
As much as every company dreams of cloud operations running perfectly all the time, as even junior operations people know the reality is there are issues, things break, and they have to be dealt with constantly. Savvy operations teams prepare for this eventuality and together with industry leading incident management, incident response and incident remediation tools are able to minimize user facing issues and especially dreaded downtime.
This is where a modern incident management & response platform like Squadcast comes to the rescue, helping organizations in their journey to deliver super-reliable services. Organizations can quickly and easily adopt Site Reliability Engineering (SRE) practices to improve their incident resolution metrics and ultimately, the reliability of their systems.
The first step towards doing better incident management is adding enough context to incidents while they get detected. With Squadcast, teams can discover everything they need, to take action and achieve best-in-class MTTD (Mean Time To Detect) with highly configurable features like [alert deduplication and tagging(https://www.squadcast.com/effective-on-call-and-incident-response), thus facilitating on-call teams to streamline high-priority alerts and stay productive. Teams can also collaborate in real-time with virtual incident war rooms on Squadcast to get the right responders virtually in one place making operations transparent.
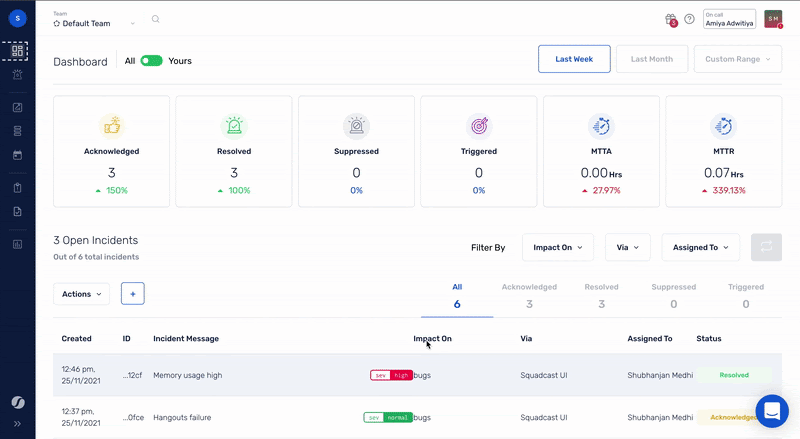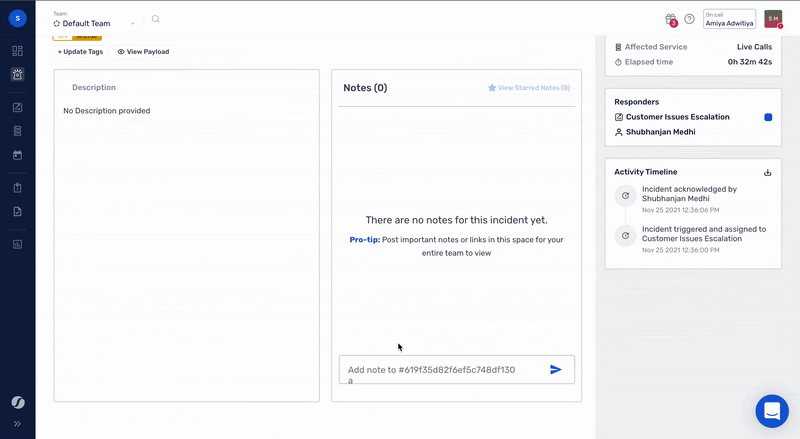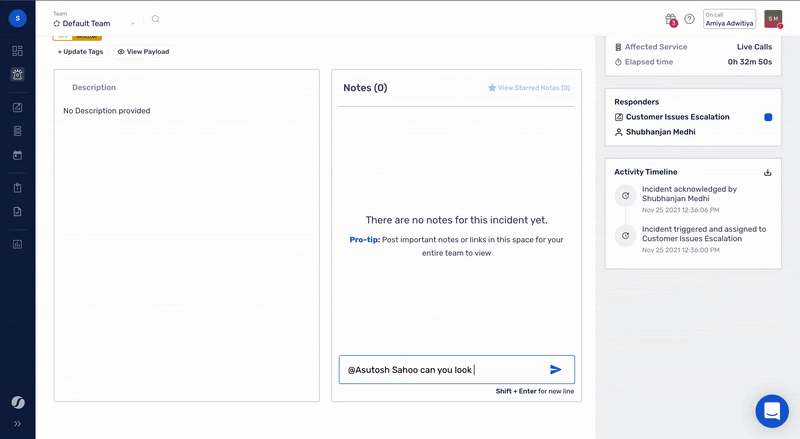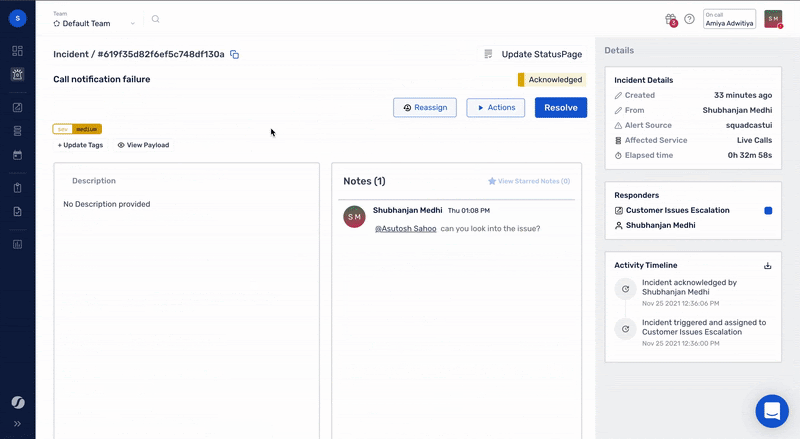
Obviously the story doesn’t end once an incident has been created, routed and enriched. The incident still needs to be remediated. This is where Fylamynt steps in as the perfect compliment to Squadcast. Fylamynt provides a no-code, drag and drop interface for building workflows (runbooks) that can be triggered by a number of ways, including a Squadcast incident.
Fylamynt integrates with over 40 commonly used tools for dealing with cloud operation incidents, handling all the API calls and the end result is a fully or partially automated workflow that will run in a consistent manner every time.
Workflow as Code
We call this “workflow as code” because our user interface gets out of your way and lets you switch seamlessly between drag-and-drop and coding scripts in Python and JSON, without loss of information.
You can select from a comprehensive library of connectors and automated actions to connect any part of your cloud. You can select from a list of actions to create a workflow to solve a specific business task such as fixing an incident that caused the website to be down.

By automating the parts of the workflow that are the most tedious and time consuming, SRE teams can focus their expertise where it’s needed to make those critical decisions. We call this “human in the loop” and this causes the workflow to pause and can send a message through slack or otherwise. The SRE can then click a link and have all the needed information at their fingertips, allowing them to quickly make the decision on what to do next (could be transferring traffic to a new instance or destroying an instance that was spiking CPU).
Another added benefit of defining and automating your workflows is that less experienced support engineers can handle more issues, freeing time for the more senior staff as well as repairing issues more quickly.
Fylamynt also provides a dashboard that shows all executed and currently executing workflows, with tons of detail about every step that ran, what the inputs and outputs were and what branches and actions were taken.
At this point you can pop back into Squadcast to handle your incident postmortem — the next logical step after any incident is to dissect and analyze the why, how and the what of the incident. Squadcast’s incident postmortem feature helps build an insightful timeline in a matter of minutes. This is especially useful as automation ensures that you can quickly have a system-generated postmortem for pretty much any incident.
One of the core principles of SRE is Transparency and Squadcast’s Status Page helps you communicate to customers and stakeholders with real-time updates. By configuring your public-facing services and their dependent components, you can show their status in real-time directly within Squadcast.
Squadcast’s native mobile application also helps in triggering remediations from anywhere. Teams can also connect via APIs to enhance incident response by bringing their entire toolchain into one platform.
Together Squadcast and Fylamynt provide the end-to-end solution for handling cloud operations incidents, helping your end users to experience a consistently delightful application experience. Teams can practice site reliability engineering through better Incident Management to proactively respond, resolve, and learn from every incident.
Squadcast is an incident management tool that’s purpose-built for SRE. Your team can get rid of unwanted alerts, receive relevant notifications, work in collaboration using virtual incident war rooms, and automate repetitive tasks to eliminate toil. Organisations can quickly and easily adopt Site Reliability Engineering practices to improve their incident resolution metrics and ultimately, the reliability of their systems.
Fylamynt has created the world’s first low code incident response and remediation platform for building, running and analyzing SRE cloud workflows. With Fylamynt an SRE can automate the parts of the runbook that are the most time consuming, allowing them to make decisions where their expertise is needed.





Top comments (0)