
Databricks Delta uses both Apache Spark and Databricks File System (DBFS) to provide a transactional storage layer that can do incredible things for us as Data Engineers. Databricks Delta is a optimized Spark table that stores data in Parquet file format in DBFS and it uses a transaction log that efficiently tracks changes to a table.
In this tutorial, we’re going to stream some tweets from twitter that contains the #azure string, send that to Azure Event hubs and then writes and appends those tweets to a table.
This tutorial builds on the Sentiment Analysis on streaming data using Azure Databricks tutorial that’s on the Azure docs. If you’re just starting out with Streaming in Databricks, I recommend you check it out as you get to work with some pretty cool Azure services.
In this tutorial, instead of printing out to the console, we will append the data as it comes to a delta table that we can store inside a database. If you wish to follow along with this tutorial, make sure you complete the Azure one first so you know what I’m on about. Also bear in mind that at the time of writing, Databricks Delta requires a Databricks Runtime of 4.1 or above.
In order to write our data to a Delta table, we’ll do the following things:
- Save the streamed data to parquet files as they come in to a sink in DBFS.
- Read the parquet files and then append each file to a table called ‘tweets’
Let’s crack on!
Save the streamed data in a sink
We can write data to a Databricks Delta table using Structured Streaming. In this tutorial, we’ll write our stream to a path, which we’ll use to add new records to the table we’re about to create as it comes. Write the following Scala code at the end of AnalyzeTweetsFromEventHubs:
streamingDataFrame.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/delta/events/checkpoints/tweets")
.start("/delta/tweets")
In this block of code, we’re appending our stream in delta format to the location /delta/tweets.
You might be asking ‘what the hell is delta format?’ The answer is
Read the parquet files and append to tweets table
Now that we’ve got our sink, let’s create a table for these files to be written to. Underneath your sink code, write the following Scala code:
val tweets = spark.read.parquet("/delta/tweets")
tweets.write.format("delta").mode("append").saveAsTable("tweets")
Here, we create a value called tweets that reads our streamed parquet files, then we write those formats to a table called tweets. We can view this table by clicking on the Data icon in the UI.

We can have a look inside our table and we can see that rather than having the content and sentiment printed to the console, we have it inside a table within Databricks
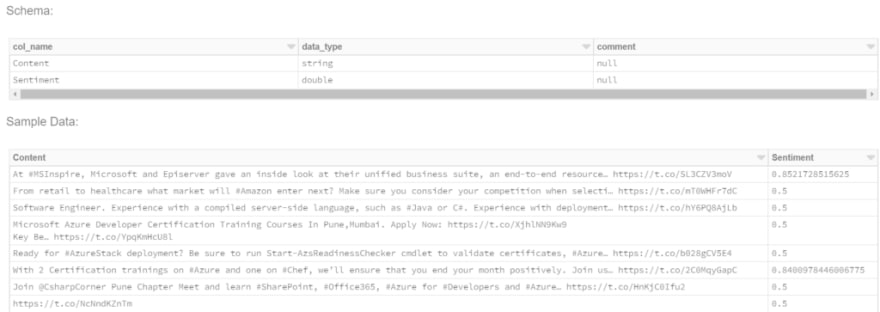
We can also view the contents inside our notebook using display:
val tweetsTable = spark.table("tweets")
display(tweetsTable)
Your output might be a little different depending on when you run it, but here’s what it could look like:

In conclusion
In this tutorial, we used the power of Databricks Delta to take our streaming data and put it into a table that we can run queries against and store in a database within Databricks. We could extend this example further by joining it with some static data or in Spark version 2.3.0+, join it to another streaming dataset.
This example used Azure Event Hubs, but for Structured Streaming, you could easily use something like Apache Kafka on HDInsight clusters.




Top comments (3)
Hi Will,
Thanks for amazing write up.
But I am facing an issue while executing cmd:
tweets.write.format("delta").mode("append").saveAsTable("tweets")
for the first time the data is stored in delta table, but executing it again gives me the error:
"org.apache.spark.sql.AnalysisException: Cannot create table ('
default.tweets'). The associated location ('dbfs:/user/hive/warehouse/tweets') is not empty.;"
How can I make sure the data is continuously getting stored in table format as well.
Thanks in advance
Hi Will,
When I try to write a streaming data to a partitioned managed delta table it's not loading data into it and also it's not showing any error,
but the same thing working fine with non partitioned managed delta table
what I'm missing here ??
dfWrite.writeStream\
.partitionBy("submitted_yyyy_mm")\
.format("delta")\
.outputMode("append")\
.queryName("orders")\
.option("checkpointLocation", orders_checkpoint_path)\
.table(user_db+"."+orders_table)
Hey Will nice post, well I think, I would directly write data to delta table instead of writing it first to parquet files because if I will write them as parquet and then read them in delta table then only first time row present in parquet files on DBFS will get ingested into table, and rows coming after that they will not get ingested into table and I would have to manually run read.saveAsTable() to get them ingested into delta table, Try it, Please share your thoughts. Thanks.