
Preamble
Let's admit. JavaScript is not the most predictable language out there. It might get pretty quirky very easily.
Let's look at the following example.
setTimeout(() => console.log("1. timeout"));
console.log("2. console");
Promise.resolve("3. promise").then((res) => console.log(res));
// prints
// 2. console
// 3. promise
// 1. timeout
Even if we will change the order of instructions, it won't impact the final result 🤨
Promise.resolve("1. promise").then((res) => console.log(res));
setTimeout(() => console.log("2. timeout"));
console.log("3. console");
// prints
// 3. console
// 1. promise
// 2. timeout
It doesn't matter how we will shuffle these three lines, they will always end up executed in the same order console, promise, timeout 😐
Why? Well, you know...

Of course, there is a good (enough) reason for that. And we'll get to it shortly. But first, we need to clarify a thing or two.
Put on your JavaScript hat and let's go! 🎩
We are going to focus on the Web Browser JavaScript, nonetheless most of the things we are going to discuss can be correlated to other agents, such as NodeJS.
ℹ️ Worth mentioning
setTimeout(() => {}) is equal to calling setTimeout(() => {}, 0).
Although neither will guaranty immediate execution as the timeout value (0) is used to set the minimum wait period, not the exact period.
Anyhow example above is completely legit in a given context.
One thing at a time
There's one important aspect of JavaScript we need to call out from the start. The single-threaded nature of the environment it runs in. It is hard to overstate the impact of this fact on the language, web browsers, and ultimately anything that runs JavaScript.
one thread === one call stack === one thing at a time
Pause here for a sec... One thing at a time...
Even when it seems like multiple things are happening simultaneously, in reality, there's only one single task that gets executed at every given moment, just really fast.
The single thread we were talking about is called browser main thread (nowadays more accurate name would be a tab main thread 🙃)... Thus everything that happening on the page is happening in one single thread.
It is easy to underestimate the scale. While our gorgeous code is running, meantime the web browser is rendering page content, receiving and dispatching all sorts of events, doing garbage collection, distributing future work, and much more...
ℹ️ What about JavaScript Console, that thing we all use in the Browser Dev Tools?
It depends, but most likely it will be a different process, hence a different thread.
❗Exception...
The "single thread" thing is the default behavior, however, we can branch from the main thread and run our JavaScript code in the separate thread with a help of Web Workers API.
A single thread is not a mistake or a bad design. Make JavaScript single-threaded was a conscious decision... Years ago, the average computer had a single core and was less powerful than any mid-range phone today. Websites were not really interactive (if at all), hence didn't really need any JavaScript magic.
Who could foresee where it is going to end up...
That thing that runs your JavaScript
Often terms JavaScript Runtime and JavaScript Engine are used interchangeably. Nevertheless, they are like salt 🧂 and green 🟩. Two completely different things. Let me explain what I mean.
Three main pieces constitute the JavaScript Runtime. They are conceptually separated. And most likely developed by different people/teams/companies, and represent independent pieces of software. However, they work in close collaboration.
- JavaScript Engine: compiles, optimizes, and executes code, handles memory allocation and garbage collection
- Event Loop: orchestrates and distributes the work, enables asynchronicity.
- Browser Web API: allows communication with things located outside of the Runtime (e.g system timers, file system, HTTP, address bar, DOM, etc.)
The Big Picture
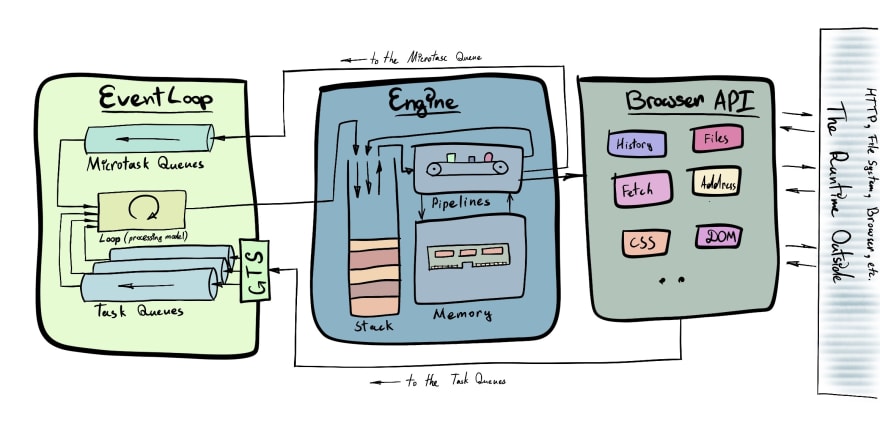
The Engine
The JavaScript Engine... does not run JavaScript...It runs ECMAScript.
Isn't it the same thing? Appears no, I'll explain.
If we will look through the source code of an arbitrary JavaScript engine (you know, cuz it is a casual thing we do lol 🤪), we will find an implementation of the ECMAScript declaration. This will include all sorts of base objects (including Object) such as Date and String, key language constructions like loops, conditions, and so forth.
However, if we will look for say setTimer or fetch, we won't find much. Because they are not part of ECMAScript. They are part of Browser Web API (nothing to do with Web itself really, more like Browser API 🙃, but you'll find it going under Web API, Web Browser API, Browser API and simply API).
The JavaScript Engine will be managing memory and controlling the execution of our fabulous code. Which will never be executed in its original shape, the engine will keep modifying it all the time. Most of the engines are pretty smart, they will keep optimizing the code throughout the page lifetime in the constant chase for performance improvements.

Important though is that the engine only executes the code that it finds in the Stack of Frames (or Call Stack or simply the Stack). Each frame represents a function call. While the engine is running the code, it might discover a new function call (not to be confused with function declaration) and push it to the Call Stack as a new frame. Once a new frame has been added, the engine pauses the execution of the current frame and focuses on the new one. After Engine finishes frame(function) execution it pops it from the stack and continues where it left, assuming it is not the last frame.
Every function call will end up as a new item on the Call Stack. Worth mentioning that Engine does not own exclusive rights on pushes to the Call Stack, new work might be pushed from the outside of the engine boundaries (we'll talk about it next).
The Call Stack controls the execution sequence inside Engine. Engine won't stop popping frames from the Call Stack until it is empty. And it won't allow any interruptions from outside until it is done.
⏪ In the previous article Web Browser Anatomy we've already discussed some of the key JavaScript engine aspects (parsing, pre-parsing, compilation, and optimization/de-optimization). With a deeper focus on the V8 Compilation Pipeline.
The article is more focused on the code processing itself and slightly touches Browser Engine (not to be confused with JavaScript Engine) and basic rendering concepts, so if it sounds interesting, don't forget to check it out after. 😏
The Loop
The Event Loop is an orchestrator and the main distributor of the work. It does not perform the work itself, but it ensures that the work is distributed in the expected manner (which may vary from browser to browser).
It is literally an infinite loop ♾️ which constantly keeps checking if there's any work it can schedule for execution.
A simplified version would look like this
while (true) {
if (allDone()) {
const thingsToDo = getThingsToDo();
doThings(thingsToDo);
}
}
ℹ️ On each iteration, the Event Loop performs an ordered series of jobs defined in the processing model documentation. We will be getting back to it through the course of the article.
The Event Loop and event loops
The Event Loop we usually refer to in the context of the web browser is a Window Event Loop. Every origin will get one. However, sometimes few tabs/windows from the same origin might share a single loop. Especially when one tab is opened from another. (This is where we can exploit multiple tabs/pages at once)
Anyhow, Window Event Loop is not the only one event loop running in the browser. Web workers (and other workers) will use its own Worker Event Loop. Sometimes it will be shared across all workers. And worklets will have its own Worklet Event Loop.
But hereafter when we refer to Event Loop we will actually be referring to the Window Event Loop.
Tasks, Microtasks and Macrotasks
Given the single-threaded nature of the language, it is hard to overstate the importance of asynchronicity.
The async behavior is implemented by a set of queues (FIFO).
This is a very common approach. Queues are very comfortable for implementing asynchronicity in software (and beyond its boundaries).
Think of a cloud architecture. With a high probability in its heart, there will be some sort of queue that will be dispatching messages all over the place.
Anyway, back to JavaScript.
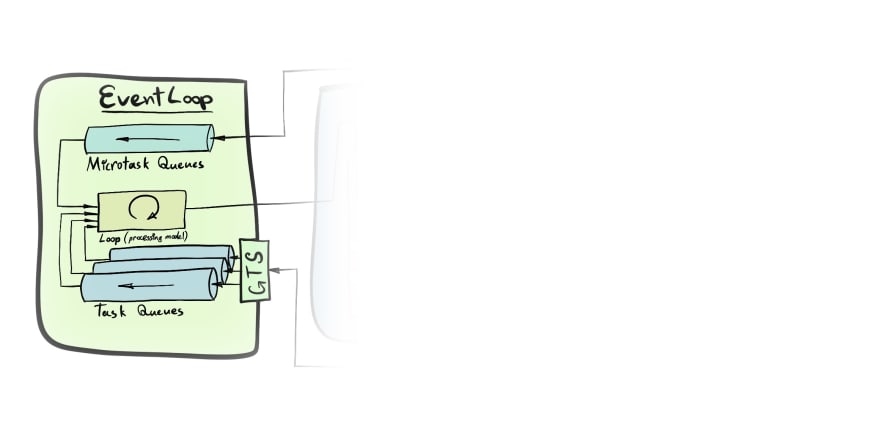
There are two (not three...) main types of queues, task queue, and microtask queue. At the first glance, it might look like they are identical. And it is true to some degree, they have the same role: postpone code execution for later. The difference lies in how Event Loop uses them.
❔You probably wondering where did macrotasks go...
Macrotask is just a V8 name for the task. So thereafter we will use the term task and everything we say for the task can be applied to macrotask
Task queue
The task queue is what keeps the whole thing spinning. This is where most of our code gets scheduled for execution. Event the initial code (the one that we place in-between the <script>...</script> tags) gets to the Call Stack through the Task Queue.
Often our code looks like this
do this on button click
do that when the server responds
call the server
In other words, we define callbacks (what to do) and assign them to events (when to do) that suppose to trigger them. When the event happens it does not execute the callback immediately, instead, it creates and enqueues a task in the Task Queue, which in its turn will be eventually processed (in other words pushed to the Call Stack).
The queue is out of our direct reach. Dequeueing is happening inside the event loop. Most of the tasks are enqueued through so-called generic task sources. This includes user interactions, DOM manipulation, network activity and history. Although we obviously have a way to impact what and when will get to the Task Queue (e.g through event handling).
Ok, that's gonna be a tough sentence, so bear with me here... Dequeueing process happening once per iteration and it will least (keep dequeuing) until the newest task from the previous iteration (that have been in the queue at the moment of the beginning iteration) is still in the queue. Keep in mind that the newest tasks will be in the tail of the queue, due to FIFO (First In First Out) concept.
In other words, all new tasks we are adding will be executed in the next iteration, all current/old tasks will be executed in this iteration.
As per processing model documentation.
😮 The task queue is not really a queue, but an ordered set. However, it is not very important as its behavior in this context is equivalent to the queue.
There might be (and probably will be) multiple task queues in a single event loop. The most common reason for that is task priority management. E.g. there might be a separate task queue for user interactions and another queue for everything else. This way we can give user interactions higher priority and handle them before anything else.
Microtask queue
Promises, asynchronous functions all this goodness is empowered by the microtask queue. It is very similar to the task queue, except for three major differences.
- Microtasks are processed at different phases in the Event Loop iteration. We mentioned above that each Event Loop iteration following strict order known as processing model;
- Microtasks can schedule other microtasks and the new iteration of the Event Loop won't begin until we reach the end of the queue;
- We can directly enqueue a microtask with queueMicrotask;
The rest is pretty much the same, once a task is dequeued and a callback is extracted, it will be pushed to the Call Stack for immediate execution.
Browser Web API
The final piece in the puzzle is an API, the Browser API. The connection bridge between the code and everything outside of the runtime.
Communication with a file system or remote service calls. Various event subscriptions. Interactions with the address bar and history. And more. Is facilitated by Browser API.
Browser API allows us to define event handlers. And this is the most common way for developers to pass callbacks (event handlers) to the Task Queue.
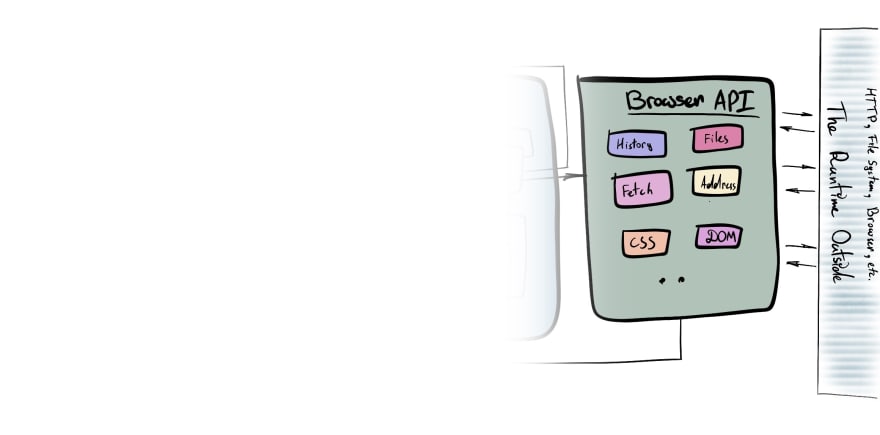
Browser API are browser-specific. Each browser implements them separately. Hence they work differently, although probably will have the same effect.
Hence every now and then you might bump into a cool new feature that won't be supported by Internet Explorer Browser X. And the most common reason, the API is not implemented in the Browser X.
At least nowadays the naming is kinda conventional and no one tries to show uniqueness...
Imagine writing code when all browsers would name things differently and everything would produce different effects... That would be a nightmare, wouldn't it?
Well, it used to be like that. And it is kinda like this nowadays lol. Fortunately, we have many tools like BabelJS and a huge community behind that helps mitigate this problem for us.
I still remember 👴 how you had to implement ajax calls (XMLHTTPRequest) for all possible browsers in your code until the jQuery appeared. That was a game-changer.
Bringing things together
We've discussed quite a few things thus far. Let's bring them all together in a single list. And go over it in the same order as Event Loop will.

Remember that once some code gets in the Call Stack, the Engine will hijack control and start popping, executing, and pushing the code until finally, the Call Stack is empty. Once reached the end of the stack it returns control to the same point where it hijacked it.
The browser will find some JavaScript either in-between the <script> tags or in the DevTools Console. And ultimately it will push it to the Task Queue...
- The Loop keeps checking the Task Queue. Once it finds the initial code the Loop will move it to the Call Stack. The Engine immediately takes over and doing its job until it empties the Call Stack.
- The Loop will check microtask queue(s). It will keep dequeuing tasks from the queue and pushing them (one item at a time) to the Call Stack (and it will keep executing until empty) from the microtask queue until the microtask queue is empty. Remember that microtask code can push another microtask in the queue and it will be executed during the same iteration (right here).
- Both Engine Call Stack and Microtask Queue are now empty.
- Finally the Loop gets back to the Task Queue. Keep in mind that events were emitting all the time, either in the code or outside of it. The Loop will mark the newest task (the one in the tail of the queue) in the queue and start dequeuing tasks from oldest to newest (head to tail) and pushing code to the Engine Call Stack until it reaches marked task.
- Next it will do some other unrelated to the runtime work, like rendering.
- Once all is done the new iteration starts from point 1
The example
Let's revisit the example from the beginning of the article...
setTimeout(() => console.log("1. timeout"));
console.log("2. console");
Promise.resolve("3. promise").then((res) => console.log(res));
// prints
// 2. console
// 3. promise
// 1. timeout
Doesn't matter how we would shuffle instruction, the produced result will stay the same
Actually now it makes much more sense, check it out.
- First, all this code is sent to the Call Stack and executed sequentially.
-
setTimeoutalmost immediately sends a callback to the Task Queue. -
console.logprints string in the console (this is our first line2. console). -
Promise.resolve(...).then(...)is immediately resolved promise, thus it sends the callback to the Microtask Queue the same moment it is executed.
-
- Stack finishes execution, it is empty and it passes control back to the Event Loop.
- Event Loop checks Microtask Queue and finds there callback from the resolved promise and sends it to the Call Stack (this is our second line
3. promise) - Microtask Queue is empty, Call Stack is empty, it is Task Queue turn now.
- The Event Loop finds a timeout callback in the Task Queue and sends it to the Call Stack (this is our third and last line
1. timeout).
And we are done, the stack is empty along with all queues.
That wasn't too bad, was it?
Recursion Examples
Alright, it is time to have some fun! 🤓
Given we already know how to interact and what to expect from both queues and a stack. We will try to implement three different infinite recursion examples. Each will utilize one given mechanism.
It will be more fun if you'd open a console and try to run code examples on your own. Just don't use this page's console lol.
I'd also advise preparing Browser Task Manager to keep an eye on changes in memory and CPU consumption. Most of the modern browsers will have one somewhere in settings.
Let's start with classics.
Call Stack
const recursive = () => {
console.log("stack");
recursive();
console.log("unreachable code");
};
recursive();
console.log("unreachable code");
/*
stack
stack
stack
...
Uncaught RangeError: Maximum call stack size exceeded
at recursive (<anonymous>:2:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
at recursive (<anonymous>:3:1)
*/
The infinite recursion and its good old buddy Stack Overflow Exception. I bet you've seen a few of these before...
The Stack Overflow Exception is about reaching the max size of the Call Stack. Once we exceed the max size it will blow up with a Maximum call stack size exceeded.
Note that there are a few console.log that will never get printed.
Remember that every time we push a new item on the Call Stack, the Engine will immediately switch to it, since we are just pushing new items and never popping. The stack keeps growing until we reach its maximum...
Task Queue
Let's try the Task Queue now. This one won't blow up immediately, it will run much longer util the browser propose you kill the page (or wait if you are insistent).
const recursiveTask = () => {
console.log("task queue");
setTimeout(recursiveTask);
console.log("reachable code 1");
};
recursiveTask();
console.log("reachable code 2");
/*
reachable code 2
task queue
reachable code 1
task queue
reachable code 1
task queue
reachable code 1
task queue
reachable code 1
...
*/
Note that both extra console.log statements are printed. Because all the time we are adding a new task to the Task Queue, we add it for the next iteration and not for immediate execution. Hence all code in this example is processed before starting a new iteration.
Keep an eye on the memory footprint. It will be growing fairly fast together with CPU usage. Under a minute my tab went over 1 Gig of memory.
Microtask Queue
Ok, the final one, we'll do the same stuff, infinite recursion, but this time for the microtask queue.
const recursiveMicrotask = () => {
console.log("microtask queue");
queueMicrotask(recursiveMicrotask);
console.log("reachable code 1");
setTimeout(() => console.log("unreachable code 1"));
};
recursiveMicrotask();
console.log("reachable code 2");
setTimeout(() => console.log("unreachable code 2"));
/*
reachable code 2
microtask queue
reachable code 1
microtask queue
reachable code 1
microtask queue
reachable code 1
microtask queue
reachable code 1
...
*/
Note how tasks from the Task Queue are never executed ("unreachable code"). This is happening because we never end up current Event Loop iteration, we keep adding microtasks to the Microtask Queue and it prevents the iteration from finishing.
If you will leave it for long enough you'll notice that the page (including the address bar) becomes less responsive. Until it completely dies.
Of course, the memory footprint (and CPU usage) will keep growing much faster, since we polluting the Task Queue, but if we will remove both setTimeout it will reduce the pace of memory footprint growth.
📝 Side note
Recursion might be dangerous for infinity simulation. I'd recommend looking into generator functions for such matters. We won't get under the boot of generator functions. At least for now.
But here's a small example of an infinite number generator, which shows the gist of it.
function* generateNumber() {
let i = 0;
while (true) yield i++;
}
const numbers = generateNumbers();
console.log(numbers.next().value); // 0
console.log(numbers.next().value); // 1
console.log(numbers.next().value); // 2
That's it.
Of course, everything we looked at is a simplified representation. However, it illustrates in enough detail how the Runtime functions. It is accurate enough to explain the true nature of asynchronicity and code execution sequences in JavaScript. As well as hopefully reveal some "odd" behavior and "unexpected" race conditions.
JavaScript has an extremely low entrance barrier. And often it is confused with being unstable.
However, some of its behavior is a trade-off of some sort and payment for such a low entrance barrier. Although few bugs are left there for backward compatibility lol...
If you enjoyed the read, don't forget to check out another related article Web Browser Anatomy.
👋





Latest comments (1)
What a great article. Thanks.