A lot of factors can affect the performance of a Deep Neural Network. Let’s see how we can set up a PyTorch pipeline for Image augmentation (with help of Albumentations Python library), and use visualization to find any potential issue before it costs you time and money.
In software development when something is wrong, usually we get an error, but with data science this is not the case. If the model is not performing well, then the general approach is to alter the model architecture or tune hyperparameters and train more. Yes, these are good options, but making sure that the data is correct should be the priority.
From the television series The Newsroom1:
The first step in solving a problem is to recognize that it does exist.
Difference in train vs test data is the single biggest reason for low performing models. Image augmentations help to fight overfitting and improve the performance of deep neural networks for computer vision tasks. In this post, we will cover the following:
- Overview of Computer Vision Tasks
- Computer Vision Pipeline
- Image Augmentation using Albumentations
- Visualize DataLoaders
If you are familiar with Computer Vision tasks and Pytorch, then feel free to skip the first two.
Overview of Computer Vision Tasks
Common types of Computer Vision (CV) tasks are:
- Image Classification
- Image Segmentation
- Object Detection
If you are not familiar with the difference between them, then check out the post - Image Classification vs. Object Detection vs. Image Segmentation by. Image augmentations help to make the model generalize better for all 3 types CV tasks.
Computer Vision Pipeline
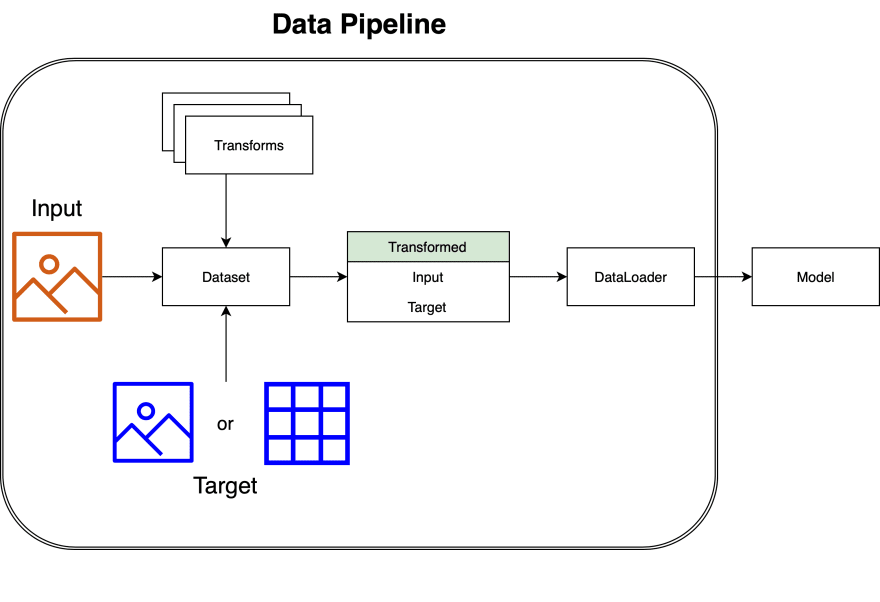
Both Input and Target data has to go through Dataset and DataLoader before being passed on to the model for training. It is better to visualize the output of the DataLoader. By this way, we can also identify when there is an issue with the Dataset definition. In relation to the above data pipeline diagram, only Target data type and Transformations applied differs based on CV task type.
Image Augmentation using Albumentations
Albumentations is a fast and flexible image augmentation library. It supports both PyTorch and Keras. Torchvision library is good but when it comes to Image Segmentation or Object Detection, it requires a lot of effort to get it right. To elaborate, Pixel-level and Spatial-level are two types of image augmentations. The way of applying transformations to input data and target label differs for these two types.
Pixel-level augmentations:
Changes the values of pixels of the original image, but they don't change the output mask. Image transformations such as changing brightness or contrast of adjusting values of the RGB-palette of the image are pixel-level augmentations. We modify the input image by adjusting its brightness, but we keep the output mask intact.
![]()
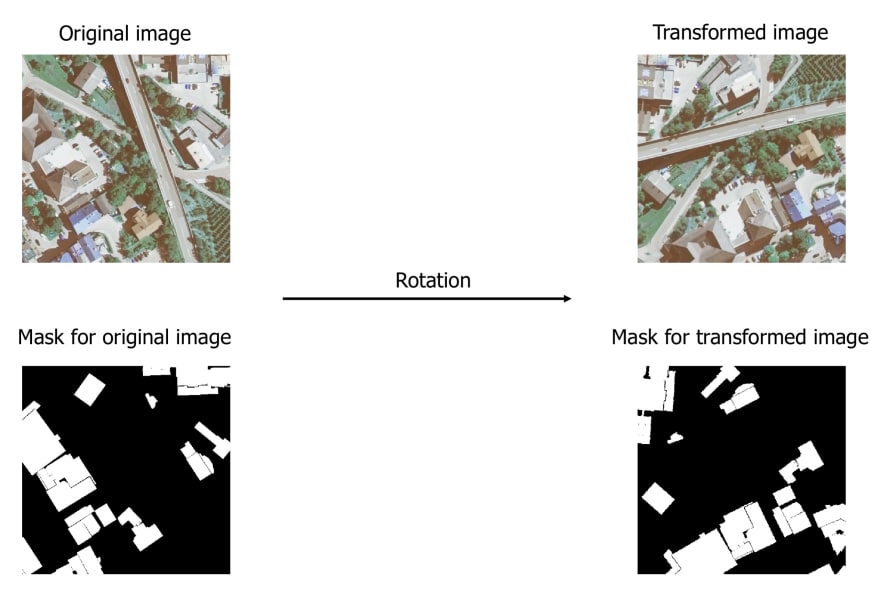
Spatial-level augmentations:
Changes both the image and the mask. When you apply image transformations such as mirroring or rotation or cropping a part of the input image, you also need to apply the same transformation to the output label to preserve its correctness.
Brownie Points
- Ability to add image augmentations to any computer vision pipeline with minimal effort.
- Syntax for transforms declaration is very similar to Torchvision.
- Lets you set the required probabilities and the magnitude of values for each transformation.
An example definition of an augmentation pipeline is as follows:
Still not convinced? Then check out the article - Why you need a dedicated library for image augmentation.
Visualize DataLoaders
Why?
Right now, probably would be wondering if Albumentations is so great then why do we need to visualize the DataLoaders. I'm glad you asked, Albumentation still requires user input, and we are not that great at providing correct values2. Any rational person should think about the type of augmentation and whether it is applicable to a particular dataset or not but often this is not the case.
It is better to visualize just to avoid any surprises.
When Rotation transformation is applied to the digit 9 from MNIST dataset, it can be transformed to 6, but the label would still say 9. See how easy it is to screw up data augmentation.?
| Original Image - 9 | Transformed Image - 9 |
|---|---|
 |
 |
How?
Torchvision functions like make_grid and draw_bounding_boxes are quite handy, but they are not end to end. So we will write sort of wrappers which take in the iter object of the DataLoaders and plot the Input and Target data values.
Notes about the below code:
PyTorch Tensor expects image of shape (C x H x W) which is the reverse when compared to NumPy array shape (H x W x C).
Image data must be torch tensor of
floatdata type to train the model, whereas for plotting it should be of typeuint8.It is best practice to avoid multiple initialization of the
iterobject for DataLoaders when possible as it is very time-consuming. This is the reason for taking theiterobject as function parameter instead of DataLoader itself.
Once again, The focus is on the output of DataLoaders, if you are interested in the overall data pipeline then check out this Colab Notebook
Image Classification
Dataset 👉 CIFAR10
Transforms 👉 Resize ➡️ Rotate ➡️ Horizontal Flip

Image Segmentation
Dataset 👉 CAMVID
Transforms 👉 Resize ➡️ Rotate ➡️ Horizontal Flip

Object Detection
Dataset 👉 Penn-Fudan Database for Pedestrian Detection
Transforms 👉 Resize ➡️ Horizontal Flip ➡️ Brightness & Contrast ➡️ Shift, Scale & Rotate

Conclusion
In Computer Vision, it is relatively easier to grasp what the model is doing. How it does something is a different story, but with enough experiments we can sort of guess what is working and what is not. The key is to figure this out with minimal number of experiments. The more confident we are in the data pipeline setup, more time to run various experiments to improve the model performance.
Side Notes:
[1]: I believe that the quote from The Newsroom is adopted from the below qoute by Zig Ziglar, but I am not too sure.
You cannot solve a problem until you acknowledge that you have one and take responsibility for solving it.
[2]: I am aware of AutoAlbument but I am yet to give it a go.




Top comments (0)