
Even if you're not in the 'tech' industry, in today's computing age you may have heard the term 'CPU' tossed around. A CPU or Central Processing Unit is a general term for the 'brain' of today's computers. (I use the term computer here very loosely to refer to any sort of desktop, laptop, server, etc without attempting to fully encapsulate the infinite array of microprocessing units in our fridges, watches, and elevator controls).
How a CPU Works
A CPU may divide a series of tasks by time; where any given slot (or series of slots) may be dedicated to a given task or series of tasks. These tasks are assigned to a single computational unit (also known as a core, technically known as a floating point unit) at any given point in time, and the single core is freed to move on to its next task once the previously-running task has completed.
The issue with this model is readily apparent: what if I want two tasks to happen at the same time?
RTOS
Since the 1980's, the real-time operating system or RTOS was the only way by which a single CPU could achieve, or at least appear to achieve, some sort of concurrent operation. However, this "appear to achieve" is a bit of a gotcha, since the real-time in RTOS translates to finishing within a predetermined time-interval. This is achieved by some sort of scheduling algorithm, and a series of programming constructs for holding resources (mutexes), signalling (semaphores) and a host of other methods by which some sort of deterministic behaviour is effected.
This is not purely concurrent, there is no way to actually carry out simultaneous operations, say, on a large chunk of data
The Multi-Core Processor
 IBM 100 Power 4
IBM 100 Power 4
The first multi-core processor was the POWER4, however the first commercially available desktop processor accessible as a familiar socket-mounted package was the Intel Celeron for home consumer usage, and the AMD Opeteron for server usage. This took the single-core idea and solved the "I want to do two things at once" problem in the most brute-force way possible: if you want to do to (or more things) at once, then you need two (or more) cores.
This wasn't (and still isn't) an absurdly irrational concept, as the proliferation of multi-socket motherboards prior to the multi-core era demonstrated the desire for concurrency in the enterprise space.
 Multi-Socket Motherboard
Multi-Socket Motherboard
The main limitation before the introduction of the first multi-core CPUs was (and still is) power delivery. Having to power two cores in a single package introduces complications and adds additional heating requirements. Moreover, having the introduced overhead for core synchronization and memory sharing not outweigh the benefits of multi-core has seen many creative solutions over the years, the most recent of which is AMD's Infinity Fabric
When the first multi-core processors came out, the issue was fitting enough transistors on a chip to build more than one core. The issue regarding transistor size has for more or less disappeared, as we approach the opposite problem in transistor design: as transistors shrink below the 1-2nm mark, new quantum effects such as tunneling introduce an entirely new class of nondeterminism into chips' operation.
Okay, so now you understand where CPUs came from, and how being able to do more than to things at once was physically achieved, but where do GPUs come in?
The CUDA Core!!
or streaming processor?
Okay I love NVIDIA and AMD, but their definition of a 'core' is a bit, err...ambitious? On the CPU side of things, a 'core' should be able to fetch instructions, load the necessary data required to perform this instruction into memory, perform the said data operation as indicated by the instruction, and return the complete, processed data at the end of the operation.
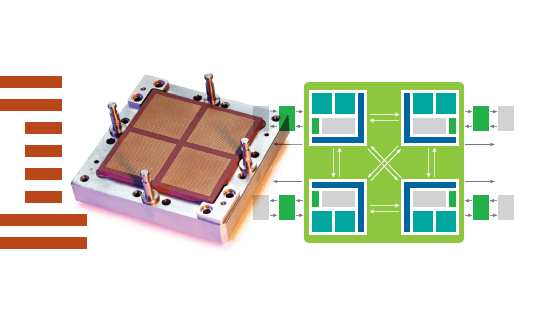
 Layout of the latest 3000-series GPUs
Layout of the latest 3000-series GPUs
A CUDA core or (Stream processor depending on which colour flag you're currently waving, for me it's currently green, so we'd stick with "CUDA Core" for now), is simply a floating-point unit. It receives data, performs some operation, and returns it. It does not independently handle fetching instructions and loading data into memory.
Terminology out of the way, modern-day GPUs have thousands of CUDA cores, the GA104 in my NVIDIA RTX 3060ti has nearly five thousand CUDA cores. Heck, the measly mobile GTX1060M in my laptop has over a thousand, and that launched five years ago. GPUs are essentially a set of floating point processors bundled nicely into a well-powered, nicely ventilated chip which makes GPUs incredibly versatile for huge levels of parallelism.
GPUs have been used for real-time scheduling, graph algorithms, HPC, object detection using neural networks, and the list goes on. This is due in no small part to the nature of machine-learning applications, and the ability of neural networks to be split across multiple processing cores. Major Deep Learning frameworks such as TensorFlow and PyTorch now offer GPU support by default (once the CUDA toolkit and cuDNN is installed).
With respect to purely cost, GPUs have higher instruction throughput and memory bandwidth when compared to CPUs. Additionally, GPUs tend to have significantly higher raw arithmetic capabilities than CPUs, and is centered around a large number of fine-grained parallel processors.
I could go on and on about the wonders of GPUs and where there are used, and probably do some more hand-wavy stuff in an attempt to convince you that GPUs are really cool, but I'd rather go in a bit more detail into how exactly GPUs do what they do, and the thinking that goes into developing a GPU program.
From here forward, most of the technical details are NVIDIA-specific, however they can for the most part be ported to AMD/ATI GPUs
The Programming Model
GPUs work on the SIMD model, or the single-instruction-multiple-data idea, where a single operation is to be carried out on multiple data points in parallel. These operations must be independent, as there is no data-sharing between these operations. This is in direct contrast to the MIMD model of the CPU (or multi-instruction-multi-data, where CPUs possess inherent complexity to be able to handle multiple types of different tasks).
GPUs are more general purpose, as their floating-point units can be adapted to a wider range of applications by means of a programming interface (such as CUDA).
 How Threads are grouped into blocks which are grouped into grids
How Threads are grouped into blocks which are grouped into grids
A streaming multiprocessor or an SM, in NVIDIA-land could be thought of as a multithreaded CPU core, with its own shared memory, with a set of 32-bit registers (think of this as the GPU equivalent of L1 cache), and contains a set of floating point units. A collection of threads called a block runs on an SM and executes a custom GPU function called a kernel.
That's a lot of terminology, the important bit to note is that current GPUs have a limit of 1024 threads per block, and this number is further limited by the available memory requirements of your specific kernel. For a more in-depth explanation of this, see here
Thinking About Problems
The GPU architecture is centered around fine-grained parallelism (or thread-based parallelism). This is where a problem is partitioned into coarse sub-problems solved independently by blocks of threads, where each sub-problem is split into finer pieces that may be solved cooperatively in parallel by all threads in a block.
There can be a few issues here however, where bad branching in your custom GPU program or kernel results in massive overhead induced by the GPUs limitation to tell a block of threads to do only one thing. For example, if your kernel needs all the even-numbered threads to do one thing, and the odd-numbered threads to do another thing, there will always be one set of threads waiting on the other to complete its task, which effectively doubles the processing time for your given task (or set of tasks).
Sharing is Caring
Remember where I said that each thread can work only on independent data points? Well in theory this may seem feasible, but in practice this idea falls apart. Think of the simplest case of needing to first calculate the square of a series of numbers, followed by finding a sum of these numbers. Every "square" mathematical operation can happen on a separate thread, however when needing to sum the output, the threads need to talk to each other, or at least have some central repository by which to sync their outputs. This is where shared memory comes in. (This is one of the main types of memory available in the CUDA programming model, along with global, texture and host memory).
Shared memory is a memory that can accessed all threads within a block, and is orders of magnitude times faster than system memory, with significantly lower latency. (It can be thought of programmer-controlled L1 cache). The CUDA programming model introduces a special keyword __syncthreads() to ensure no race conditions occur.
A race condition is where two processes need to access a single memory location, and one of both threads attempts to read from/write to the memory location before the other is done with its own operation. This can lead to failed reads and corrupt writes.
This is a very basic introduction to why GPUs are useful, and how they function on a high-level basis. If you have any questions, feel free to contact my via the email listed in the profile, and happy reading!

Top comments (0)