This blog is an attempted explanation to paper Attention is all you need. You can find the paper here
You can find the source code here
RNNs and CNNs have been used dominantly in sequence to sequence tasks, but the use of attention has proved much better results.
Here we will focus on self-attention where we essentially find the co-relation between the embeddings of a sequence.
But, Before moving to the attention part, lets take a look at word-embeddings.
Word Embedding is a vector representation of a particular word. So, even for words representing multiple meanings the embedding is same.
For example words like - apple - it could be a fruit or name of a company.
The embedding would be same for both the meanings. Lets assume that the embedding representing 'apple' is a 50 dimension vector represented below:
[0.2, -0.7, 0.6 ... 0.1. 0.3]
What could this vector possibly represent ?
The values in the vector represent concepts, the value at 'index 1' may represent the concept of a fruit and then the values at 35th index may represent something related to electronics or may be a combination of multiple indices represent such concepts.
When RNNs and CNNs were used the neural networks couldn't decide which concepts to focus on. This is where self attention makes the difference and is able to find the corelation between concepts.
For example - if the network encounters a sequence 'apple iphone' then it is able to identify the context of an electronic device, and if it encounters something as 'apple pie' then it catches the context of something eatable.
Lets look at the architecture of the network. In the paper they train the network for machine translation.
The network is an encoder decoder architecture which uses attention layers or we can say blocks.
We will look into each block one by one.

The left and right blocks represent the encoder and decoder respectively.
Let's study at the encoder first.
Encoder
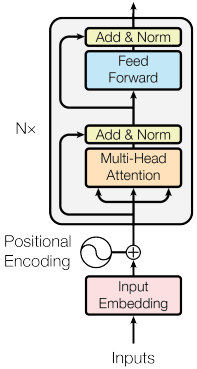
- The input to the encoder is the source sentence. The source is converted to a embedding.
- The embedding is concatenated with positional encoding. Lets call this as input embedding.
- The input embedding is passed to three different fully connected layers and the three outputs are passed to the multi-head attention block. (We will learn attention and then multi-head attention in detail)
- These outputs are named query, key and value. Using three different fully connected layers proved to give better result as compared to using a single fully connected layer and repeating its output thrice.
- We add the input embedding to the output of multi head attention layers as a skip connection and normalize the sum.
- We pass this output to a feed forward layer which is literally fully connected layers. We again add skip connection and normalize the output before calling it as encoder output.
That's essentially the work of the encoder. Now lets look at the attention mechanism.
Self-Attention
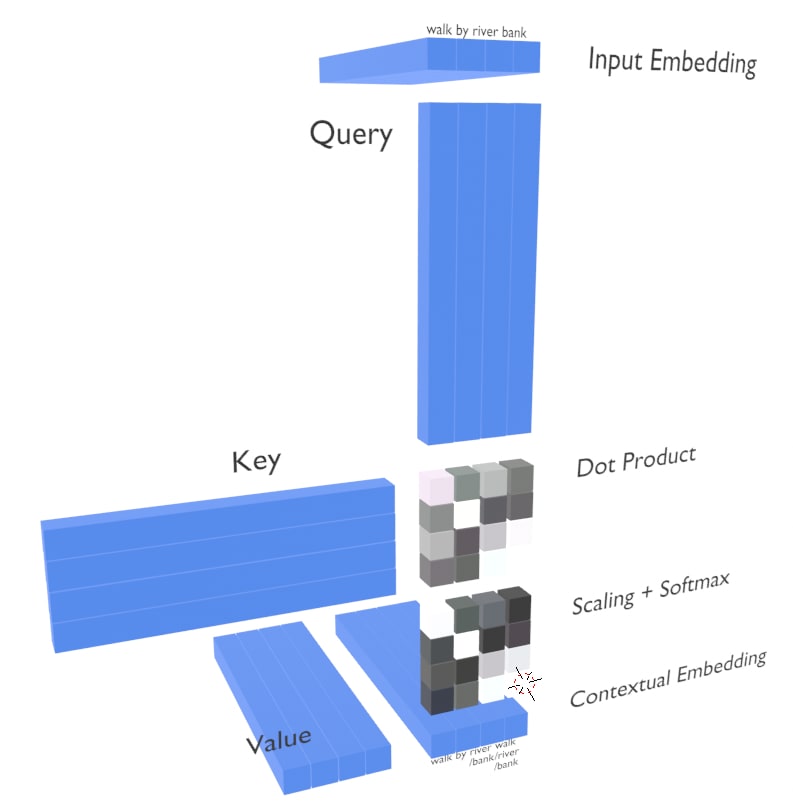
Let's take an example of input sequence - 'walk by river bank'. As discussed earlier the embeddings contain concepts for various meanings. Here the bank embedding is related to river bank. Lets see how self attention identifies the context.
- The input to the attention is query, key and value as discussed.
- Note : the input embedding is passed to three fc layers. That is not shown in the diagram above for simplicity.
- The embedding in the diagram are some N dimensional vector.
- The first thing attention does is to find the corelation between embeddings. If the embeddings relate to similar concepts the corelation value is higher otherwise lower.
- We take the query and key which are essentially the same, and find the corelation between every pair of words.
- This gives us a square matrix which has the corelation value. The square matrix is result of matrix multiplication of the query and key.
- Here we will see that the words which are conceptually related will have higher value. For example the word 'river' and 'bank' are somehow related to a concept of water body. The dimension which represent the context of a water body will multiply and contribute to higher corelation value.
- Then we take the column wise softmax so that network focuses more on required concepts. It makes the bright blocks brighter and the dark blocks darker.
- Every time we scale or normalize we do so to prevent the issue of exploding gradients.
- The value is then multiplied with the corelation matrix to output the contexualized embedding.
- This contexulized embedding is different from the input as we can see the embeddings now just dont represent just their own concepts but also focus on similar words which share the same concepts.
This is called as self attention.
Now lets take a look at multi-head attention layer. This would be more intuitive now.
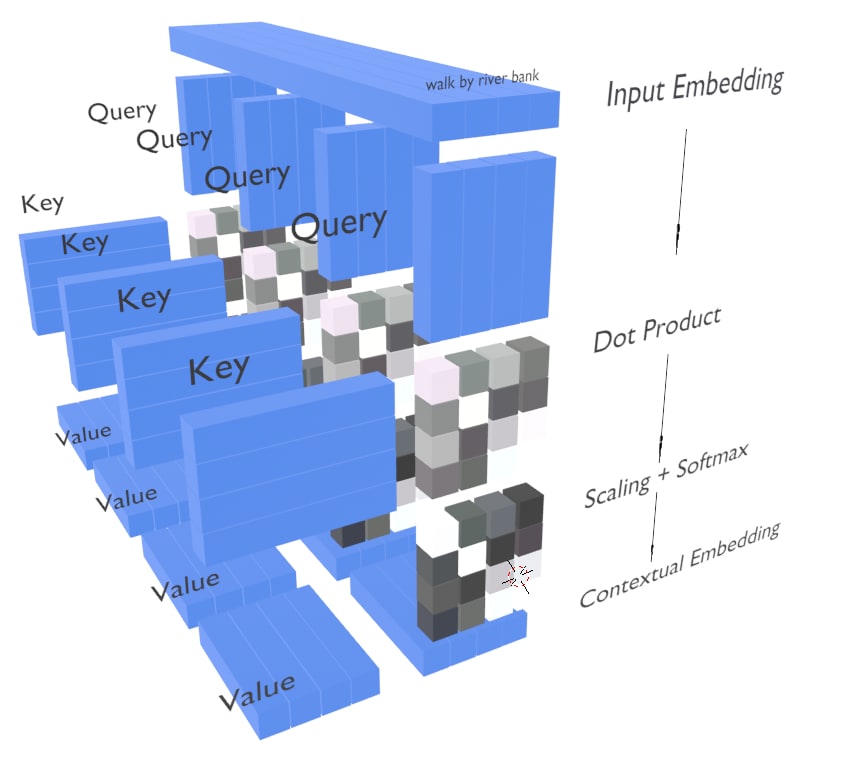
- It has the same mechanism, what we did above, just that the input embedding is divided into multiple equal size blocks which are called head.
- This is done so that the network focuses more on the concepts which are required. The head which focuses on concepts that do not contributes is suppressed by the network.
Now you may read again the encoder part to have a better understanding of the entire flow.
Decoder
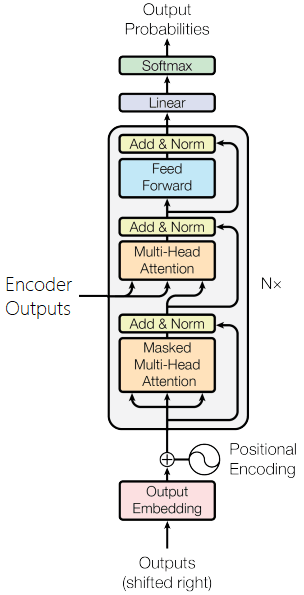
- The decoder is almost similar to the encoder with the major difference that it has one more multi-head attention layer which takes input from the encoder.
- The input to the decoder is target sentence.
- The steps are same what we did earlier in encoder.
- In the multi-head attention layer we only consider the lower triangle of the corelation matrix, because we dont want the network to see learn the concepts of the next word of the sequence, because that is what we want the network to predict. Think again on this part to have a better understanding.
- In the next multihead attention layer the input is the encoder key, encoder value and the target is used as query.
- This output is passed to fully connected layers to as we did in encoder. This is basically to increase the capacity of the network.
- Finally predictions are made by passing through the softmax layer.





Latest comments (0)