When explaining the YugabyteDB high availability, where changes in table and index tuples are replicated through the Raft consensus protocol, I often get a question asking about Patroni which orchestrate the failover though etcd, using the Raft protocol, and exposing the Primary and Standby as Leader and Follower. But there's a difference. PostgreSQL replication is built on top of the monolithic database and Patroni replicates the status of the instances, but not data. YugabyteDB distributes and replicates data, locks, and transactions though the Raft protocol.
I did a quick test of PostgreSQL failover with Patroni, and it is actually the first time I look at it so, please, comment if I missed something. I start a Patroni lab with the docker-compose.yml provided in the project:
git clone https://github.com/zalando/patroni.git
cd patroni
docker build -t patroni .
docker-compose up -d
By default, Patroni is configured for data loss failover. I set the maximum protection as documented: synchronous replication and strict synchronous mode:
docker exec -i demo-patroni1 patronictl edit-config --apply - --force <<'JSON'
{
synchronous_mode: "on",
synchronous_mode_strict: "on",
"postgresql":
{
"parameters":{
"synchronous_commit": "on",
"synchronous_standby_names": "*"
}
}
}
JSON
docker exec -it demo-patroni2 patronictl show-config
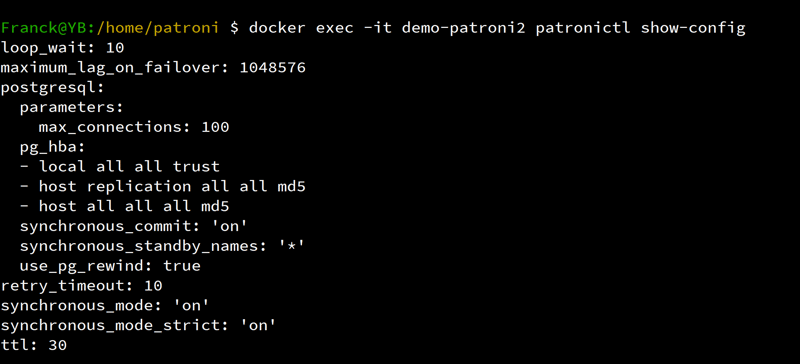
I order to get a reproducible state that you copy/paste, where demo-patroni1 is the Leader, I switchover to patroni1:
docker exec -it demo-patroni1 patronictl switchover --candidate patroni2 --force
docker exec -it demo-patroni1 patronictl switchover --candidate patroni1 --force
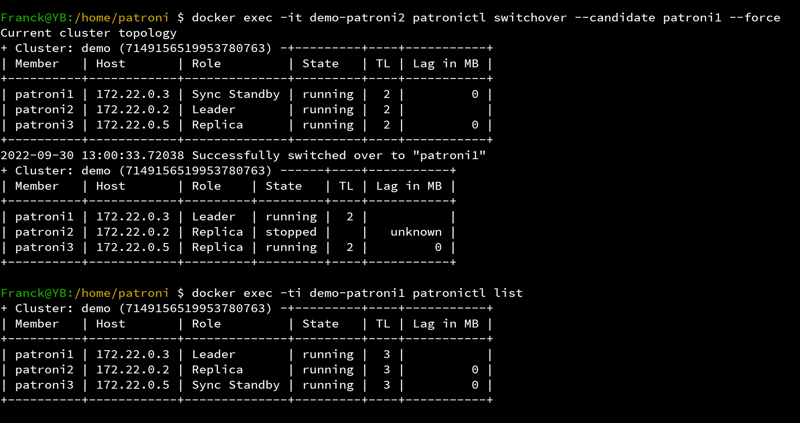
Here is my state:
Franck@YB:~ $ docker exec -ti demo-patroni1 patronictl list
+ Cluster: demo (7149156519953780763) -+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+------------+--------------+---------+----+-----------+
| patroni1 | 172.22.0.3 | Leader | running | 3 | |
| patroni2 | 172.22.0.2 | Replica | running | 3 | 0 |
| patroni3 | 172.22.0.5 | Sync Standby | running | 3 | 0 |
+----------+------------+--------------+---------+----+-----------+
Franck@YB:~ $ docker exec -ti demo-patroni1 etcdctl member list
1bab629f01fa9065: name=etcd3 peerURLs=http://etcd3:2380 clientURLs=http://172.20.0.3:2379 isLeader=false
8ecb6af518d241cc: name=etcd2 peerURLs=http://etcd2:2380 clientURLs=http://172.20.0.7:2379 isLeader=false
b2e169fcb8a34028: name=etcd1 peerURLs=http://etcd1:2380 clientURLs=http://172.20.0.6:2379 isLeader=true
On one terminal, I'll run a query that increases a counter:
docker exec -i demo-patroni1 psql <<'SQL'
create table demo as select 1 n;
update demo set n=n+1 returning n;
\watch 0.001
SQL
It displays the last value, updated and committed.
From another terminal, I simulate a network partition that isolates the primary:
docker network disconnect patroni_demo demo-patroni1
TZ= date
This shows the timestamp, in order to get an idea of the Recovery Time Objective (RTO):
Franck@YB:/home/patroni $ docker network disconnect patroni_demo demo-patroni1
Franck@YB:/home/patroni $ TZ= date
Fri Sep 30 09:48:54 GMT 2022
Here is what happens on the primary:
Fri Sep 30 09:48:53 2022 (every 0.001s)
n
------
1103
(1 row)
WARNING: terminating connection due to immediate shutdown command
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
connection to server was lost
This is good, the failure was detected immediately. This is thanks to the synchronous replication. Without it, in the default Patroni configuration, the primary would have accepted many writes (up to maximum_lag_on_failover), which would have been lost after a failover.
So here we are, with the new primary being patroni2 and patroni1 out of the cluster:
Franck@YB:~ $ docker exec -ti demo-patroni2 patronictl list
+ Cluster: demo (7149156519953780763) -+---------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+------------+--------------+---------+----+-----------+
| patroni2 | 172.22.0.2 | Sync Standby | running | 4 | 0 |
| patroni3 | 172.22.0.5 | Leader | running | 4 | |
+----------+------------+--------------+---------+----+-----------+
Let's check our counter from the new primary, and the remaining standby:
Franck@YB:~ $ docker exec -i demo-patroni3 psql -c "
select * from demo
"
n
------
1104
(1 row)
Franck@YB:~ $ docker exec -i demo-patroni2 psql -c "
select * from demo
"
n
------
1104
(1 row)
🤔 I have no update running anymore. The latest committed result was 1103 and now after failover I see that 1104 that was committed on the standby before the primary. If it were a banking transaction where a customer withdraws at the ATM, it would mean that he was debited without getting his money. I got an invisible commit.
I tried to get a better name for it, I like this one:
Note that the network between the client psql and the server was never cut: I'm running psql locally in the container. The connection was terminated, before the commit acknowledgement, by Patroni to reinstate the database. This means that the application has to handle it in some ways - the failover is not transparent even when automated.
Now let's insert a new row and check again this
Franck@YB:/home/patroni $ docker exec -i demo-patroni3 psql -c "
insert into demo values(42)
"
INSERT 0 1
Franck@YB:/home/patroni $ docker exec -i demo-patroni3 psql -c "
select * from demo
"
n
------
1104
42
(2 rows)
This works, even when patroni1 is down because patroni2 is still there in Sync. That's correct because you don't want to block the primary when only one standby is down.
However, the read replica that is isolated from the network is still up but gives stale results:
Franck@YB:/home/patroni $ docker exec -i demo-patroni1 psql -c "
select * from demo;
select pg_is_in_recovery();
"
n
------
1104
(1 row)
pg_is_in_recovery
-------------------
t
Apparently, the value 1104 was finally committed locally, and is visible now that the old primary is reinstate to its standby mode. But this doesn't matter because it is now missing the new changes (the additional row) until the network is back.
🤔 Even in a synchronous mode, the read replicas are only eventually consistent, and have no way to know how many transactions they miss. This is a read split brain which is less problematic than a write split brain, but you should be careful when querying read replicas.
Now, lets come back to the question about the usage of the Raft protocol with Patroni and with YugabyteDB.
PostgreSQL streaming replication and Patroni DR automation are great features. The Raft consensus is used to replicate the status of the cluster, but not the transactions itself. The state of the replicas can be different and still activated to process reads and writes. With YugabyteDB, in addition to the leader election, the Raft log is used to distribute and replicate all writes. A new leader will continue on same state as the previos one. The session always read and write from the tablet leader to guarantee consistent transaction even across failures. It is possible to read from the followers, to lower the latency in geo-distributed deployments, but it is not a requirement to scale-out because the leaders are automatically distributed across the cluster.





Top comments (0)