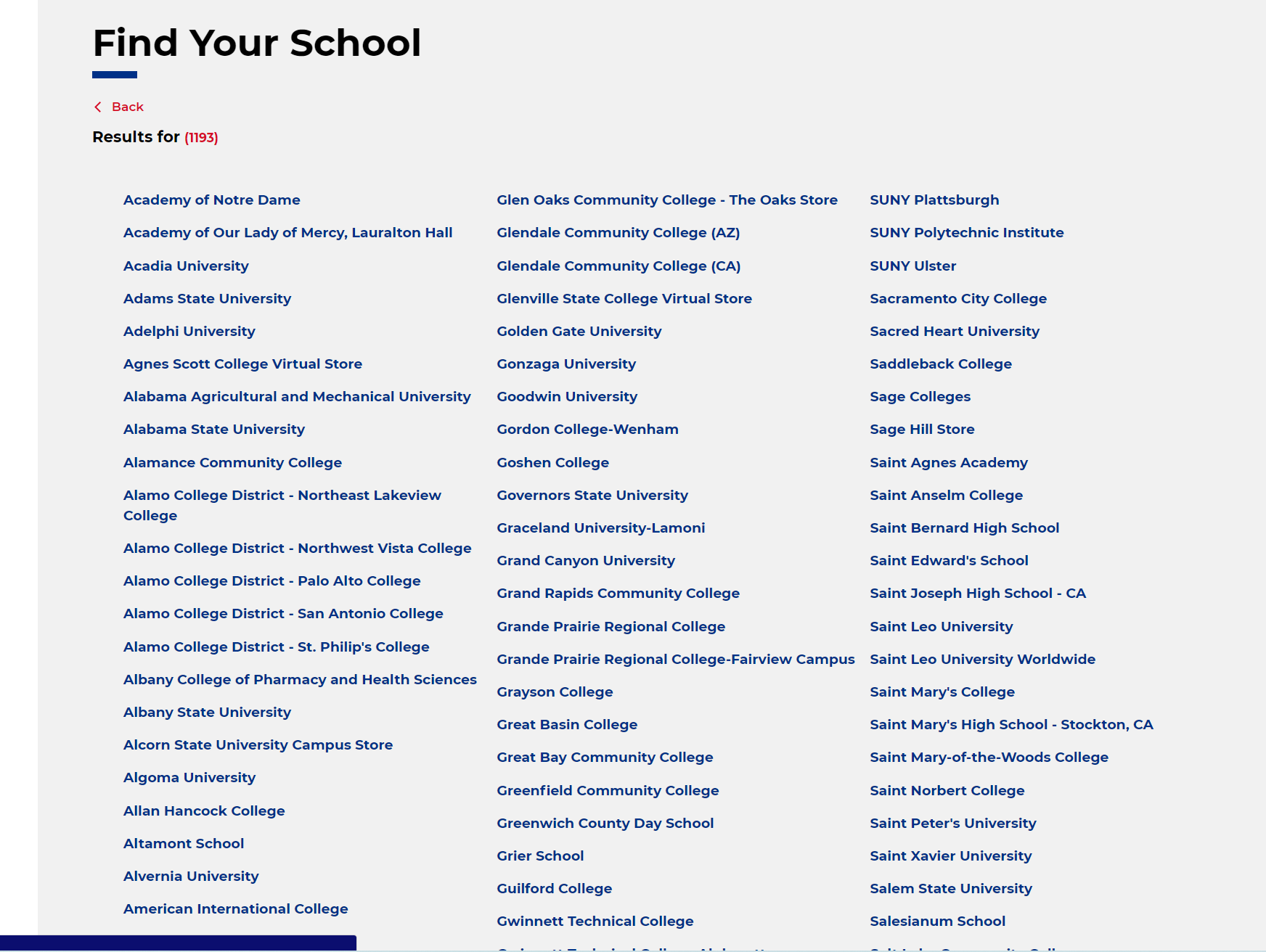
Dang, bkstr.com. You go. There are definitely over 1,000 schools in this list.
I didn’t try it but I would bet that you could swap storeId and termId for any of these universities. Cool.
Getting book information

This is my next step:
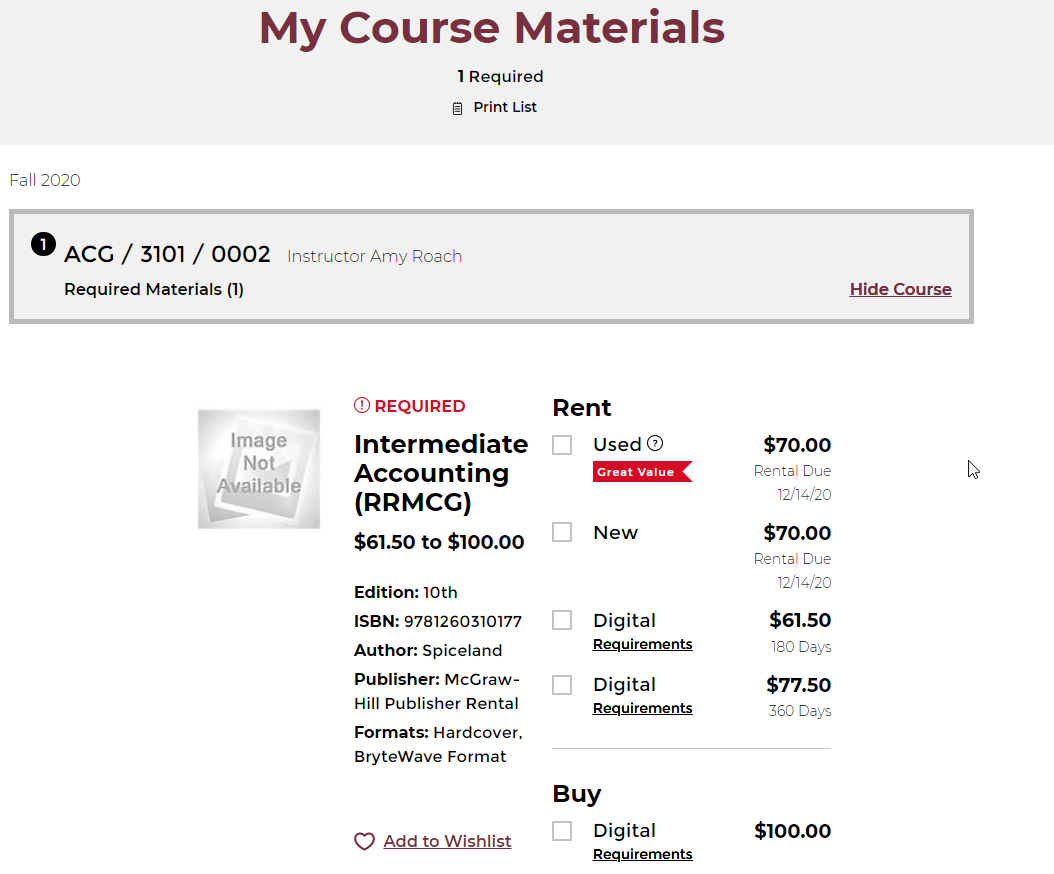
Again, going to the XHR requests showed this (https://svc.bkstr.com/courseMaterial/results?storeId=11003&langId=-1&catalogId=11077&requestType=DDCSBrowse):
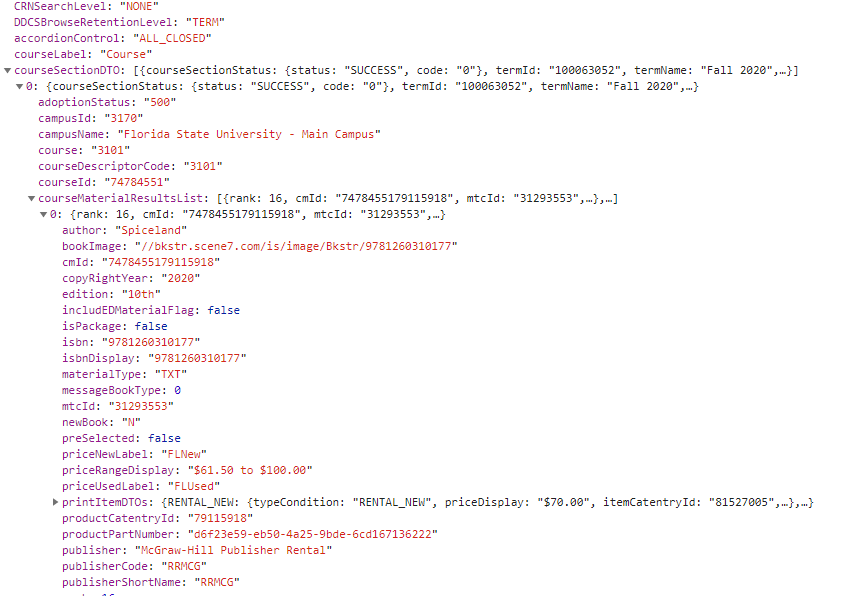
Alright, I’m in business. Now to find out what information it needs to get this. Check the payload from the above POST request:
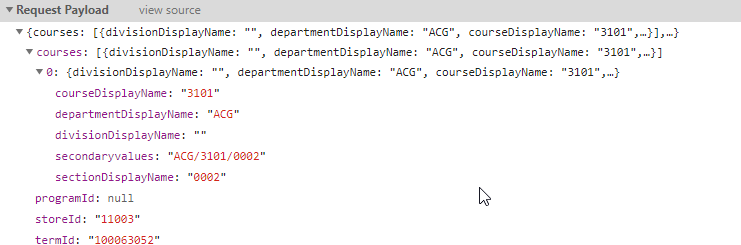
Great. I get all of that information from the department call from above. Also…see something else interesting? The courses part is an array. Can I maybe request more than one course at a time?
If there are 280 departments at FSU and let’s say they average 30 courses per department (some had over 500, some had 1, so this is a very rough estimate) and then let’s say four sections per course (again, shot in the dark) that’s 33,600 sections to check. If I can bundle up some of those requests, that’d reduce the script time and overall load significantly.
Alright, I have my path forward. Get all of the departments, courses, and sections from the first request and then the book information from the second request. Time to start coding.
Small Challenges

Okay, so I know there are going to be a huge amount of books. What other problems might there be?
First stop: 403 error when making an axios request. Added a ‘user-agent’. After a few requests I hit another 403. Added a cookie that was copied from my web browser. I’m in business. It’s all working now.
Code start:
const termId = "100063052";
const departments = await getCourses(termId);
console.log('Departments', departments.length);
const courseMaterials: any[] = [];
// Loop through everything
for (let depIndex = 0; depIndex < departments.length; depIndex++) {
const department = departments[depIndex];
const sectionsToRequest: any[] = [];
for (let courseIndex = 0; courseIndex < department.course.length; courseIndex++) {
const course = department.course[courseIndex];
for (let sectionIndex = 0; sectionIndex < course.section.length; sectionIndex++) {
const section = course.section[sectionIndex];
// Create array of sections from course to request all at once
sectionsToRequest.push({
courseDisplayName: course.courseName,
departmentDisplayName: department.depName,
divisionDisplayName: "",
sectionDisplayName: section.sectionName
});
}
}
... // more below
There we go. I loop through…everything. Lots and lots. Departments > Courses > Sections. Loops on loops on loops. Because I saw that array of items I can request, the above shows me adding all of the sections for a department into a sectionsToRequest array that I pass to that URL.
The first department (Accounting. Pfft, am I right? Just kidding, my degree is in accounting.) had 69 courses and who knows how many sections. And…it failed. 400. Looking at the error message and bkstr.com continued to do be awesome.
{
"errors": [
{
"errorKey": "_ERR_GENERIC",
"errorParameters": [
"DDCS Course Added cannot be greater than 30"
],
"errorMessage": "The following error occurred during processing: \"DDCS Course Added cannot be greater than 30\".",
"errorCode": "CMN0409E"
}
]
}
No more than 30. Cool. I can do that.
let courseSectionResults: any;
console.log('Total coursesToRequest', sectionsToRequest.length);
// Can only includes 30 sections per request
const totalRequests = Math.ceil(sectionsToRequest.length / 30);
for (let i = 0; i < totalRequests; i++) {
try {
courseSectionResults = await getCourseMaterials(termId, sectionsToRequest.slice(i * 30, 30));
}
catch (e) {
console.log('Error requesting', e?.response?.status ? e.response.status : e);
throw 'Error here';
}
I get the total sections, divide it by 30 (rounded up) to get the total amount of requests, and loop until we hit the total number of requests, slicing the array into chunks of 30. And we are in business.
Next we look at our results and only take the sections that have material:
for (let courseSectionResult of courseSectionResults) {
// Sections that aren't successes don't have materials
if (courseSectionResult.courseSectionStatus?.status === 'SUCCESS') {
Bigger Challenges

So far things are looking great. I ran it for the first department and it worked great. Now time to turn it on for all 280 departments. It’s running along like a champ and then after 10-20 departments…403. Uh oh. I thought the cookie was supposed to solve this.
I navigate to the website from my browser. Captcha prompt. I solve it and run the code again. 10-20 departments, 403, and captcha.
Dang, now what. This is something that I’ve addressed beating captchas before but I’m not even calling to the website. I’m not using puppeteer. I really didn’t want to add a puppeteer portion to this nor try to navigate to the web page with axios, watch for a captcha, and then try to solve it if it hit a 403.
Now to try Luminati. I wrote a post about it a little bit ago. It’s a bit more expensive than solving the captcha but it definitely would make the code I’ve already written a lot more simple.
I run it with Luminati. 403 after a certain amount of requests. What the? I’m baffled. I send a request using the same Luminati implementation to https://lumtest.com/myip.json. My requests are using the proxy. Why the 403? If the IP is rotating, how does it know to block me after a few requests? Me right now:

I went to bed.
Sometimes, do you just code in bed? That’s what I did.
Cookie.
The cookie. They must be tracking and blocking based on the cookie. I removed the cookie. And…no 403s. ~11k books. Amazing.
const url = `https://svc.bkstr.com/courseMaterial/courses?storeId=11003&termId=${termId}`;
const axiosResponse = await axios.get(url, {
headers: {
// Don't add a cookie
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.121 Safari/537.36'
},
proxy: false,
httpsAgent: new HttpsProxyAgent(`https://${process.env.luminatiUsername}:${process.env.luminatiPassword}@zproxy.lum-superproxy.io:22225`)
});
// Don't add a cookie!
Code to flatten
It’s nothing too fancy.
function flattenData(courseMaterial: any, departmentName: string, courseName: string, sectionName: string) {
const materials: any[] = [];
const courseData: any = {
department: departmentName,
course: courseName,
section: sectionName,
author: courseMaterial.author,
bookImage: courseMaterial.bookImage,
edition: courseMaterial.edition,
isbn: courseMaterial.isbn,
title: courseMaterial.title,
publisher: courseMaterial.publisher
};
// for non digital items
if (courseMaterial.printItemDTOs) {
for (let key in courseMaterial.printItemDTOs) {
if (courseMaterial.printItemDTOs.hasOwnProperty(key)) {
const printItem: any = {
...courseData
};
printItem.price = courseMaterial.printItemDTOs[key].priceNumeric;
printItem.forRent = key.toLocaleLowerCase().includes('rent');
printItem.print = true;
materials.push(printItem);
}
}
}
if (courseMaterial.digitalItemDTOs) {
for (let i = 0; i < courseMaterial.digitalItemDTOs.length; i++) {
const digitalItem = {
subscriptionTime: courseMaterial.digitalItemDTOs[0].subscription,
price: courseMaterial.digitalItemDTOs[0].priceNumeric,
print: false,
forRent: true,
...courseData
};
materials.push(digitalItem);
}
}
return materials;
}
The coolest part was that I had to loop through all materials and I didn’t want to rebuild my courseData inside different conditions (print vs digital). So I built the courseData object and then when it came time to build the item, I just included courseData and used the spread operator (which works on objects!). Worked like a charm.
The end!
See all of the code here.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome web data. Learn more at Cobalt Intelligence!
The post Jordan Scrapes FSU’s Bookstore appeared first on JavaScript Web Scraping Guy.

Top comments (0)