
- Initial thoughts
- Time spent handling cache
- Topologies without autoscaling
- Topologies with autoscaling
- Wrapping up
- Further reading
Initial thoughts
GitLab runner can be installed virtually anywhere, on your local personal computer whatever the OS, even on a Raspberry Pi.
That being said, only a handful of topologies are really viable for professional use. Let's introduce them and elaborate on pros and cons.
This blog post focuses only on container executors (Docker, Docker Machine, Kubernetes) which are broadly used. But it partially applies to other executors.
Time spent handling cache
Cache is hell of a subject as a CICD Engineer, one for which you can loose a tremendous amount of time tweaking for performance.
To understand some pros and cons discussed in topologies, we should be aware of the whole caching process in GitLab. We assume here cases where jobs are all using cache and all pulling and pushing it.
When remote cache is not configured, the process is:
- unzip local cache from past jobs/pipelines (if any)
- run the job scripts
- zip produced cache for future jobs/pipelines
When remote cache is configured, the process is:
- download remote cache from past jobs/pipelines (if any)
- unzip cache (if downloaded)
- run the job scripts
- zip produced cache
- upload produced cache for future jobs/pipelines
Without autoscaling, when infrastructure is undersized, some jobs have also to wait for available hardware resources.
On autoscaling infrastructure, when current resources are not enough, some jobs have also to wait for new servers to spin up.
The official documentation is pretty straightforward ; for runners to work with caches efficiently, you must do one of the following:
- Use a single runner for all your jobs. At least the similar ones
- Use multiple runners that have distributed caching, where the cache is stored in S3 buckets. Shared runners on GitLab.com behave this way. These runners can be in autoscale mode, but they don’t have to be
- Use multiple runners with the same architecture and have these runners share a common network-mounted directory to store the cache. This directory should use NFS or something similar. These runners may be in autoscale mode

Topologies without autoscaling
No autoscaling means that physical resources are reserved upfront and are, by definition, limited. Several of those topologies are viable. And they all share some pros and cons. Some cons can be mitigated.
Pros:
- Simple topology
- Predictable cost
- No runtime consumed by spinning new servers
Cons:
- Hard limit capacity
- Mitigators: better/faster/stronger server (vertical scalability) or more servers (horizontal scalability)
- Constant cost even when not used
- Mitigator: Stopping servers outside working hours
Classic single server
A single GitLab runner on a server, able to run multiple jobs locally.
Pros:
- Simple architecture
- Fastest GitLab and Docker cache (local)
- Easy to install and configure
Cons:
- Local cache is not guaranteed with multiple jobs in parallel
- Mitigator: Mounting the cache folder
Multiple fixed servers
The single GitLab runner can be extended to multiple servers, each one having a separate installation of a GitLab runner.
Pros:
- some form of (manual) scalability
- ability to customize job target
- ability to mitigate cache reliability with runner tags
Cons:
- Scalability is not manual
- Mitigator: infra-as-code
- Unreliable cache when remote cache is not configured
- Mitigator: define tags on servers to guarantee local cache (one for Node jobs, one for Spring jobs, etc.)
- Alternative mitigator: share a common network-mounted directory as stated in GitLab documentation about caching
Kubernetes runner on fixed size cluster
Kubernetes runner is a highly viable way of leveraging unused physical resources on existing Kubernetes clusters.
Pros:
- Uses available resources on existing cluster
Cons:
- Can slow down applications on shared nodes
- Costly if the cluster is only used by GitLab runners
- mitigators: use of preemptible nodes on Cloud providers

Topologies with autoscaling
Autoscaling means that physical resources are reserved when needed, with virtually no physical limit. Most of those topologies are viable. And, like for the previous category, they share some pros and cons. Some cons can be also mitigated.
Pros:
- Virtually no physical limit
- No cost when not used
Cons:
- Time consumed by spinning new servers
- Highly unreliable local GitLab and Docker cache
GitLab shared runners
GitLab shared runner are there for everyone, fully managed by GiLab and consumed in the form of CICD minutes.
Pros:
- No maintenance
- Very reasonable price per minute
Cons:
- Notably slow
- No local cache
Kubernetes runner on node autoscaling cluster
Kubernetes runner is a highly viable way of leveraging autoscaling capabilities on existing Kubernetes clusters.
Pros:
- Uses available resources on existing cluster
- At company scale, a dedicated autoscaling cluster becomes cost-efficient
Cons:
- Can slow down other applications on shared nodes
- Mitigator: use pods/nodes affinity/anti-affinity and/or limit-ranges/quotas
- Spinning new nodes slows down the pipelines
- Mitigator: over-provision your cluster by one or two nodes
Docker machine on Amazon EC2
GitLab can leverage AWS infrastructure to install autoscaling GitLab Runner on AWS EC2. The architecture is pretty simple: a tiny VM is responsible for spawning spot instances when needed.
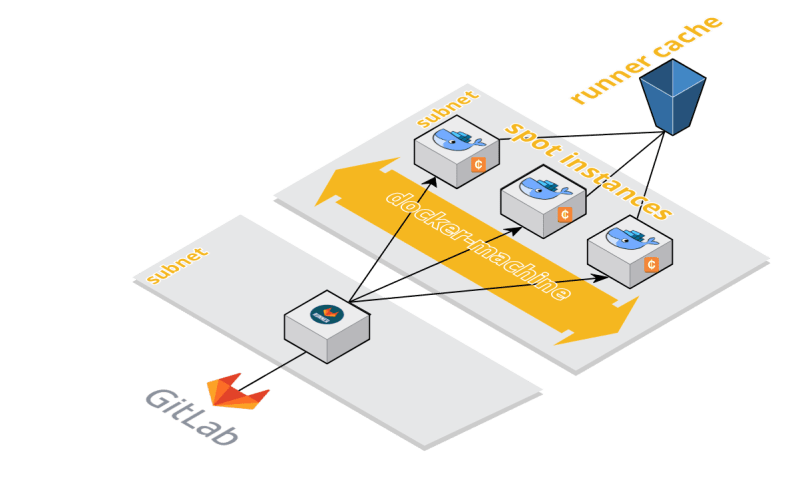
It can be easily installed using infra-as-code with a Terraform repo.
Pros:
- cost-efficient
Cons:
- Spinning new VMs slows down the pipelines
- Vendor dependant on AWS
Docker machine on AWS Fargate
Similarly, GitLab can leverage AWS infrastructure to install autoscaling GitLab CI on AWS Fargate. Architecture is straightforward, with the serverless capabilities of the Fargate service.
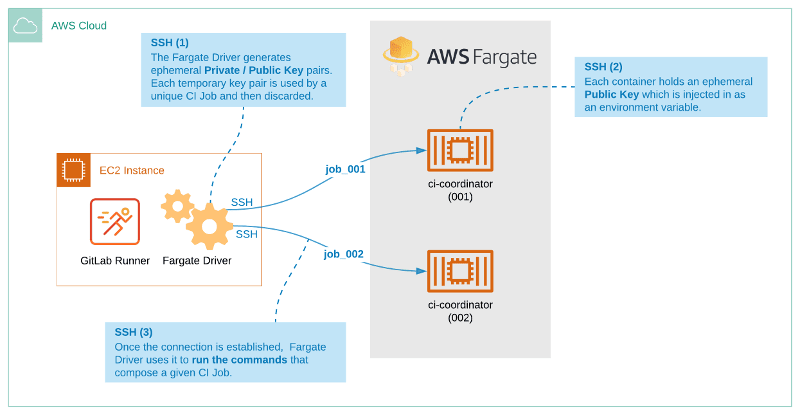
Pros:
- cost-efficient
Cons:
- Spinning new VMs slows down the pipelines
- Vendor dependant
Wrapping up
What is the best topology ? As always, no silver bullet, it depends on a lot of constraints.
Here are opinionated recommendations for some scenarios:
- Any context on gitlab.com where slow CICD is (really) not an issue:
- GitLab shared runners
- GitLab CI local or remote training sessions, with 6 to 8 students working in parallel on individual projects (similar to Zenika GitLab training):
- Dedicated single cloud VM with enough disk IO
- Structure with a single developers team, mono or multi-repo:
- Dedicated single cloud VM with enough disk IO
- Multi-teams company with knowledge and access to Cloud managed Kubernetes infrastructure:
- Dedicated Kubernetes runner on node autoscaling cluster
- Multi-teams company without Kubernetes knowledge:
- Docker machine on Amazon EC2 or Per team dedicated single cloud VM with enough disk IO
- Multi gigabytes jobs cache (Spring, Node, etc.):
- Dedicated single stateful cloud VM with enough disk IO and custom mounted local cache
And you ? What are your favorite runners topologies ?
If you experienced other scenarios and/or have different opinions, please share in the comments 🤓

Illustrations generated locally by Automatic1111 using RevAnimated model with ManyPipesAI LoRA






Top comments (0)