Ferramentas necessárias:
Para iniciarmos nossa aplicação, será necessário preparar o ambiente local para termos acessos as tecnologias utilizadas, vamos utilizar a magia do Docker e rodar o kafka, activemq, elasticsearch com kibana para visualizarmos dados do elasticsearch, redis e postgres.
Crie uma pasta com o nome a seu gosto e dentro da mesma crie outra pasta com o nome de ambiente, dentro da pasta ambiente crie um arquivo com o nome docker-compose.yaml e dentro deste arquivo copie o seguinte codigo.
version: '3'
services:
mqseries:
image: ibmcom/mq:latest
ports:
- "1414:1414"
- "9443:9443"
hostname: mq
environment:
- LICENSE=accept
- MQ_QMGR_NAME=QM1
- MQ_ADMIN_PASSWORD=admin
container_name: mqserver
stdin_open: true
tty: true
restart: always
mq:
image: rmohr/activemq
container_name: mq
ports:
- 8161:8161
- 61616:61616
- 5672:5672
- 1883:1883
- 61613:61613
zookeeper:
image: "confluentinc/cp-zookeeper:5.2.1"
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ZOOKEEPER_SYNC_LIMIT: 2
kafka:
image: "confluentinc/cp-kafka:5.2.1"
ports:
- 9092:9092
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:29092,PLAINTEXT_HOST://localhost:9092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: "1"
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "true"
postgres:
image: 'postgres:alpine'
volumes:
- postgres-volume:/var/lib/postgresql/data
ports:
- 5432:5432
environment:
POSTGRES_USER: bootcamp
POSTGRES_PASSWORD: password
POSTGRES_DB: bootcamp
POSTGRES_HOST: postgres
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.3.1
container_name: elasticsearch
environment:
- node.name=ws-es-node
- discovery.type=single-node
- cluster.name=ws-es-data-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms1024m -Xmx1024m"
# - xpack.security.enabled='false'
# - xpack.monitoring.enabled='false'
# - xpack.watcher.enabled='false'
# - xpack.ml.enabled='false'
# - http.cors.enabled='true'
# - http.cors.allow-origin="*"
# - http.cors.allow-methods=OPTIONS, HEAD, GET, POST, PUT, DELETE
# - http.cors.allow-headers=X-Requested-With,X-Auth-Token,Content-Type, Content-Length
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- vibhuviesdata:/usr/share/elasticsearch/data
ports:
- 9200:9200
- 9300:9300
networks:
- esnet
kibana:
image: docker.elastic.co/kibana/kibana:7.3.1
container_name: kibana
environment:
SERVER_NAME: 127.0.0.1
ELASTICSEARCH_HOSTS: http://elasticsearch:9200
# XPACK_GRAPH_ENABLED: false
# XPACK_ML_ENABLED: false
# XPACK_REPORTING_ENABLED: false
# XPACK_SECURITY_ENABLED: false
# XPACK_WATCHER_ENABLED: false
ports:
- "5601:5601"
networks:
- esnet
depends_on:
- elasticsearch
restart: "unless-stopped"
redis:
image: 'bitnami/redis:latest'
ports:
- 6379:6379
environment:
- ALLOW_EMPTY_PASSWORD=yes
volumes:
grafana-volume:
prometheus-volume:
postgres-volume:
vibhuviesdata:
driver: local
networks:
esnet:
Agora dentro da pasta ambiente execute o seguinte comando docker-compose up -d
Dentro do console docker você devera visualizar os containers rodando para cada tecnologia que utilizaremos.

Agora vamos utilizar o spring starter para criar nossa primeira estrutura de API.
Feito isso, vamos configurar nosso tópico kafka que ira produzir a mensagem através do arquivo de properties da aplicação, defina o arquivo de application.yml igual o código abaixo.
#APP SPECIFIC CUSTOM PROPERTIES
order:
topic: cadastra-usuario
#SPRING PROPERTIES
spring:
kafka:
bootstrap-servers: localhost:9092
#properties:
#Server host name verification is disabled by setting ssl.endpoint.identification.algorithm to an empty string
#ssl.endpoint.identification.algorithm:
#ssl:
# protocol: SSL
# trust-store-location: classpath:/app/store/truststore.jks
# trust-store-password: <TURST_STORE_PASSWORD>
# key-store-location: classpath:/app/store/keystore.jks
# key-store-password: <KEY_STORE_PASSWORD>
# key-password: <KEY_PASSWORD>
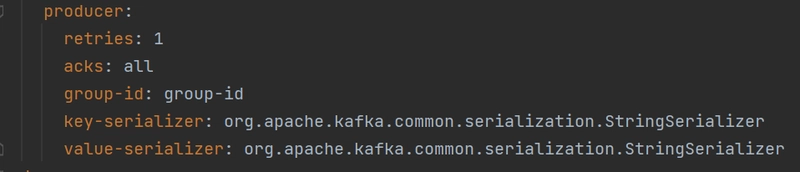
producer:
retries: 1
acks: all
group-id: group-id
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
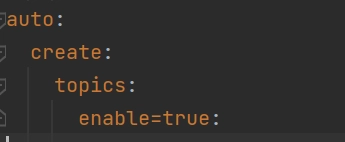
auto:
create:
topics:
enable=true:
Vamos entender estas configuraçoes:
- Definição do nome do topico kafka onde a mensagem sera produzida.

- Definição do endpoint de acesso ao kafka.
 Obs: Por ser localhost não será necessário configurarmos o certificado ssl, porem deixamos as configs comentada.
Obs: Por ser localhost não será necessário configurarmos o certificado ssl, porem deixamos as configs comentada. - Configurações do producer kafka como o tipo de serialização que a mensagem sera produzida, no caso utilizaremos String, quantidades de tentativas para produzir esta mensagem e o id identificador de um grupo de producers.
- Habilita a auto criação de um topico kafka
Documentação api de producer do kafka
Após isto criamos uma classe controller que ira receber a requisição e chamar um serviço de salvar usuário responsável por produzir e enviar os dados do usuário como mensagem, segue o link do github onde a aplicação esta armazenada para que possam conferir.

Top comments (0)