What is Disaster Recovery anyway?
While dealing with Terrabytes of data every day, it is not uncommon for critical infrastructure components to run into situations that might cause data corruption and are not easy to recover from. There are many reasons or scenarios that can force an application to an inconsistent state. These might include but are not limited to:
- Natural disasters like hurricanes or earthquakes leading to the entire data centre going down
- A bug in the application code leading to incorrect or corrupted data
- Infrastructure failure due to power outages
- Cyber attacks leading to loss of data or partial data
These scenarios are commonly referred to as disasters, and the ability to recover from these disasters to a consistent state is called disaster recovery.

In this post, I am going to mostly talk about how we built disaster-recovery strategies for some common data systems like Aurora (MySQL), MongoDB, and elasticsearch. I will also talk about the challenges we faced, some common pitfalls and practical learnings that we got out of this project.
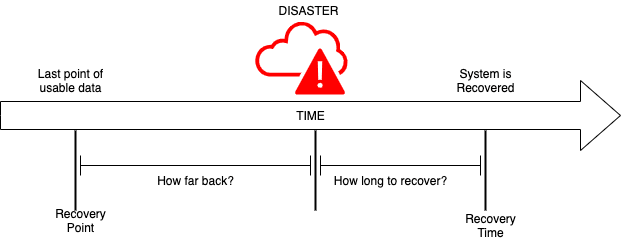
RTO/RPO
Two of the most commonly talked about terms when talking about disaster recovery are RTO and RPO. Although these terms look fancy, they are very intuitive and easy to understand if you look at the problem in a practical way.
RPO (Recovery Point Objective) - This refers to the maximum amount of data loss you are ready to bear in case of a disaster. For example, if you are okay to bear a loss of 1 day of data, your RPO will be 24 hours and this will be the frequency at which you take regular backups. Although there are many solutions to take regular backups, doing this very frequently might lead to an increase in costs.
RTO (Recovery Time Objective) - This refers to the maximum amount of time you are willing to spend in order to recover from a disaster. For example, if it takes me an hour to restore all the lost data, my RTO will be 1 hour. Generally speaking, more the amount of data, more time it will take to restore.
Defining a strategy
Most DR strategies for databases can be divided into 3 major steps:
- Snapshot Creation - Refers to the ability to take snapshots at regular intervals
-
Snapshot Retention - Refers to retaining snapshots in a particular window, while deleting everything else. The retention policy windows can generally be divided into Incremental and Moving windows. Examples for each can be found below:
- Incremental Window
- Retain one snapshot for every month
- Retain one snapshot for every year
- Moving Window
- Retain one snapshot for each day for the last 15 days
- Retain one snapshot for each week for the last 4 weeks
- Snapshot Restoration - Ability to restore the database to a specific snapshot. Unlike backup retention and retention, backup restoration should not be automated but a manual step. This means that any kind of data restoration should originate from a clear user intent for such an activity.
Let's have a look at what things we should take into consideration while designing a DR strategy and the corresponding implementations. Some of the things that we should consider are:
- We should be able to rollout DR one instance at a time
- Rollout should be minimally invasive and should not cause any service disruptions unless absolutely necessary
- Taking regular snapshots should be automated, but restoration to a previous point in time snapshot should require manual intervention
- The user making the DR plan should be able to specify windows when backup should be taken (Backup process should not cause any disruption in service)
- The user should be able to specify windows for which snapshots should be retained
- Should have a good balance between RTO and RPO
With the above mentioned considerations in mind, we can go ahead and design a general purpose strategy that can be implemented across cloud providers in different ways
{
"enabled": true,
"creationStrategy": {
"triggerSchedule": [
"0 1 * * ? *",
"0 2 * * ? *"
]
},
"retentionStrategy": {
"triggerSchedule": [
"0 2 * * ? *"
],
"rollingWindow": {
"hours": 8,
"days": 15,
"weeks": 4
},
"incrementalWindow": {
"init": "1514764800",
"span": {
"type": "month",
"interval": 1
}
}
}
}
Architecture
Cloud agnostic vs cloud specific
Our CD platform is written in Terraform and works off of a state file present in an S3 bucket. Each execution of the CD pipeline takes the desired cluster state, compares it with the existing cluster state, and tries to move the cluster from current to desired state (like a control-loop). One of the core thoughts in our mind while building our CI/CD systems was that different teams can spawn their own instances of MySQL, MongoDB, etc., without needing to worry about the cloud provider their application is running on. For example, requesting for a MySQL instance on AWS would launch an Aurora instance, while requesting for the same MySQL instance on Alicloud would launch an ApsaraDB instance.


Because of the above mentioned use-case, even our DR implementation had to be written in a way that it could be implemented differently for different cloud components across different cloud providers. The DR setup includes the following steps:
- The CD pipeline creates the required crons to implement the above mentioned functionality according to the cloud specific implementation of the infrastructure component.
- The cronjob or the cloud function responsible for creating or removing snapshots will internally make an API call suitable to the underlying implementation of the database. For example, the underlying implementation for an SQL database can be different for different cloud providers -- Aurora for AWS, ApsaraDB for Alicloud, CosmosDB for Azure, etc.
- The implemented crons trigger at required intervals and create or delete snapshots
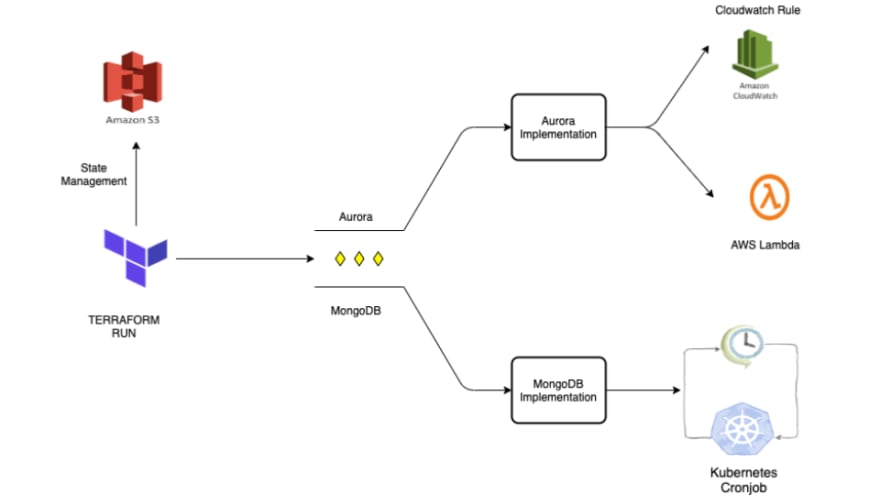
Snapshot Creation and Retention
For both snapshot creation and retention, we need the ability of running an automated job at regular intervals, which can take new snapshots or remove existing snapshots. The frequency at which this job runs can be defined in our DR strategy and its value can be decided based on our RTO and RPO objectives

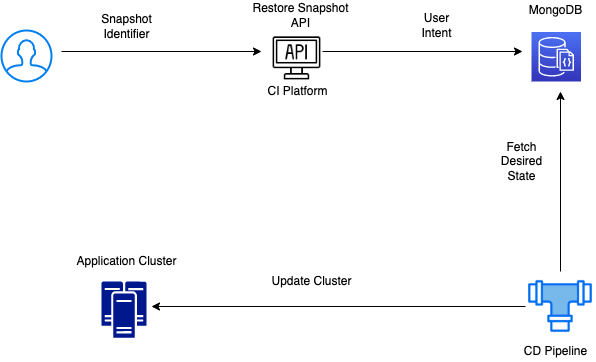
Snapshot Restoration
As mentioned before, the restoration of a database from a snapshot should require a manual user intent and the API and UI for the same should be limited by proper access control. The restoration flow can look something like this:
- User marks a snapshot as an active candidate for restoration via the API or UI
- The CI system should validate the user request and access level, and store the user intent in DB
- The user intent should be passed to the CD pipeline in the next run. This can work in a pull or a push model.
- The CD pipeline should infer that the desired state requires a database to be restored from a snapshot and take actions accordingly to restore data
In the interest of not making this post too long, I will be describing the exact implementation we chose for MySQL, MongoDB, and Elasticsearch in the next part of this series. The next part will also consist of our learnings while implementing DR for each of these database types. Stay tuned and cheers :)


Top comments (0)