Originally published on my blog.
JAM stack is a concept, that emerged some time in late 2019 or early 2020. It takes the already established concepts of cloud native web development and SPAs1 one step further. There is nothing technically new in JAM (which stands for Javascript, APIs and Markup), but by applying a new view on the combination of those technologies, it defines a new (and kind of liberating) approach to building web based applications.
I am trying to give a gentle introduction into what the JAM stack actually is, and try to share my view on how and why it is important to developers. Reading this article should allow you to have an informed opinion about it.
What is a JAM stack?
From a high level perspective, the JAM stack is limiting the technologies you use to three main building blocks:
- Javascript
- APIs
- Markup
So the idea is to use Markup (probably HTML) as a basic foundation and scaffold around your application, fill in the interactive functionality (potentially using SPA frameworks1) using Javascript and connect to server functionality (like persistence, heavy calculation, payment handling, …) via an API.
What you would not do (among other things) is to render dynamic content on your web server (using some kind of backend framework2 or more modern approach like next.js). The only role of the web servers in a JAM stack application is to provide an API for their functionality.
Classic website approach
To get a better perspective on the matter, let's look at a more classic approach to building websites or web apps.
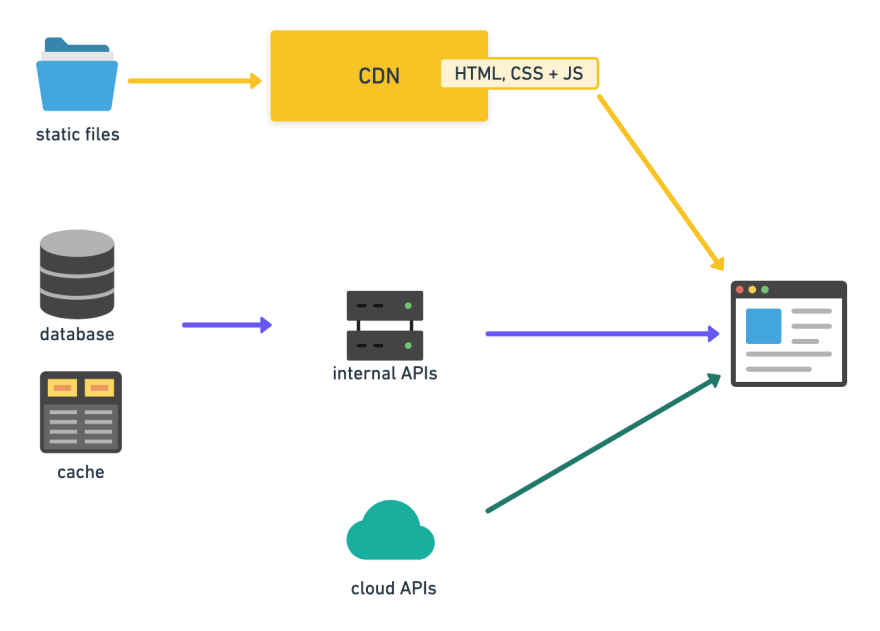
You probably have a bunch of different building blocks, like static files (css, js or images), a database and probably some kind of caching system. You also might use some internal or cloud APIs to get additional functionality (like providing your users with credit card payment etc).
The classic way to build a website like this is to build a big node.js application, which does all the heavy lifting by connecting the different sources of data and functionality and renders nice looking pages for the browser to display.
Whenever a user interacts with the page (by clicking a link or submitting a form), a request will be sent to the server, it will generate a new page (probably using a database) and sent it back to the user's browser.

This is – of course – an extremely classical approach, but I wanted to have something to contrast the JAM stack approach to.
JAMstack approach to building a website
Building a website using the JAM stack approach limits the technologies we can actually use to a set of simple and manageable tools: Javascript, APIs and Markup.
Markup
Most websites and web applications have a good portion of basically "static" markup. Think of your skeleton HTML and maybe your markdown3, that form your "basic" content pages, like the contact or about pages. There is nothing dynamic about them, no need to update them constantly, and no need to run a CMS to generate those.
You can either create these HTML files manually, or use some kind of static site generator4 to generate those for you. This markup will then be uploaded to some kind of simple web server or CDN5, together with any static assets you might have, like your CSS files of your logo.
Once this is generated and uploaded, it will only ever change, when you decide to deploy updates manually.
APIs
If you build anything but the simplest brochure website6, you probably want to run code on your server(s), that provides some kind of unique functionality. Be it saving your user's data in your database, or adding funny bunny ears to your user's profile picture.
Following the JAM stack approach, mean to put this functionality behind some kind of API, probably using HTTP endpoints7. The API code can then be deployed in the way you (or your company) prefers, be it on your own hardware in a data center somewhere or as using a FaaS8 service.
Additionally to your own APIs, you can (and maybe should) use external APIs provided by other companies. These external APIs, could add any functionality to your application, from a headless CMS9 to a payment provider. A beautiful side effect of this is, that in case you want to exchange one provider for another (or even an internal API you built) becomes a lot simpler, as there is only one place where all the APIs are connected: your Javascript running in the user's browser.
Javascript
The third (and last) building block is Javascript. All the dynamic functionality of your application, from loading your latest tweets to allowing user's to pay for the T-Shirt they want to buy, will be encapsulated in your Javascript code.
By doing that, your Javascript code will be the most important part of your application, and will probably need the most attention. Luckily, there are many great libraries, that help to build complex Javascript SPAs1.
Benefits
The most interesting question remains: Why should anyone use this? It certainly is true, that limiting one's choices already is a benefit in itself, as it forces us to be more creative in our approach.
Most of the benefits of using the JAM stack revolve around its simplicity and lack of things. If you don't have a backend server which partially generates your website's content, you will not end up with a big messy ball of mud10, that becomes unmaintainable after a few years.
If you don't generate any part of your website "on the fly" for your users, and instead put your application (except for your APIs) on a CDN, hosting will be very cheap because you do not need to run expensive servers. Even in peak times, the CDN will just handle the distribution of your application, so that even Black Friday does not have to scare you anymore.
There is also the benefit of security: The only way to have a secure server, is to not have a server at all. Everything that exists can be hacked, so better not have the server exist at all. 😉 The APIs you will write for your JAM stack application need to be accessible by the user's browser, so you are basically forced to secure them properly, instead of hiding them behind some kind of load balancer / firewall setup.
It is also true, that the JAM stack approach makes it less hard and/or scary to deploy a change to production: What you deploy is "just" a set of static files, containing your markup and Javascript. So if anything goes sideways with a new release, it is very simple to "roll back" and redeploy the old files.
There are certainly more benefits to using the JAM stack, and I would be happy to extend this list with your ideas. Do not hesitate to get in contact with me via twitter.com/__florian or email.
Recap
What I intent to express is:
- JAM stack stands for: Javascript, APIs and Markup
- It very much reduces the technology choices you can make
- It takes a lot of emphasis away from classic server backend driven approaches
- Some of the benefits are scalability and security
I hope that you did not only enjoy reading this article, but could also learn something valuable from it. Thank you for spending your time on reading my words.
Further reading
- jamstack.wtf is a great short website explaining the topic in a very digestible way
- jamstack.org is a wonderful learning resource
- snipcart.com/blog/jamstack is a longer blog article about this very topic
-
SPA stands for Single Page Application. The idea is that your application does not use the traditional model of splitting up your application into many pages and have the user navigate from one page to another using links. The SPA approach is to have one single page, and dynamically update or replace parts of the page, depending on what the user is trying to achieve. Popular SPA frameworks (as of May 2020) are React.js, Angular.js or Vue.js. ↩
-
There are many "backend frameworks", and they exist for almost any programming language. Popular frameworks are Express.js, Ruby on Rails, Symfony (PHP) or .NET (C#). ↩
-
Markdown is a very simple way to write text, that will later be turned into HTML. Instead of writing tags like
<strong>this one</strong>, you simply use special characters like*this one*to indicate that a text should be emphasized, strong, a table etc. Markdown was invented by John Grober, and you can read more about Markdown on his website. ↩ -
The idea behind static site generators is, that even though some websites really need a CMS to manage all their content, many websites don't. This website for example, does not change very often: It only changes whenever I write and publish a new article. Static site generators are wonderful tools, that basically take a directory full of content files (like these articles), combine them with a layout (like the one you see) and output a new directory, with fully rendered beautiful HTML pages. This resulting directory can then easily be deployed to any kind of simple web server. This makes hosting a statically generated website very cheap and secure (because there is no dynamic code or database to attack). This website is generated using the open source tool Jekyll, and the website StaticGen has a great list of alternatives. ↩
-
CDN stands for Content Delivery Network. To put it simply, a CDN tries to make static files (like CSS or your logo) available to your website's users as quickly as possible. To achieve this, it usually consists of many servers distributed all over the planet. When you upload a file to the CDN, all the distributed servers will receive a copy of your file. Later, when a user wants to see that file (let's say the logo on your website), the CDN will deliver it from the server that is closest to your user. If you – for example – live in central Europe and upload your logo to a CDN, a website visitor from Korea will receive this file from a server in Korea, not central Europe. This improves loading times a lot. ↩
-
Brochure website is a term often used for websites that do not accept any input from users, and are instead just displaying information, generated by the people who run the website. This was very popular in the early days of the internet, and is still used in many occasions. Think about a product website for a new phone or computer: The page will give you a lot of information, but you cannot contribute anything. ↩
-
Endpoints are ways to access functionality on the server, using the network (mostly the internet) to send to and receive data from. There are technologies that can be used to achieve this. The ones that are most often used (as of May 2020) are: REST; GRAPHQL and Web sockets. ↩
-
Functions as a Service is a new approach to building functionality that would previously be build using backend server technology. The basic idea behind it is that every piece of functionality is bundled up and deployed as a single unit to some kind of service provider. You – as the developer – do not need to worry about how and where this function is actually running: The service will provide you with a URL that you can call to get to your function. The rest is abstracted away from you. The technology behind this is still relatively young, but it has potential to be a good tool for very special use cases. ↩
-
The idea behind a headless CMS is quite clever: The CMS will provide you with a wonderful and easy to use backend, which can be used by you and your team to create and structure content and probably even upload assets. While a "classic" CMS will also be able to turn your content into a beautiful website, a headless CMS will only provide endpoints7, that you can use with your code to receive the data. ↩
-
Big ball of mud is a term coined by Brian Foote and Joseph Yoder to describe a piece of software, that consists of code that is completely unstructured and has an endless amount of undocumented connections between components. Software like that is very hard (and expensive) to maintain, and very unpopular among developers. ↩

Top comments (0)