Containerization of an application is not the end of story.
For any serious application, it’s the beginning of a new world of orchestration.
We need to think about many things, such as:
- It shouldn’t be down. If down or crashed, either restart or start a new one as soon as possible.
- Is it performing as expected? How do we monitor resource consumption?
- How to scale up/down with minimal efforts?
- How to move it to a different machine in case the host encountered a problem?
It’s not as easy as it seems, even for a simple use case.
So, what can we do about this? That’s where an orchestrator comes into the picture.
What is Kubernetes?
The official documentation defines Kubernetes as:
Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications.
Running containers on a single host or running a single container is not sufficient for a large-scale application.
We need a scalable solution like K8s which can handle the containers on scale and in fault-tolerant manner.
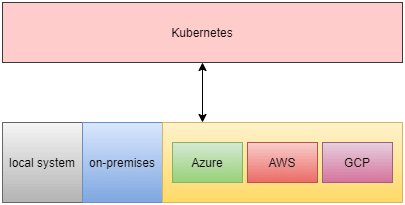
Kubernetes can run virtually anywhere — laptop, on-prem, cloud, bare-metal, VMs, etc.
The biggest advantage with K8s is that if an application can run in a container, it would(most probably) run on K8s irrespective of the underlying infrastructure.
K8s provides an abstraction over the underlying infrastructure which makes it possible.
Features
Here’s a brief list from the official documentation:
- Service discovery and load balancing
- Rolling updates and rollbacks
- Self healing — kills and restarts unresponsive containers Scaling
- Automatically mounting a wide variety of storage systems to store data
- Secret and config management — to manage sensitive data and config separately from the containers
- RBAC(Role Based Access Controls)
Kubernetes Cluster
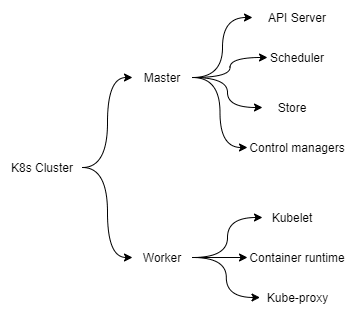
A K8s cluster has two main parts — Master nodes and Worker nodes
Control Plane with Master nodes
Control plane with the help of master nodes, manages the state of a k8s cluster.
It is not recommended to run user applications on master nodes.
Worker nodes
Worker nodes run user/client applications.
Master Nodes
In a K8s cluster, control plane with master nodes manages the worker nodes, and the overall cluster.
Let’s see what is inside the control plane.
Components
1) API Server(kube-apiserver)
API server is the face of a K8s cluster. It exposes a set of APIs that are used by all the components. All the components talk to each other via API.
The main implementation of a Kubernetes API server is kube-apiserver which is designed to scale horizontally.
2) Scheduler(kube-scheduler)
It watches for the new tasks(newly created pods) submitted to K8s cluster, and selects a worker node that can run those pods.
To select a worker node, it considers the health of worker nodes, their load, affinity rules, any other software or hardware requirements.
3) Cluster store(etcd)
K8s uses etcd to store config and state of the cluster. etcd is strongly consistent and reliable distributed key-value store. Please note that the etcd is not used to store data of containers or user applications, it’s only for cluster state.
4) Controller manager(kube-controller-manager)
It manages and runs controllers, and responds to various events.
A controller’s main job is to monitor the shared state of the cluster and make every possible change to achieve the desired state if the current state is not the desired state, more on this later.
5) Cloud controller(cloud-controller-manager)
This is specific to the cloud on which a K8s cluster is running. If you’re not running K8s on a cloud, there will be no cloud controller manager.
From Kubernetes docs — the cloud controller manager lets you link your cluster into your cloud provider’s API, and separates out the components that interact with that cloud platform from components that only interact with your cluster.
Concept of Desired state and Current State
When we on-board a workload/app on k8s, we tell k8s what’s our expectations eg. We need 3 containers always up and running.
So, this becomes the desired state of our cluster. Generally, it is part of the different payloads like your Pod deployment config in which you may define the number of replicas.
K8s continuously monitors the current state of the system, and if there’s a different between desired and current state, it tries to achieve the expected state — it scales up/down automatically, restarts/terminates containers automatically, etc.
So, let’s say, we started with 3 replicas of our container.
- Desired state = 3 replicas
After time T, one replica crashed.
- Current state = 2 replicas
- K8s controller manager noticed this event and found out that current state is no longer same as desired state.
- K8s will take corrective actions and launch a new replica to match the desired state of 3 replicas.
And the good thing is — it will do it in an automated way.
Worker Nodes
A worker node is responsible for running a user application.
On a very high level, a worker node:
- Gets a new task when scheduler(kube-scheduler) selects this node to “do something” via API server(kube-apiserver)
- Executes the given task
- Responds back to the master via API once the task is finished.
A worker node is a combination of:
Kubelet
- Kubelet runs on a worker node. Kubelet is the main agent that does many critical things like — registering the node with cluster and reporting back to scheduler whether or not it would be able to run a task.
Kube-proxy
- Kube-proxy is responsible for local cluster network
Container runtime
- Container runtime is responsible for creating and running containers. K8s can use any CRI compliant runtime e.g. Docker, containerd, etc.
The diagram summarizes the flow that we’ve seen up till now.

K8s Objects
Let’s now look at some of the most critical K8s objects.
Pods
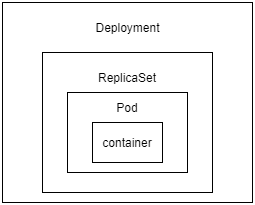
Pod is a wrapper around a container. It is the smallest deployable unit in K8s.
So, when we provide a Docker image and ask K8s to run and manage a container, it creates a Pod for that application. The containerized application runs inside the Pod.
It’s recommended to have one-container-per-pod container, but a Pod can have multiple related containers.
A Pod has a template that’s generally defined in a YAML file which tells what kind of container a Pod should host.
When a Pod goes down, K8s creates a new Pod.
Each new Pod has a different IP.
If a Pod has more than containers — those containers will share the same Pod IP and other network resources.

The container inside a Pod can be in one of the three states -
- Waiting
- Running
- Terminated
The container can also have a restart policy:
- Always(default)
- OnError
- Never
ReplicaSet
A ReplicaSet is another K8s object that acts as a wrapper around Pod. It is managed by DeploymentSet.
A ReplicaSet’s purpose is to maintain a stable set of replica Pods running at any given time.
The ReplicaSet knows from its config the Pod to run and how many replicas are needed. It then uses the Pod template to create those many replicas of a Pod.
To scale the application, ReplicaSet creates new Pods.

Deployments
Kubernetes documentation defines Deployments as below:
You describe a desired state in a Deployment, and the Deployment Controller changes the actual state to the desired state at a controlled rate. You can define Deployments to create new ReplicaSets, or to remove existing Deployments and adopt all their resources with new Deployments.
Deployment supports self-healing, scaling, Rolling updates, Rollbacks, etc.
StatefulSets
When a Pod goes down, K8s creates a new Pod with a new identity but from the same Pod template, and the new Pod will have a new IP. So, basically, the old Pod is lost.
StatefulSets can be used to manage the Pods when we need to retain the Pod identity.
StatefulSets are useful for stateful applications. They’re similar to Deployments but when a StatefulSet relaunches a container, it retains Pod’s identity, also called — sticky identity.
DaemonSet
This is straight from the official documentation:
A DaemonSet ensures that all (or some) Nodes run a copy of a Pod. As nodes are added to the cluster, Pods are added to them. As nodes are removed from the cluster, those Pods are garbage collected. Deleting a DaemonSet will clean up the Pods it created.
Some typical uses of a DaemonSet are:
- running a cluster storage daemon on every node
- running a logs collection daemon on every node
- running a node monitoring daemon on every node
So, the flow looks something like below:

Deployments — Scaling, Rolling updates, and Rollbacks
To run a user application, K8s uses Deployments to manage Pods. Deployment manages ReplicaSets, and ReplicaSet manages Pods.
Scaling and Self-healing
The sole purpose of a ReplicaSet is to maintain a stable set of replica Pods at any given time.
- Scaling — Depending on the replicas defined in the YAML template, ReplicaSet can create that many new Pods to match the demand.
- Self-healing — In the same way, when a Pod gets crashed, ReplicaSet notices the change in the cluster state, and tries to launch a new Pod to replace the dead one.
Rolling Updates and Rollbacks
Here’s how it works in K8s-
Let’s suppose, we have a Java application.
- We created a Docker image V1
- We created a Deployment using a YAML template which refers to the image — V1
- Deployment creates a new ReplicaSet RS1
- ReplicaSet creates a new set of Pods depending on the configured number of replicas
- Now, let’s say, we changed something in the application — a bug fix, an enhancement, etc.
- We create a new Docker image V2
- We update the YAML and change the image reference to V2
- The controller observes a change in the image i.e. V1 -> V2
- K8s creates a new ReplicaSet RS2(for V2) in parallel without touching old ReplicaSet RS1
- K8s starts creating new Pods in RS2 in parallel
- At this time, Deployment is running both the ReplicaSets — RS1 and RS2
- RS1 — with old image V1
- RS2 — with new image V2
- At the same time, K8s starts a new Pod in the new ReplicaSet and drops a Pod in the old ReplicaSet
- Finally, old ReplicaSet becomes empty and new ReplicaSet becomes fully operational with new Pods, running image V2
- At this point, K8s doesn’t remove old ReplicaSet which is empty
- The empty ReplicaSet is used in Rollback process
- To rollback, K8s just makes a switch to the empty ReplicaSet, and it starts the same process in opposite direction — RS2 to RS1
During this whole process, K8s keeps running the application, there’s no downtime.
Services
K8s documentation defines a Service like this-
A Service is an abstraction which defines a logical set of Pods and a policy by which to access them . The set of Pods targeted by a Service is usually determined by a selector.
A Service is a logical grouping of a set of Pods which also acts as a load balancer of that set.
Pods can talk to each other via Service.
A call from outside of K8s cluster is intercepted by the Service which then forwards the request to a certain Pod from its set.
So, Service also acts as a network abstraction which hides all the networking complexities.
Main components of a Service
There are two main components of a Service:
- Selector — Selector is used to select Pods which forms the logical group that is represented by the Service
- Endpoints — It is a list of healthy Pods. Service keeps the list up-to-date by monitoring the changes in the Pods e.g. crashed Pod, new Pod joins the cluster, etc.
How does a Service form a group of Pods?
The service uses a label selector to select the Pods.
Labels are simply a set of key-value pairs that we can attach to certain K8s objects like Pod.
Let’s suppose, we have three Pods P1, P2, and P3. And, we have two labels — env and version
Here’s how these Pods are tagged with these labels:
- P1 — env = prod and version = 1.0
- P2 — env = prod and version = 1.1
- P3 — env = prod and version = 1.0 Let’s also suppose that we have a Service with label selector defined as: > env = prod and version=1.0
So, based on this, Service will have two Pods in its set — P1 and P3
P2 won’t be selected by the Service because while its env label matches with value prod, but version is different — Service expects version=1.0 and P2 has version=1.1
Service Types
There are mainly three types of services:
- Cluster IP — To access Pods from inside
- NodePort — To access Pods from outside
- LoadBalancer — To integrate cloud specific load balancer e.g. Azure and AWS would have different load balancers.
Volumes and ConfigMaps
Volumes
Volumes are used as a storage solution for a K8s cluster.
We use or mount volumes to store the application data permanently so that if a Pod is crashed and started, it would not loose its data.
K8s uses a plugin layer to handle the volumes so it is capable of working with different types of storage solutions.
For instance, we can use a Azure Disk, EBS, etc. as a storage solution.
Persistent Volume
It acts as a storage abstraction which provides APIs to access and manage persistent storage.
Persistent volume represents a storage, an application would link to a persistent volume via a plugin.
For instance, Azure storage would have its own plugin that can be used to link an Azure storage as Persistent Volume.
PersistentVolume Claims
These are storage requests made by the user. Users request for a Persistent Volume based on certain criteria, and if a persistent volume is found, it gets linked to the PersistentVolume Claims.
ConfigMaps
ConfigMap is a K8s object which is used to store non-sensitive Pod configurations. This is a key-value pair.
For sensitive data, it is recommended to use Secrets rather than ConfigMap.
ConfigMap is a great way to separate configs from the code.
ConfigMap can be injected into a container in three ways:
- Environment variables
- Command line args
- As a file in volume
The only problem with first two is that these are static.
So, once an app gets started, and if there’s any change in the ConfigMap then it won’t be reflected until we restart the app because there’s no way to reload ConfigMap which was injected via environment variables or startup command.
Third option, using volumes, is the most flexible way where we create a volume for ConfigMap. Any change in the file will be reflected in the volume, and will be picked by the application.
Feel free to check out my page https://www.vmtechblog.com/search/label/kubernetes





Top comments (0)