If you are a developer working alone, or on a personal project you might not had to worry about the intricacies of the Identity and Access Management (IAM) system and how it works with the system of Role-Based Access Control (RBAC) in Kubernetes. This is because, in most cases, your cloud provider automatically maps your default IAM account (the one you may have used to create the cluster) to some group within your cluster with admin privileges (more on this later).
 on [Unsplash](https://unsplash.com?utm_source=medium&utm_medium=referral)](https://res.cloudinary.com/practicaldev/image/fetch/s--n5xOGcKn--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/6000/0%2AlUAAZsmi868OmSJ4)
However, once you have multiple IAM roles or users in your organization, it becomes important to understand how each role translates to permissions within your Kubernetes cluster. In this article, I’ll walk you through all that you need to know about these two systems, how they work together and what goes on inside the hood! We’ll use AWS throughout the article but the concepts apply to all providers.
Kubernetes RBAC
While working with Kubernetes, you might have come across roles (or cluster roles) and role bindings (or cluster role bindings). These resources allow you to exert access control over other resources on your cluster. To recap,
- An RBAC Role or ClusterRole contains rules that represent a set of permissions. Permissions are purely additive (there are no “deny” rules). This is what a role looks like:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
namespace: default
name: pod-reader
rules:
- apiGroups: [""] # "" indicates the core API group
resources: ["pods"]
verbs: ["get", "watch", "list"]
You can have permissions that allow specific operations on a set of Kubernetes resources as part of a role definition. It’s a really flexible and simple way to allow selective control of your cluster to users.
- A role binding grants the permissions defined in a role to a user or set of users. It holds a list of subjects (users, groups, or service accounts), and a reference to the role being granted. This is what a role-binding looks like:
apiVersion: rbac.authorization.k8s.io/v1
# This role binding allows the group system:serviceaccounts to read pods
# in the "default" namespace.
# You need to already have a Role named "pod-reader" in that namespace.
kind: RoleBinding
metadata:
name: read-pods
namespace: default
subjects:
# You can specify more than one "subject"
- kind: Group
name: system:serviceaccounts
apiGroup: rbac.authorization.k8s.io
roleRef:
# "roleRef" specifies the binding to a Role / ClusterRole
kind: Role # this must be Role or ClusterRole
name: pod-reader # this must match the name of the Role or ClusterRole you wish to bind to
apiGroup: rbac.authorization.k8s.io
Here, we are granting the role pod-reader to the group system:serviceaccounts.
Coming to “subjects”

There are two ways in which the Kubernetes API is accessed.
Users
Service Accounts
Users are the humans who access the API, validated by some certificates. The service accounts on the other hand are used by the pods inside the cluster to access other resources.
A group is just the organization name for a particular user and is set when the user is being created. You can learn more about this here, but it is thankfully, not a prerequisite for the remainder of the article.
AWS IAM
So now, you have certain users or groups in k8s that can perform certain specified actions in the cluster. Sounds good, but where does the AWS IAM users/roles fit in? So far, we’ve acted in a way that assumes these entities don’t even exist.

From Amazon’s guide on cluster authentication,
Amazon EKS uses IAM to provide authentication to your Kubernetes cluster… … Amazon EKS uses a token authentication webhook to authenticate the request but it still relies on native Kubernetes RBAC for authorization.
If you are unclear about the differences between authorization and authentication, check out my workshop which covers this topic illustratively.
From the quote, we can infer that the IAM console and the roles defined there only control access to the Kubernetes API server. The operations that the user is then allowed to take are governed by the RBAC system of roles and role-bindings.
To understand how the two link together, we need to take a look at how authentication is actually performed.
Authentication
Kubernetes uses one of client certificates, bearer tokens, or an authenticating proxy to authenticate API requests through the use of something called an authentication plugin. In simple terms, it is the authentication server which holds information about the user and can thus tell Kubernetes if the request is valid or not. These plugins then associate your API requests with one of the following attributes which help Kubernetes better identify the user (taken from the Kubernetes docs) :
Username: a string which identifies the end user. Common values might be kube-admin or jane@example.com.
UID: a string which identifies the end user and attempts to be more consistent and unique than username.
Groups: a set of strings, each of which indicates the user’s membership in a named logical collection of users. Common values might be system:masters.
Extra fields: a map of strings to list of strings which holds additional information authorizers may find useful.
All values are opaque to the authentication system and only hold significance when interpreted by an authorizer.
Now to be more specific, let’s take a look at the Webhook Token Authentication strategy, which is also the strategy that AWS uses for its EKS clusters.
Workflow
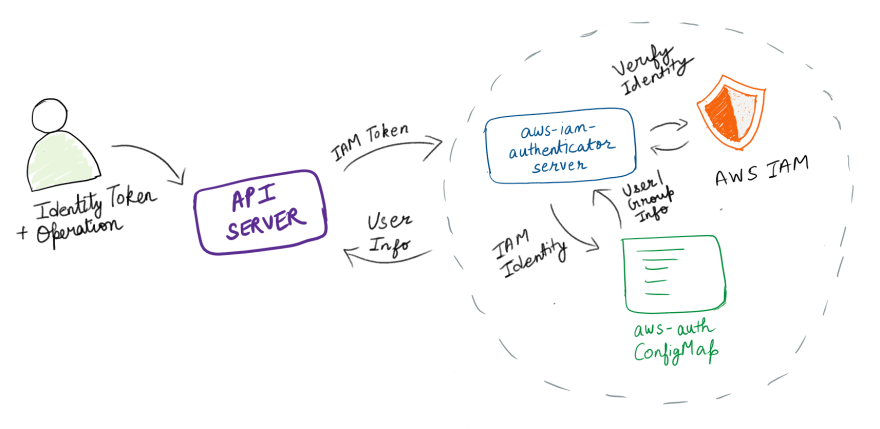
The Kubernetes API integrates with something called the AWS IAM Authenticator for Kubernetes, using a token authentication webhook. When started, it generates a webhook configuration file (which has the address of the authentication server (remote service) among other things) and then saves it onto the host filesystem.
From the docs on Webhook Token Authentication,
When a client attempts to authenticate with the API server using a bearer token…, the authentication webhook POSTs a JSON-serialized TokenReview object containing the token to the remote service.
The remote service is expected to fill the status field of the request to indicate the success of the login. The response body's spec field is ignored and may be omitted. The remote service must return a response using the same TokenReview API version that it received.
{
"apiVersion": "authentication.k8s.io/v1",
"kind": "TokenReview",
"status": {
"authenticated": true,
"user": {
# Required
"username": "janedoe@example.com",
# Optional
"uid": "42",
# Optional group memberships
"groups": ["developers", "qa"],
# Optional additional information provided by the authenticator.
# This should not contain confidential data, as it can be recorded in logs
# or API objects, and is made available to admission webhooks.
"extra": {
"extrafield1": [
"extravalue1",
"extravalue2"
]
}
},
# Optional list audience-aware token authenticators can return,
# containing the audiences from the `spec.audiences` list for which the provided token was valid.
# If this is omitted, the token is considered to be valid to authenticate to the Kubernetes API server.
"audiences": ["https://myserver.example.com"]
}
}
As you can see, the response includes information about the groups that this requester is a part of.
Authorization
As we’ve seen, access to your cluster using AWS Identity and Access Management (IAM) entities is enabled by the AWS IAM Authenticator for Kubernetes. But how does the authentication server (in this case, the AWS IAM Authenticator for Kubernetes) know what Kubernetes groups a user is a part of?
In the case of AWS, this is achieved through the use of a ConfigMap by the name of aws-auth. It looks like the following:
apiVersion: v1
data:
mapRoles: |
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:aws:iam::111122223333:role/my-role
username: system:node:{{EC2PrivateDNSName}}
- groups:
- eks-console-dashboard-full-access-group
rolearn: arn:aws:iam::111122223333:role/my-console-viewer-role
username: my-console-viewer-role
kind: ConfigMap
metadata:
name: aws-auth
namespace: kube-system
Few things to notice here,
it maps the groups in Kubernetes to the AWS IAM roles.
you can also attach groups to IAM users with the use of a “mapUsers” section along with the “mapRoles”.
The authenticator gets its configuration information from the aws-auth ConfigMap . From the GitHub repository of the aws-iam-authenticator,
The default behavior of the server is to source mappings exclusively from the mapUsers and mapRoles fields of its configuration file.
It then sends that information as part of the TokenReview. The Kubernetes API server now knows what group the requester is a part of and also what roles this group exhibits (courtesy of role-bindings) and thus it can take the decision to either allow or deny the request.
Conclusion
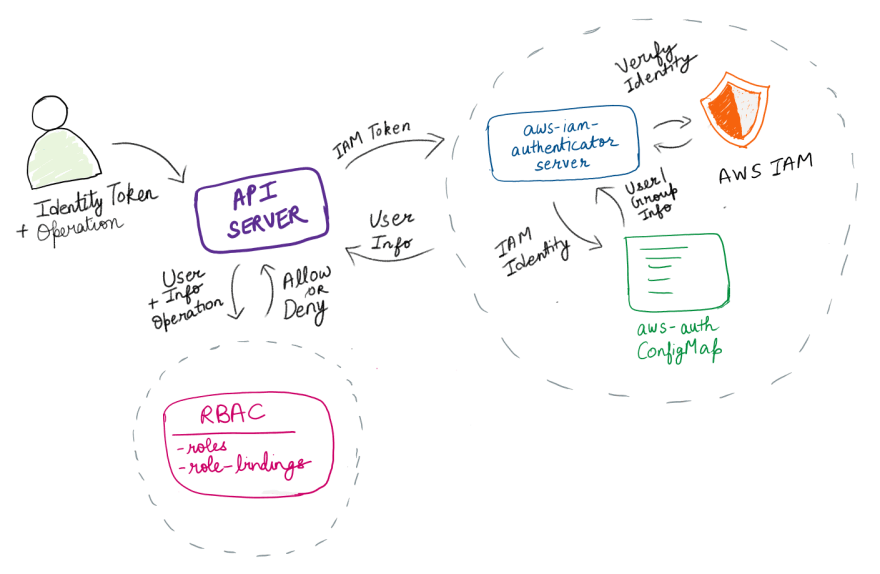
In conclusion, we have seen that the AWS IAM roles and the Kubernetes RBAC system work together to allow/deny requests by clients.
The IAM roles deal with authentication while the RBAC roles handle the authorization of the request.
There are multiple strategies to perform authentication with the Kubernetes API server and we have looked at the Webhook Token Authentication which is used by AWS.
The link between the AWS IAM roles and the role-bindings is established by using a ConfigMap aws-auth which is used by the authenticator to figure out what Kubernetes groups a particular AWS IAM role or user belongs to.
Once the groups are identified, the operations that a particular group is allowed to perform can be known by looking at the role bindings (or cluster role bindings) and thus a request can be allowed/denied.
Feel free to reach out to me in case you have any questions 💖





Top comments (0)