
“The remarkable speed at which Risingwave enables us to ship new features is so impressive that our data engineers simply can’t do without it.”– Hu Yu, Founder/CEO of Kaito AI
TL; DR
Kaito utilizes Risingwave as the streaming data warehouse that powers its AI-based search products, user-facing analytical dashboards, internal operational workloads, and real-time alerts, among other applications.
By consolidating the real-time data infrastructure for various applications into a single system, Risingwave, Kaito achieves the following benefits:
- Significantly reduces processing costs and enhances data freshness through Risingwave.
- Provides analytics and operational insights to clients and the in-house operations team with near-instantaneous latency.
- Drastically lowers development costs and shortens the learning curve as engineers can focus exclusively on implementing new features using Postgres-compatible SQL and leveraging existing ecosystems.
Who’s Kaito?
Kaito is a fintech company headquartered in Seattle, Washington, USA. Backed by investors such as Dragonfly, Sequoia, and Jane Street, the company's mission is to create the industry's first financial search engine based on a Large Language Model (LLM).
It aims to meet the cryptocurrency community's demand for indexing data scattered across various private information sources and blockchains, which are invisible to traditional search engines like Google. By combining its proprietary financial search engine's real-time data with advanced LLM capabilities, Kaito aims to provide a revolutionary information access experience for 300 million users, enabling them to obtain information related to the blockchain and its surrounding ecosystem more efficiently.
LLM-powered AI chatbot
Users have the ability to inquire about any crypto ticker or decentralized applications (dApps). The chatbot harnesses real-time data gathered from multiple sources to:
- Generate a concise overview of the project.
- Present a chronological list of the most recent developments.
- Highlight significant research coverage.
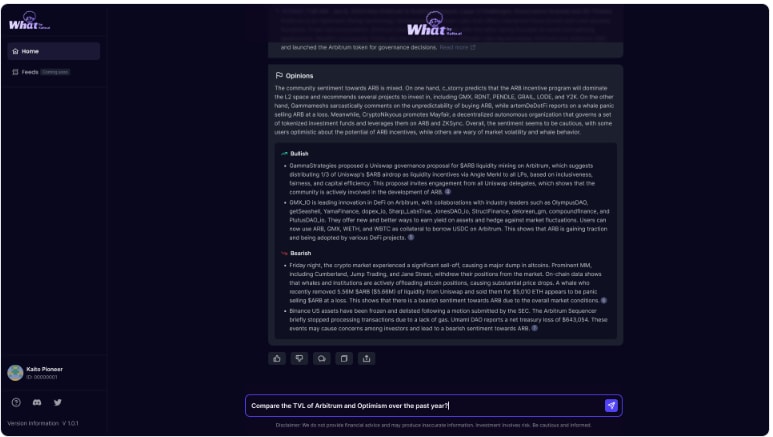
- Summarize both bullish and bearish perspectives.
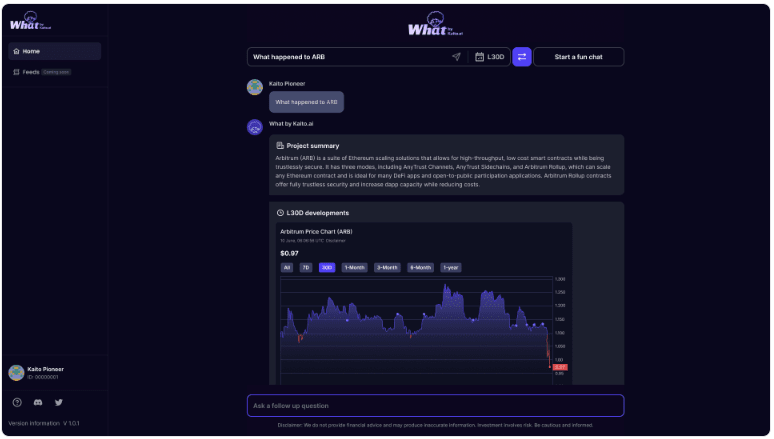
As demonstrated in the example with ETH above, users can swiftly grasp the core concept of a crypto ticker or dApp within seconds and explore further details through follow-up inquiries.
For users who have previously interacted with other LLM-based AI tools, it's not uncommon to encounter instances where these bots provide inaccurate information. Kaito ensures that every statement presented by the bot is substantiated with a source of information, guaranteeing the reliability and accuracy of the provided data.
All-in-one Search Engine
 Users can simply enter a keyword into the search box and select their preferred sources to pinpoint essential information. The latency, from the moment data is generated to when it becomes searchable on Kaito, typically falls within a matter of minutes, often in the low single-digit range. For premier members, this process can be further expedited, ensuring even faster access to the desired data.
Users can simply enter a keyword into the search box and select their preferred sources to pinpoint essential information. The latency, from the moment data is generated to when it becomes searchable on Kaito, typically falls within a matter of minutes, often in the low single-digit range. For premier members, this process can be further expedited, ensuring even faster access to the desired data.
 In addition to raw data, Kaito also gathers engagement data, such as the number of reposts and likes for a tweet, and transforms it into informative dashboards. For instance:
In addition to raw data, Kaito also gathers engagement data, such as the number of reposts and likes for a tweet, and transforms it into informative dashboards. For instance:

Social intelligence plays a pivotal role for investors and traders. Here are some examples:
- Short-term trends serve as valuable indicators for traders to capitalize on FOMO (Fear of Missing Out) opportunities or minimize losses.
- Medium-to-long-term trends offer insights for investors to assess a project's maturity or the strength of its community.
- It also plays a crucial role in fraud detection. Some projects artificially inflate their engagement data with bots, resulting in distinct patterns on their dashboards compared to genuine projects.
- To further refine the information, Kaito dynamically maintains a curated list of influential Twitter accounts recognized as Key Opinion Leaders (KOL) or astute investors, based on their historical engagement activities.
Users also have the option to personalize real-time alerts. Through the "My Searches & Alerts" feature, users can define specific criteria for tweets or news articles that they deem important. When a new message meets these criteria, Kaito promptly sends alerts to users' preferred destinations, including platforms like Telegram, email, or via API services. This functionality is especially valuable for day trading or quantitative trading, allowing users to stay informed and make timely decisions.
Internal Operations
As an increasing number of institutional and retail users adopt Kaito as their daily research tool, continuous monitoring of product metrics and ongoing enhancement of the user experience becomes paramount. In addition to standard metrics like DAU (Daily Active Users), MAU (Monthly Active Users), and conversion rates, Kaito keeps a close eye on several other real-time metrics.
For instance, Kaito closely observes the length of conversations and the types of follow-up questions to gauge user satisfaction when interacting with the LLM chatbot. These statistics serve as valuable inputs for enhancing the in-house fine-tuned AI models.
Furthermore, the team is vigilant in identifying and responding to anomalies. For instance, when new models or prompting techniques are introduced for A/B testing or production deployment, the team strives to promptly and continuously assess their impact on user behavior.
The same principles also apply to the ongoing refinement of the search engine to ensure it consistently meets users' evolving needs.
The Challenges!
Timely information and precise insights form the core of Kaito's value proposition. Recognizing this, the data engineering team at Kaito identified a critical need for a real-time data infrastructure capable of empowering the platform.
Timely
Raw data sourced from the real world is often messy and cannot be directly utilized. Upon extraction from various sources, it must undergo a series of essential steps: cleaning, transformation, enrichment, aggregation, and indexing before it can be presented to users or fed into our in-house AI model.
The value of the information is directly proportional to the speed of this end-to-end process. Given the financial context of Kaito's product, real-time processing is an absolute necessity. Stream processing, as opposed to traditional batch processing, is the exclusive avenue to achieve this.
For those from a Web3 background who may not be familiar with stream processing and batch processing, the distinction between these two paradigms is straightforward:
- Batch processing involves waiting for all the data to accumulate before processing a finite dataset to extract insights. The end-to-end latency comprises both waiting and processing times, resulting in suboptimal freshness of insights.
- Stream processing, on the other hand, handles an unending stream of data in real-time. Intermediate results are continuously updated and contribute to the computation of the next second's insights. Properly implemented, stream processing can achieve end-to-end latencies in the sub-second range.
Batch processing forces users to strike a compromise between cost and data freshness. As the volume of input data accumulates, the cost of reprocessing increases as well. The more frequent the processing, the fresher the insights, but this comes at a higher cost.
In contrast, stream processing computes incrementally, with costs linearly related to the size of new data only. This allows it to offer the best of both worlds—exceptional data freshness at a manageable cost. However, there are nuances to consider, as we will elucidate in the following sections.
Accurate
As an investment research tool, Kaito's foremost responsibility is to deliver precise information to its users. This requirement has two critical implications for the real-time data infrastructure:
- Fault Tolerance: Servers may experience occasional crashes, and network connections can be intermittent. As Kaito continuously gathers data and performs the aforementioned steps around the clock, the stream processing system must endure these failures without missing data entries or processing the same data multiple times. Any such mishaps could lead to inaccuracies in the analytical insights presented to users. Moreover, the system's recovery time should be rapid, ideally in the order of seconds, to ensure Kaito's users don't miss any trading opportunities.
- Consistency: The same piece of data may undergo aggregation and be featured in multiple downstream applications, such as various dashboards. When users, or multiple users, view different applications that aggregate data from the same sources, it is imperative to guarantee that these applications offer a consistent perspective derived from the same upstream data. This consistency is vital to ensure users receive coherent insights across the platform.
Lower Cost
Data is the new oil. Kaito continuously collects vast amounts of data from various off-chain and on-chain sources, maintaining a 24/7 data stream. The demand for processing and storing data is considerable, so cost-effectiveness is crucial.
Real-world data doesn't flow at a consistent pace; it exhibits bursts of activity. This necessitates an elastic system capable of scaling resources up or down in response to fluctuating workloads:
- Inadequate resources in the system can lead to data congestion, preventing timely inclusion of crawled data in search results or real-time aggregation in analytical dashboards. This disrupts Kaito's value proposition.
- However, provisioning resources to match peak demand can result in excessive waste. During certain hours, the volume of crawled data may be five times higher than the average. In practice, users of conventional stream processing systems often opt for this approach because these systems are not efficient at scaling due to their storage-compute coupled architecture.
Choose Risingwave
Before settling on Risingwave, Kaito conducted an extensive evaluation of several other solutions available in the market. However, none of these alternatives fully met all the aforementioned requirements. Furthermore, the Kaito team discovered unexpected additional benefits when they adopted Risingwave.
Serving Queries
Initially, Kaito sought a stream processing system to read and transform data from upstream sources, forwarding the results to a downstream system responsible for "materializing" the data and handling user queries.
However, introducing a second system, even when leveraging cloud vendors' fully managed services, presented significant challenges:
- Manual Synchronization: Any changes to queries or schema in one system must be mirrored in the other, a frequent requirement due to evolving business needs.
- Inefficiency: Data transfer between two systems may become a bottleneck, incurring additional serialization/deserialization and network costs. The solution often involves scaling up with more machines, resulting in increased expenses.
- Isolation: Data engineers frequently transform data at various granularities and enrich it by joining multiple data streams. Sinking data into a downstream system forces data engineers to re-read the data back into the system when further processing is needed, leading to significant resource wastage and added latency, particularly with substantial data volumes.
- Inconsistency: When multiple streaming jobs sink data into different tables in the downstream system, maintaining consistency between these tables becomes challenging. There is no inherent control to ensure that these tables accurately reflect changes induced by the same volume of upstream data. This lack of coordination can result in inaccuracies when querying these tables together.
Risingwave distinguishes itself by naturally combining stream processing and serving queries within a single system. Users can define two types of streaming jobs in Risingwave:
-
create sink: This continuously processes input data and updates the downstream system. -
create materialized view: This continuously reflects updates in a materialized view stored within Risingwave. Users can then issue traditional batch SQL queries to access data in the materialized view or even query multiple materialized views simultaneously, all with the assurance of data consistency. In other words, all views accurately reflect changes brought about by the same volume of upstream data.
PostgreSQL Compatibility
Low Learning Curve and Development Cost
Startups prioritize rapid feature development and require systems with minimal learning curves and development costs. In the past, Kaito relied on Amazon Glue for backfilling and re-indexing off-chain data from various sources. However, this experience proved suboptimal because it required engineers to write Java or Python code using complex APIs. Hence, Kaito seeks a solution that offers SQL as the primary interface.
PostgreSQL is a widely-used database that many engineers have encountered during their careers. Being compatible with PostgreSQL, Risingwave presents no obstacles for onboarding new users. This choice not only reduces the learning curve and speeds up the development process but also makes it easier for Kaito to find candidates with SQL skills.
Risingwave doesn't compromise on expressiveness either. It offers Java, Python, and Rust User-Defined Functions (UDFs) to handle the "5% of cases" where pure SQL may fall short.
Interoperability
Third-party tools and client libraries can seamlessly connect to Risingwave as if it were PostgreSQL. This capability is crucial for Kaito since it relies on a variety of managed services and open-source tools to develop its products. Without leveraging existing ecosystems, integrating Risingwave with other systems would necessitate extensive custom adapters or plugins, increasing complexity and development effort for both Risingwave and Kaito.
Deliveries

The image above provides insight into a segment of Kaito's architecture, with a specific focus on its integration with Risingwave.
In this configuration, crawlers actively aggregate data from various sources in real-time. Subsequently, this data is directed to two distinct destinations: Kinesis for real-time pipeline processing and S3 for backup and future backfilling purposes.
Risingwave, in turn, ingests real-time data from Kinesis and undertakes essential tasks such as data cleaning, enrichment, and the generation of data suitable for downstream pipelines.
Real-time Alerts
Users define custom criteria, which are then translated into SQL queries and transformed into 'create sink' streaming jobs within Risingwave. The filtered results are sent to Kinesis, and Kaito utilizes Lambda Functions to further distribute these results to various destinations.
Transformation and Indexing for OpenSearch
Given the diverse formats and varying quality of raw data from different sources, Risingwave plays a crucial role in filtering out low-quality data, standardizing the remaining data, and indexing it to enhance search experiences within OpenSearch.
Analytical and operational Dashboards
Kaito's data engineers streamline the development of over 1000 analytical dashboards and internal operational dashboards by leveraging layers of materialized views. Risingwave's user experience closely resembles that of a conventional database like PostgreSQL.
It is essentially a free lunch for data engineers: they don’t need to change their workflow and Risingwave automatically makes all the information up-to-date with consistency.
Looking into the Future: On-chain data
Kaito's ultimate vision revolves around aggregating all the valuable Web3 data into its comprehensive search engine. While initiating with off-chain data represents a significant differentiator, Kaito's ambition extends beyond this initial phase. The belief is that combining both off-chain and on-chain data is imperative to gain a complete understanding of the rapidly evolving landscape.
For instance, consider a scenario where a whale orchestrates a pump-and-dump scheme by disseminating misinformation on social media to deceive retail users. Concurrently, the whale might engage in crypto transactions on multiple decentralized exchanges, either buying or selling assets. Having access to either off-chain or on-chain data alone would make it challenging to discern the true intentions behind these actions. However, with both sets of data available in real-time, Kaito’users can respond in a more calculated and informed manner.
The fusion of both data types also holds immense value for retrospective analysis. Currently, reviewing a decentralized exchange's developments, social engagement, and transaction volume over the past year necessitates a labor-intensive process. It typically involves scouring news sources like CoinDesk, collecting relevant tweets on Twitter, and examining daily transaction volume dashboards on platforms like Dune. Collating and chronologically arranging this information manually is far from ideal.
Therefore, Kaito's next strategic step is to integrate on-chain data into its AI search engine. Risingwave will once again play a pivotal role in ingesting, cleaning, transforming, enriching, and aggregating on-chain data.
Kaito's continued investment in Risingwave is not only because it's already integrated into their tech stack, but also because Risingwave has developed domain-specific features tailored for handling on-chain data. For example, Risingwave natively supports crypto-related data types and functions, such as int128 and hex_to_decimal. Risingwave is also capable of operating on JSON data in a schemaless manner, and since on-chain data fetched from full nodes are primarily in JSON format, this aligns seamlessly.
Risingwave eagerly anticipates contributing to Kaito's on-chain data analysis, unlocking new use cases for traders, researchers, and investors in the process.
TESTIMONIAL
“At Kaito, timely and accurate information holds immense value for our business. We cater to a discerning audience of sophisticated traders, investors, and quantitative trading firms, all of whom have come to rely on the real-time analytics and low-latency alerts provided by Risingwave as integral components of their decision-making processes. The remarkable speed at which Risingwave enables us to ship new features is so impressive that our data engineers simply can’t do without it.”
– Hu Yu, Founder/CEO of Kaito AI





Top comments (0)