
When we make operations against our Cosmos Databases, we use something called Request Units (RU’s) which is what you use for throughput. If you’re writing an item to Cosmos, you spend RU’s. If you read an item in Cosmos, you’re spending RU’s. If you’re making a query in Cosmos, you get the idea. This is consistent no matter what API you’re using for your Cosmos account.
When we provision our containers and databases, we set the amount of RU’s that we want to reserve for capacity. This has to be sufficient enough to ensure that our resources in Cosmos are available at all times. But how do we make sure that we have enough RU’s for our Cosmos DB? Do we just scale up the amount of RU’s each time, spending more and more money as our data grows? Or are there more effective strategies for ensuring that our application doesn’t just make it rain when it comes to RU expenditure?
Well, that’s what this post is for! What I’m attempting to do here is explain how throughput works in Cosmos DB and how you can optimize the design of your Cosmos DB solution to help you decrease the amount of Request Units your application uses to prevent throttling.
For this article, I’m going to use .NET code samples against a Cosmos DB account that uses the Core API (SQL).
Here’s a high level overview of what RU’s are:
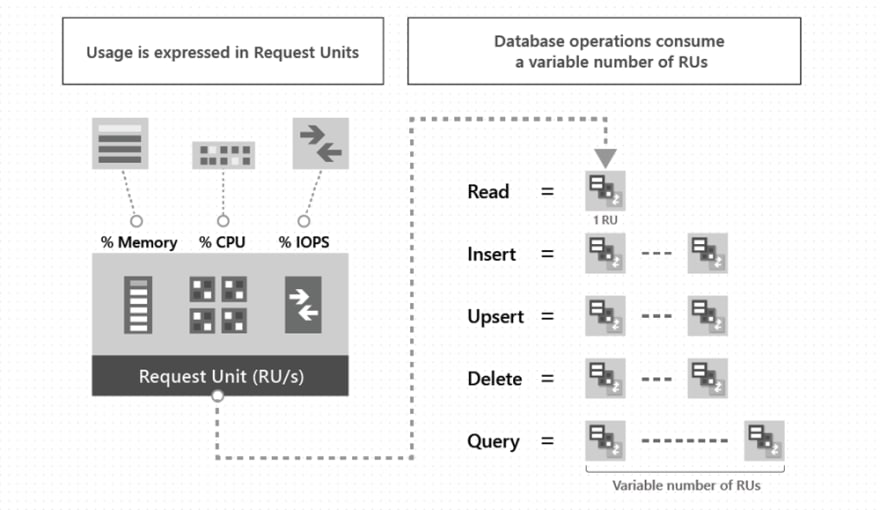
Request Units are the currency that we use to make operations against our Cosmos DB databases. It’s rate based and takes into account memory, cpu usage and input/output operations. No matter what API you use for your Cosmos account, costs are measured in RUs.
When we provision RU’s, we provision it by increments of 100 RU’s per second. We can scale this at any time in increments or decrements of 100 RUs. This can be done either programmatically (imo, the cool way) or by using the portal. We can provision throughput either on the Database level or on the Container level.
Let’s say we provision a container with 400 RU’s per second. We can make 10 queries a second that cost 40 RU’s. Anything beyond that, we’ll start to experience some throttling, and we should look to scale.
Before we go through how we provision throughput on either level and why you would you do so either way, let’s discuss some factors that we want to keep in mind when estimating the number of RU’s that we need to provision:
Item size and Item Property Count
It’s a good idea to keep in mind how big your item is going to be. When an item increases in size, the number of RU’s needed to write and read the item will increase as well. This is also the case for how many properties an item has. As our properties increase, the RU cost will also increase.
Indexing on items and properties
By default, every item is indexed. Also, by default every property within an item is indexed. This allows for quick queries on any property, but can be expensive when it comes to RU expenditure. If we want to save RU cost for Cosmos Operations, we can limit the number of indexed properties by defining our own indexing policy.
Defining our own indexing policy is fairly straight forward. We can set the indexing mode and exclude and include property paths to index.
In Cosmos DB, there are two indexing modes:
- Consistent : here, the index is updated synchronously as we create, update or delete items in Cosmos. The consistency level that we set on our Cosmos account will be the consistency of our read queries against our Cosmos account.
- None : This means that indexing is pretty much disabled. This helps increase the speed of bulk inserts.
We can implement custom indexing by deciding which property paths we want to include or exclude. This can help us lower the amount of storage our container uses and improve our write operations.
Just to give you a quick primer on how indexing works in Cosmos DB, every item is projected as a JSON document and then converted into a tree like format. Every property of an item gets represented as a node in a tree. The root node would be created as a parent to all first-level properties of the item and then the leaf nodes would contain the scalar values carried in the item.
It’s probably a good idea to discuss this using an example:
Let’s say that I’ve got a Cosmos DB with a Task collection. Items within the Task collection has the following schema:
The default indexing policy (where every property is indexed) would look like this:
As you can see, every property in our item is indexed apart from the etag (this is a default property that gets created with every Cosmos item). By default, range indexes are enforced for any string or number property and spatial indexes are enforced for any GeoJSON object. This provides us with fast query times, but it can get expensive in terms of RU consumption and is overkill for our simple example.
So for our Task items, I’m going to apply indexing on just the Task Name. Not the best example and in production scenarios, you’ll probably want to index on a few properties and perhaps even build composite indexing policies, but for the purposes of this article it’s enough:
So in our new custom indexing policy, we’ve just included the /TaskName/? property of our item and excluded all other paths.
If I was to give you a bit of advice on indexing, I’d recommend applying indexing on properties that your code queries against. In our example, say we had a Azure Function that just queried the Task collection for names of tasks, we would just index the TaskName property as I’ve done in the example above.
Data consistency
I won’t go too deep into Cosmos Data Consistency in this post, but both strong and bounded staleness consistency levels will consume around two times more request units when performing read operations when we compare it to other consistency levels in Cosmos.
Query complexity and patterns
The more complex our Cosmos DB queries are, we’ll spend more request units. This depends on a number of factors, including how many results are returned, how many predicates we use, the size of the data etc. The good thing about Cosmos DB is that provided the same query is used on the same data, we’ll spend the same amount of request units on that query no matter how many times we execute that query.
Usage in our scripts
Stored Procedures and Triggers also consume RU’s which depends on how complex the operations are when we they are executed. To help us see how many RU’s they consume, we can inspect the request charge header to see how much they cost.
Let’s take the following .NET sample. Here we’re executing a Stored Procedure connected to our collection and then using the RequestCharge property on our response to see how many RU’s that particular stored procedure has consumed:
Throughput in Cosmos DB is charged hourly regardless of whether you use it or not. Monitoring your queries to see how many RU’s they consume is an effective way to ensure that you have the right level of throughput provisioned on your container or database.
You can also use the Cosmos DB SDK’s to scale throughput as needed depending on your anticipated workload. Say if you’re doing most of your processing during a Monday at 5am in the morning, you can programmatically increase the provisioned throughput via the Cosmos DB REST API.
As I mentioned earlier, we can provision throughput either at a Database level or at a Container level. But why would we choose one method over the other?
When we provision throughput at a database level , all containers within that database will share the provisioned throughput. This is a cheaper way of provisioning throughput, but it comes at the expense of not receiving predictable performance on a specific container.
We can’t selectively apply throughput to a specific container or logical partition, as it’s shared unevenly among all our containers. All containers within a database that has provisioned throughput must be created with a partition key.
One reason we might want to provision throughput at the database level is that we have a few collections (less than 10) in our database and we want to save on costs. For example, say if we have a database for errors and have a couple of collections for different types of errors and we’re rarely reading these items, we would provision at the database level to save some money.
When we provision throughput on a container , it’s reserved for that container (obviously). That means that container will receive that throughput all the time. This throughput will be distributed uniformly across all logical partitions of the container, but you can’t specify the throughput for a particular logical partition. If one of our workloads running on a logical partition consumes more than then allocated throughput, we’ll start to experience throttling.
We would specify throughput on a container in situations where we would want guaranteed performance that that particular container.
We can mix and match throughput provisioning. If we have a container within a database that has throughput provisioned at the database level that we need to have guaranteed performance on, we can scale the throughput provisioned on this container as and when we need it.
Having a good partitioning strategy is key for throughput. By ensuring that we have a partition key that isn’t skewed, we can prevent an issue called ‘hot partitioning’ occurring. This is essentially when one partition hogs the throughput when we run Cosmos operations against it.
For example, say we have a Order collection that is partitioned by name. One customer has 10,000 order items stored within our collection and all our other customers have 100 order items associated with them in the same collection, the customer with 10,000 orders would hog the logical partition and therefore hog most of the throughput.
Having a partition key that has a wide range of values optimizes our query costs and can help us save on throughput costs.
Finally, We can monitor throughput via the metric pane in Cosmos DB. Through the Throughput tab, we’re able to measure such metrics as:
- Number of requests made against our collection (And by type of HTTP code. Check out this article for an explanation of what HTTP codes mean in Cosmos DB).
- Number of requests that have exceed our throughput capacity (These generate HTTP 429 errors).
- Max consumed RU/s per partition key range. We can filter this by how much we have provisioned and how much we have consumed per partition.
We can also set up alerts against these metrics using Azure alerts that can fire off emails to account administrators, use a webhook to connect to an Azure Function that will automatically increase provisioned throughput on our container or database or even fire an alert that integrates with any IT Operations service that we may be using via Azure Monitor.
Hopefully, this article helps you in optimizing and provisioning throughput on your Azure Cosmos DB databases and containers. I’ve gone into more detail for the strategies I’ve implemented in my day-to-day work, and I’ve noticed some significant savings in RU expenditure. If you want to read more about optimizing throughput, the Azure documentation is the best place for a detailed explanation into a variety of different strategies.





Top comments (2)
Hi. I have a question in my mind. I read always that throughput is distribu5ed uniform between de difrerent partitions. My question is, each time you have more partitions this amount of throughput for eavh partition decrease??? Or it is distributed the RU for thosr partition are being querying in a exact time/second?
Hi Antonio,
Hopefully this example can help answer your question. Say if I provision a container with 10k RU's and I happen to have 10 partitions, then each partition will be allocated with 1K RU's. This is done for that particular second/exact moment of time.
This happens to the ones that are being queried at that particular moment. So if you have a time where only 5 partitions are being queried, than 2K RU/s will be allocated to each partition.
Hope I've explained that well enough? If you have more questions, let me know 😊