Today I’m going back to the Roller Coaster Database. I had a doctoral student reach out asking for some help with scraping the rcdb and he was using my code from my original post about it. It kind of led to me having to use some advanced techniques for CSS selecting while web scraping and that’s what I’d like to highlight today.
Fragility of web scraping

Web scraping code is extremely fragile. This post and story showcases that very well. This doctoral student reached out, saying that he couldn’t get the code to work. As I looked at his error, I could see that something had changed on the RCDB side.
This is the danger and pain of web scraping. We don’t control the source code. Any time the source html structure is changed, it has a high chance to break the CSS selectors we were previously using.
Web scraping code is going to require regular maintenance. In light of that, it’s best to build it in a way that expects that so this maintenance can be done quickly and with little pain.
“Smart” CSS Selectors

This doctoral student also asked if it was possible to grab a few additional fields. These fields, to be specific:

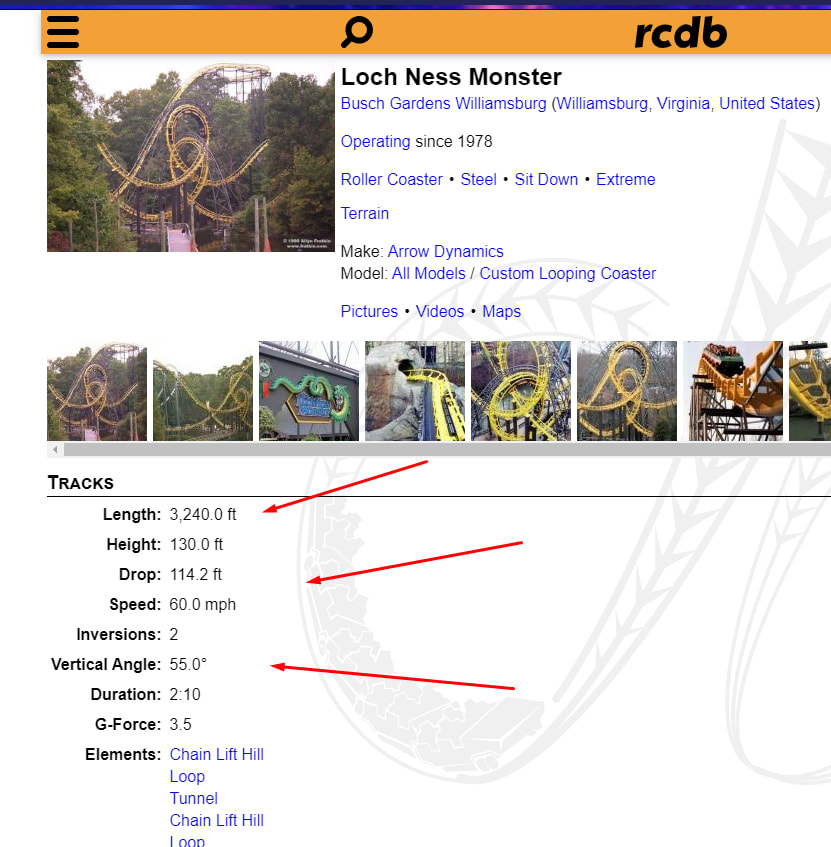
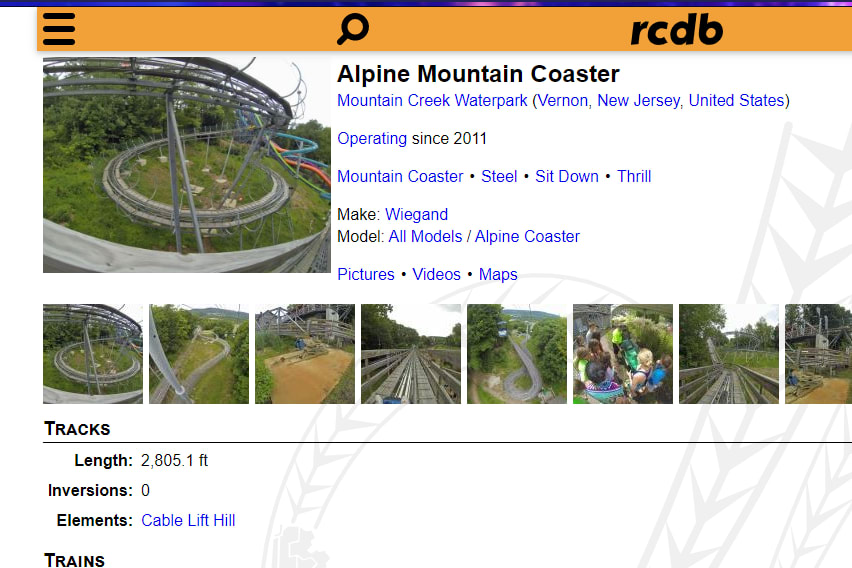
See a problem yet? A common technique when using CSS selectors while web scraping is to just find the nth element. So I’m making the assumption that that field (inversions, for example) will always be at the same location. In the above examples, inversions is the 1st, 5th, and 2nd row, making my assumption incorrect.
What’s the solution? Well, in this case, and often this will work, is to try and make the code smart. Fields of data almost always have labels and when it’s in a table format like this it normally follows the same format. Here’s what the code looks like:
$('section:nth-of-type(2) .stat-tbl tr').toArray().map(element => {
let header = $(element).find('th').text();
header = camelize(header);
if (header === 'inversions' || header == 'duration') {
const span = $(element).find('td').text();
if (!undesirableStats.includes(header)) {
rollerCoaster[header] = span;
}
}
else {
const span = $(element).find('span').text();
if (!undesirableStats.includes(header)) {
rollerCoaster[header] = span;
}
}
});
I go ahead and grab all the rows in this stats table (found by using the CSS selector section:nth-of-type(2) .stat-tbl tr) and then loop through each. I take the header value, use a neat function to turn it into camel case, and then I just use that as the key in my object.
The HTML I’m pulling from looks like this:

Still Fragile!

You can see in the code above that I have a conditional in there. Originally I did not. This point reemphasizes how fragile and kind of crummy web scraping code can be. I’m hard coding fields and changing how my CSS selectors work based on the header values.
All of this because I am at the mercy of the source code. For the fields of ‘Inversions’ and ‘Duration’ the HTML structure is different.

If you look at speed, the value I want is within a span. For inversions, there is no span. So my original code broke and I had to set up a condition where it uses different CSS selectors based on the different field. Kind of a bummer.
And…that’s it. It’s a neat way to try and be smart when the values you’re selecting aren’t always in the same spot.
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Does Advanced CSS Selectors appeared first on JavaScript Web Scraping Guy.

Top comments (1)
Instead of hard coding an if/else, you could also loop through the rows and select the span if it exists, otherwise select the entire td. That would probably be a bit more flexible