In this blog post, I'll share how to host multiple static websites in a single S3 bucket, where each site is stored in a single directory (path).
CloudFront will serve the static website, and the trick to fetch the relevant site from the origin, S3 bucket, in this case, relies on a Lambda@Edge function.
Objectives
- Serve safely behind a CDN via HTTPS - CloudFront + ACM.
- Accessing the S3 bucket should be forbidden to anyone except for the serving CloudFront distribution; we'll use CloudFront OAI for that
- Store in durable storage, S3 Standard Durability 99.999999999% (11 9's), and highly available servers, S3 Standard Availability 99.99%
By the end of this blog post, I expect to have two live websites, which are stored on a single S3 bucket, and I want proof.
And of course, I'm too excited to keep to myself, right now I'm inspired by the below song ... So ... Are you re-e-e-e-ady let's go!

(1/6) HTTPS And DNS Validation
This step is optional if you already own an eligible ACM Certificate in the AWS region N.Virginia (us-east-1).
I own the domain meirg.co.il, so to avoid breaking my site, I'm adding another subdomain, and I'll name it multiple-sites, which makes my FQDN
multiple-sites.meirg.co.il
Additionally, I want to support accessing the site with www or any other subdomain (maybe api), so I'll add another FQDN
*.multiple-sites.meirg.co.il
Create An AWS ACM Certificate
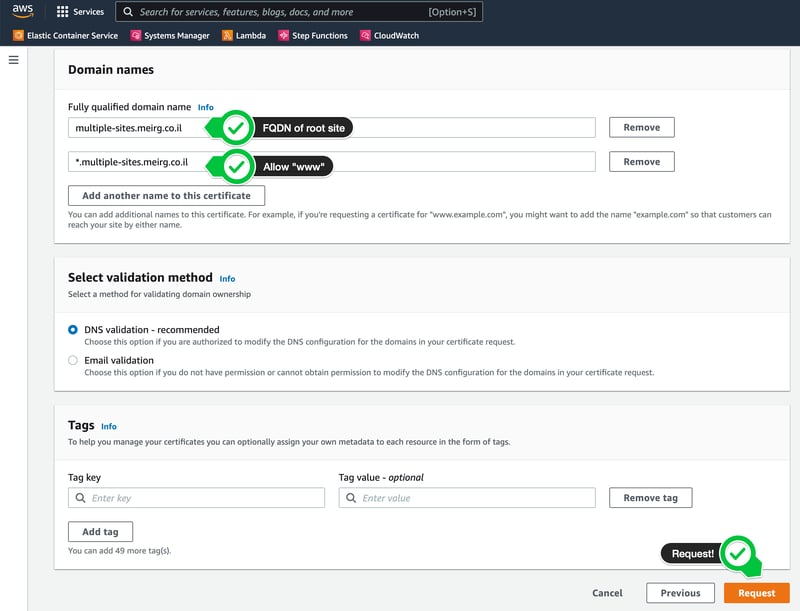
Create DNS Validation Records In DNS
Now I need to validate the certificate in my DNS management provider; in my case, it's Cloudflare (flare, not Front 😉)
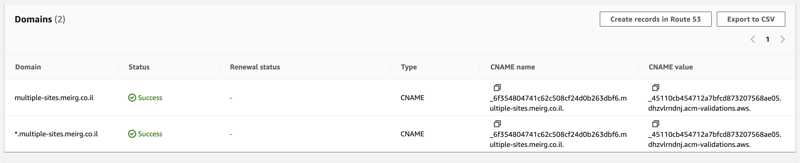
Then, I copied the CNAME+Value that was generated in ACM

And then, I created two new DNS records in my DNS management provider (how to do it in AWS Route53). Here's how it looks like in Cloudflare:
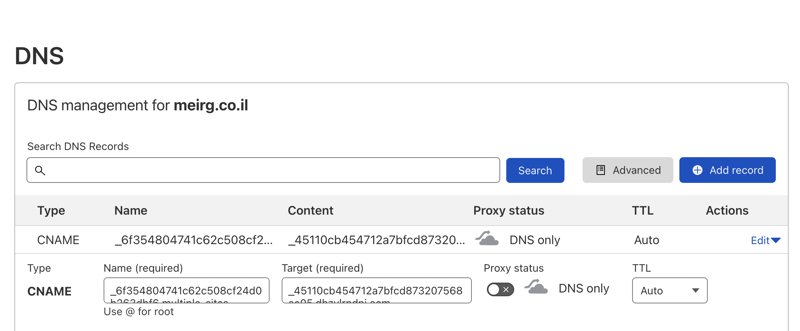
NOTE: Cloudflare provides a native CDN solution per DNS address, which is fantastic. As you can see, I turned it off (DNS Only) since it's irrelevant for the DNS validation.
And then ... I wonder if all those "and then" reminded you Dobby from the Harry Potter movie 🤭
Cloudflare And AWS CAA Issue
I got into big trouble; my certificate failed to validate
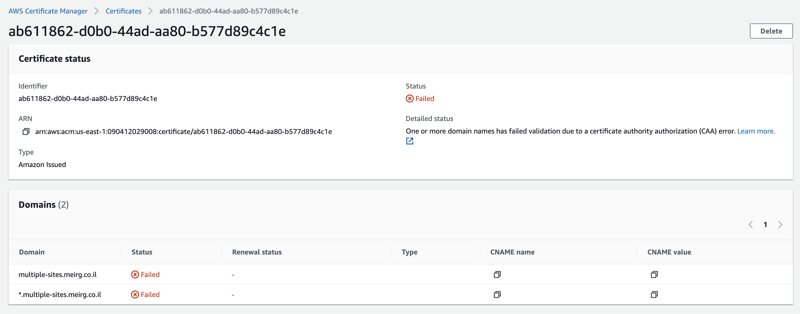
Even though this part is not directly related to this blog post, I'm putting it here for future me (or the currently frustrated you who found it). Bottom line, I fixed it by reading How to Configure a CAA record for AWS and created the DNS records accordingly in Cloudflare.
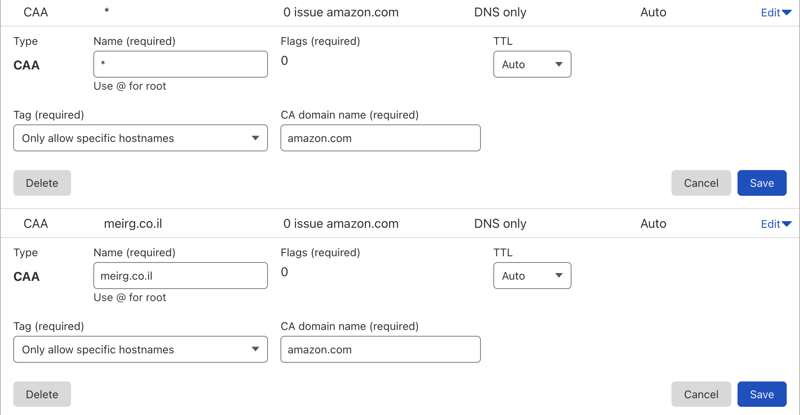
Validated ACM
Finally, my ACM certificate is eligible, and all DNS records were validated successfully, thanks to the CAA records created above 🙇🏻♂️
(2/6) Create An S3 Bucket
This part is relatively easy if you're familiar with AWS S3, though I do want to emphasize something -
An AWS S3 bucket is an object storage; hence it cannot be served to a browser unless set to AWS S3 Static Website.
NOTE: S3 is an object storage, so directories (paths) aren't really "storage locations", but more like pointers that state where the data is stored in an organized way, like filesystem storage.
An S3 static website is only available via HTTP. Serving the site via HTTPS requires a CDN, such as AWS CloudFront or Cloudflare. This information is available at How do I use CloudFront to serve a static website hosted on Amazon S3?
So why am I double-posting something that is already out there? Because I found it very confusing to realize that the term "static website" and the term "S3 static website option" are different.
By its name, I would expect to enable AWS S3 Static Website Option to make this solution work. It should be disabled.
Here's the thing, AWS S3 Static Website doesn't support CloudFront Origin Access Identity (OAI). As mentioned in the Objectives, the site should be accessed from CloudFront only, which means I need the OAI functionality.
Recap - AWS Static Website Option
AWS Static Website Option should be disabled when served behind a CloudFront distribution.
CloudFront Invalidation
A CloudFront invalidation is the part where you purge the cache after pushing static content HTML/CSS/JS/etc., to the S3 bucket.
Later on, when I push new content, I will invalidate the cache to get immediate results. It's either that or setting the CloudFront's distribution TTL to a lower number than the default 86400 seconds (24 hours).
Create a bucket
The name doesn't matter as long as it's a valid S3 bucket name and that name is globally available across ALL AWS accounts.
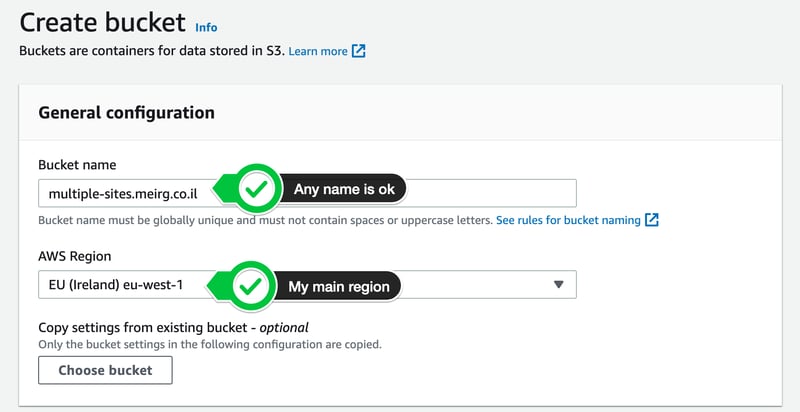
As you can see, I chose a logical name for my bucket (luckily, it was available)
multiple-sites.meirg.co.il
IMPORTANT: The S3 bucket name doesn't have to be the same as your DNS records. If the name is taken, add a suffix like -site or any other logical suffix that would make sense when you search for the S3 bucket by name. In this solution, The S3 bucket is served behind a CDN (CloudFront), so its name doesn't matter.
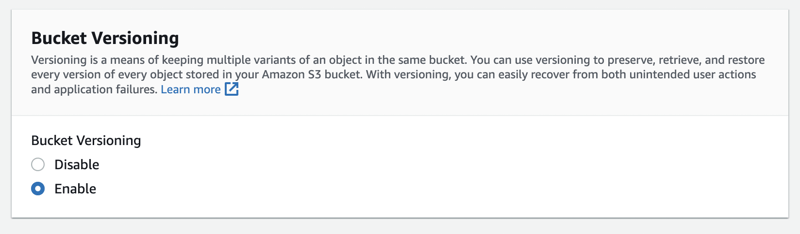
Scroll down, keep the Block all public access ticked, and set Versioning to Enabled.
(3/6) Push Website Content To S3
By "push", I mean upload; I use the verb "push" because I want to keep in mind that an automated CI/CD process should "push" the content instead of "uploading" it manually via S3 like I'm about to do now.
Following the bucket creation, I've created two directories (folders); as promised in the beginning, each directory will serve a different website.
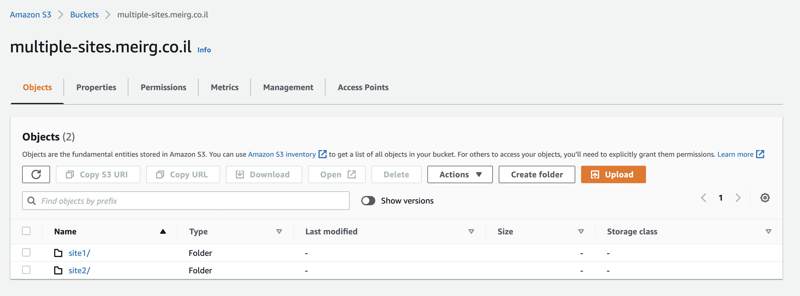
And then (Dobby again), I've created this dummy index.html file and made two copies, so I can differentiate between the sites when I check them in my browser.
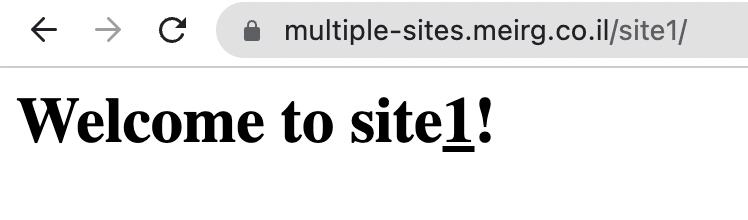
site1/index.html
<h1>Welcome to site<u>1</u>!</h1>
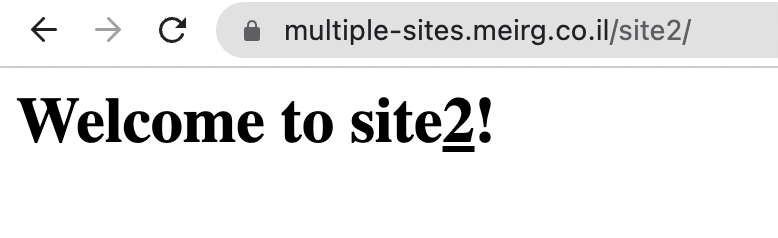
site2/index.html
<h1>Welcome to site<u>2</u>!</h1>
Moving on to the tricky parts - Creating a CloudFront distribution and Lambda@Edge!
(4/6) Create A CloudFront Distribution
As part of this step, we'll also create (automatically) an Origin Access Identity, enabling access for CloudFront to the S3 bucket; Currently, none is allowed to view the websites.
Once you choose the CloudFront service, you're redirected to the "Global" region, don't let it fool you; it's considered as N.Virginia (EU-east-1), creating the ACM certificate in N.Virginia is essential, as it's the same region where CloudFront is hosted.
The story continues; I've created a CloudFront distribution and searched for my bucket multiple-sites.meirg.co.il as the Origin. The name of the origin was automatically changed in the GUI to multiple-sites.meirg.co.il.s3.eu-west-1.amazonaws.com.
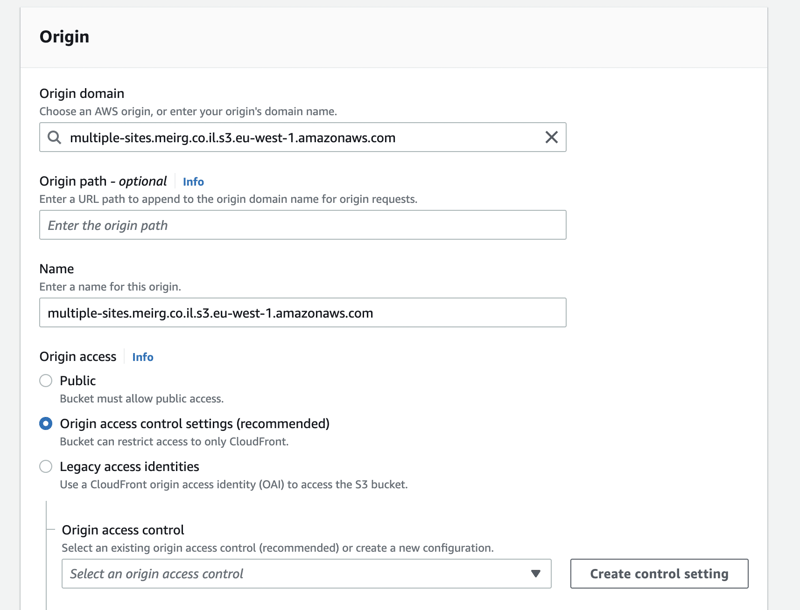
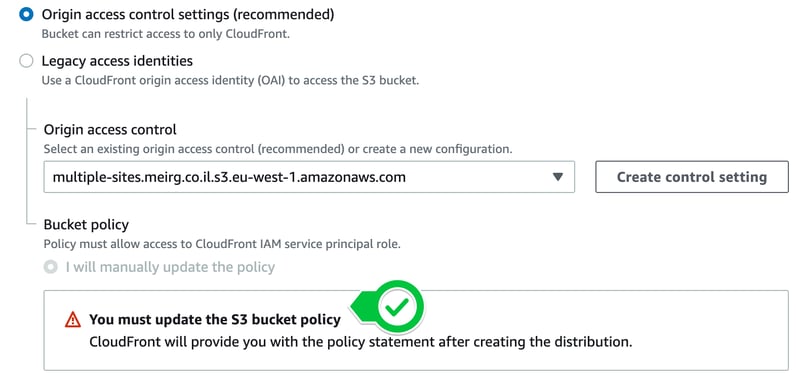
To create an OAI, I've clicked the Create control setting button, and after reading Advanced settings for origin access control, I chose Always sign origin requests (recommended setting) since my bucket is private (future to be accessible only via CloudFront).
NOTE: I also realized that OAI had become legacy, and I should start using the Access Control Setting feature instead.
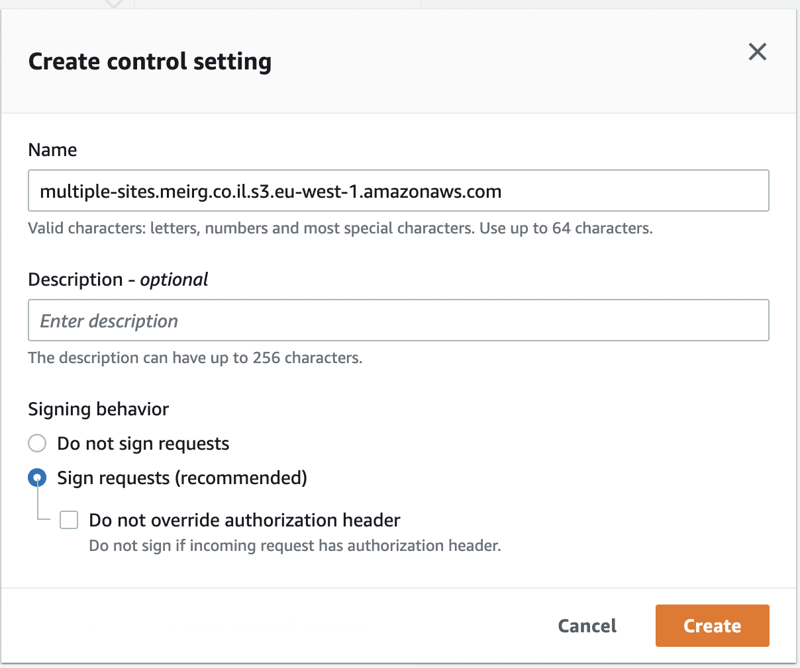
For cache key and origin requests, I've selected CORS-S3Origin, which is a must; otherwise, you'll get a 502 error due to failure of signing requests (try it).
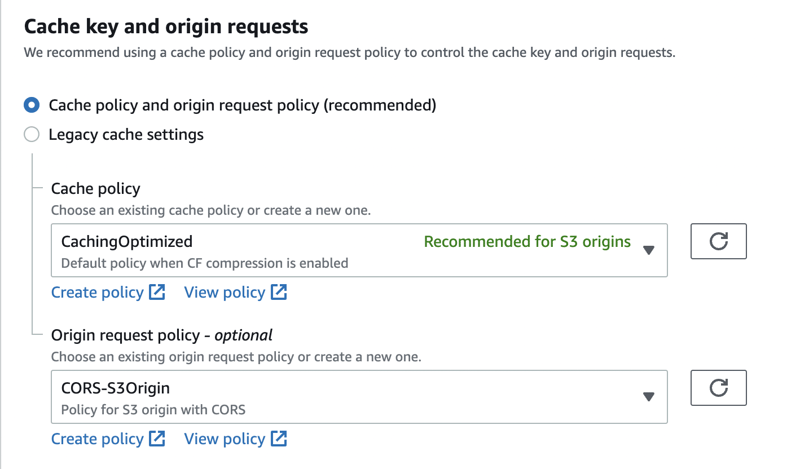
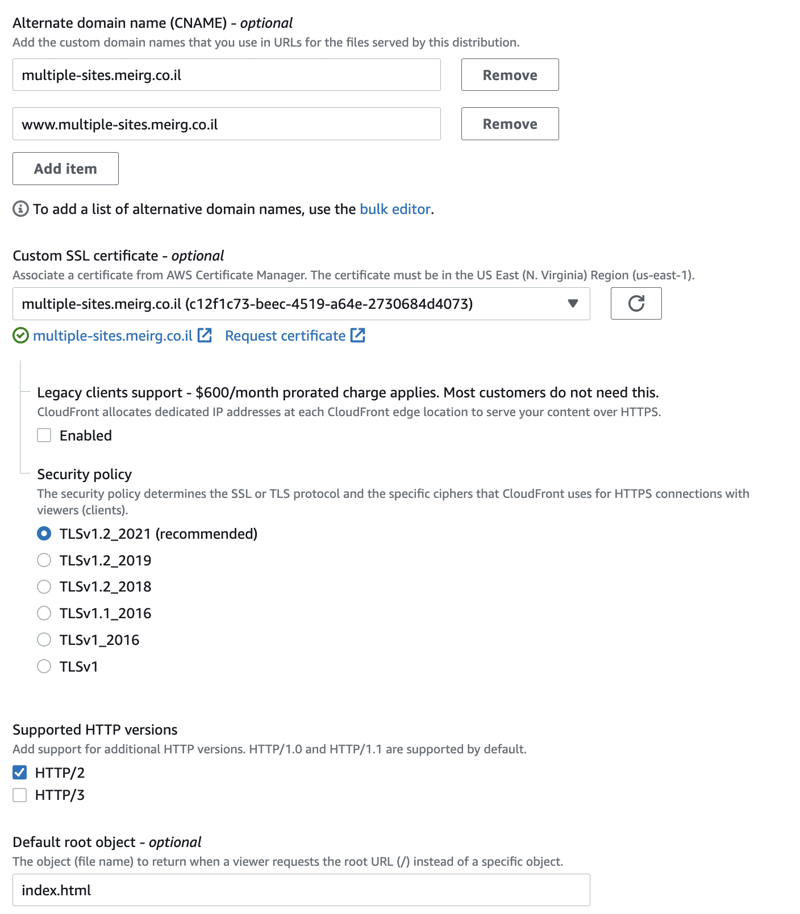
I was surprised by the excellent UX (not kidding); After creating the CloudFront distribution, I got the following pop-up.

As instructed, I clicked Copy policy and the highlighted link Go to S3 bucket permissions to update policy, scrolled down a bit to Bucket Policy, and clicked Edit.
In this screen, I pasted the copied policy, and it got a bit messed up (no idea why), so I made sure the curly braces at the top { and in the end } are not indented at all, and then I was able to click Save Changes (scroll to bottom) without an issue.
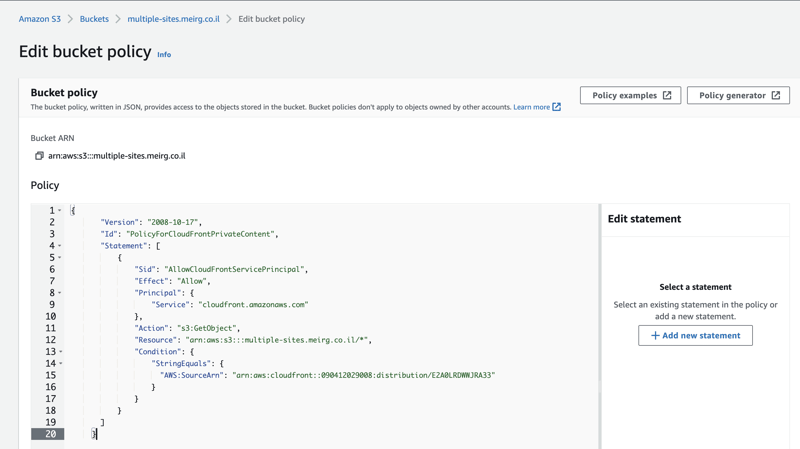
Here's what it looks like after clicking the Save Changes button.
Recap So Far
- Created an ACM certificate in N.Virginia (us-east-1) with eligible DNS records
multiple-sites.meirg.co.il*.multiple-sites.meirg.co.il
- Created an S3 bucket in Ireland (EU-west-1) and named it
multiple-sites.meirg.co.il - Pushed two websites to the S3 bucket
site1/index.htmlsite2/index.html
- Created a CloudFront distribution and updated the S3 bucket with the generated Access Control Bucket Policy
(5/6) Map DNS record to CloudFront
For testing purposes, I've created another index.html file; Remember that I set a Default Root Object during the CloudFront distribution creation? That is it.
<h1>Welcome to root site!</h1>
The new index.html file is pushed to the root directory / of the bucket; Before moving on to the "site per directory solution with Lambda@Edge" I want to make sure that everything is in place and that https://multiple-sites.meirg.co.il works as expected.
So now my S3 bucket looks like this:
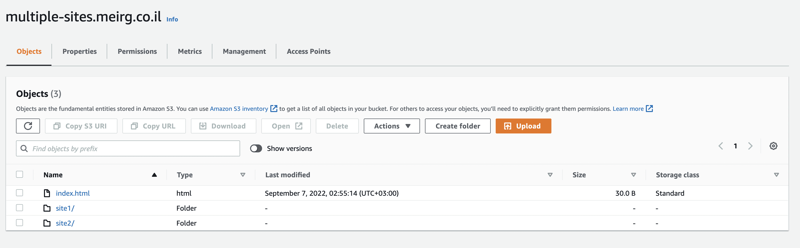
- FQDN Served by CloudFront (Not Reached) - https://multiple-sites.meirg.co.il
- S3 Direct Access Link (Forbidden) - https://s3.eu-west-1.amazonaws.com/multiple-sites.meirg.co.il/index.html
The FQDN is still unavailable as I haven't added the DNS record in my DNS Management Provider (Cloudflare); As of now, none knows that my website multiple-sites.meirg.co.il should point to the created CloudFront distribution.
Copied the CNAME of the CloudFront distribution
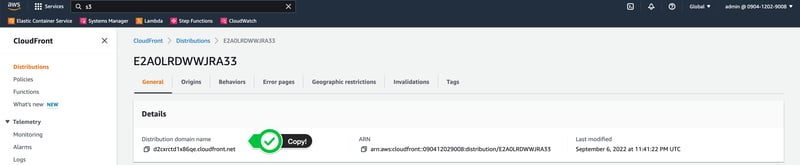
And created a new DNS record for that CloudFront distribution CNAME; Since I'm already using CloudFront as a CDN, I prefer to disable Cloudflare's proxy feature, as It'll be CDN to CDN, which sounds like a bad idea.
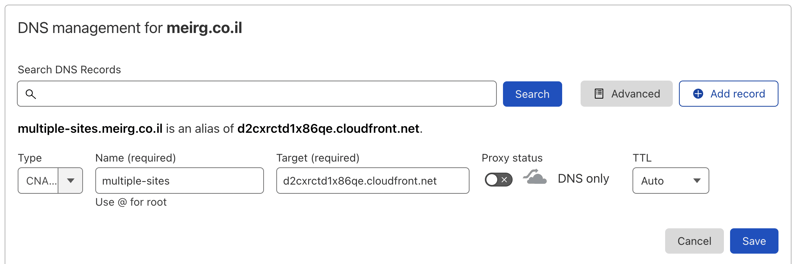
Testing the root site https://multiple-sites.meirg.co.il ...
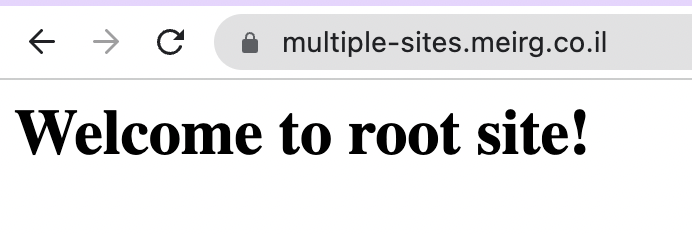
It worked 🥳 but that's not why we're here for! Moving on to the multiple directories magic. Why magic, you ask? The nested paths /site1,/site2 are restricted/forbidden; here's how accessing /site1 looks like at the time of writing this blog post:

(6/6) Create A Lambda@Edge Function
Writing code is excellent; copying from someone else and understanding what it does is even better. After Googling a bit, I stumbled on Implementing Default Directory Indexes in Amazon S3-backed Amazon CloudFront Origins Using Lambda@Edge
contains the exact code that I need.
I copied the snippet from the mentioned site and removed the console.log; I'll add them back if I need to debug.
'use strict';
exports.handler = (event, context, callback) => {
// Extract the request from the CloudFront event that is sent to Lambda@Edge
var request = event.Records[0].cf.request;
// Extract the URI from the request
var olduri = request.URI;
// Match any '/' that occurs at the end of a URI. Replace it with a default index
var newuri = older.replace(/\/$/, '\/index.html');
// Replace the received URI with the URI that includes the index page
request.URI = newuri;
// Return to CloudFront
return callback(null, request);
};
How Does The Lambda@Edge Work?
By default, if an origin request URI doesn't contain file path, like navigating https://multiple-sites.meirg.co.il/site1/; An error will be raised since there's no default setting for sub-directories to use the hosted site1/index.html.
So why does it work when I navigate the root path of the bucket https://multiple-sites.meirg.co.il/? Because I've set the Default Root Object to index.html in the CloudFront distribution. That "fixes" the issue for a single website hosted at the root of an S3 bucket.
When it comes to multiple websites stored in the same S3 bucket, we need a mediator/proxy that will convert the origin request URI from / to /index.html, which is precisely what the above-copied code snippet does.
Create The Lambda@Edge Function
Firstly, in which region should I create the Lambda@Edge Function? .... Can you guess? ......... N.Virginia (us-east-1)! Reminding you that all CloudFront-related resources need to be located in N.Virginia (us-east-1).
Go ahead and create a Lambda Function in N.Virginia, and keep the default settings "Author from scratch > Node 16.x", reminding you that the Lambda Function's code snippet was in JavaScript.
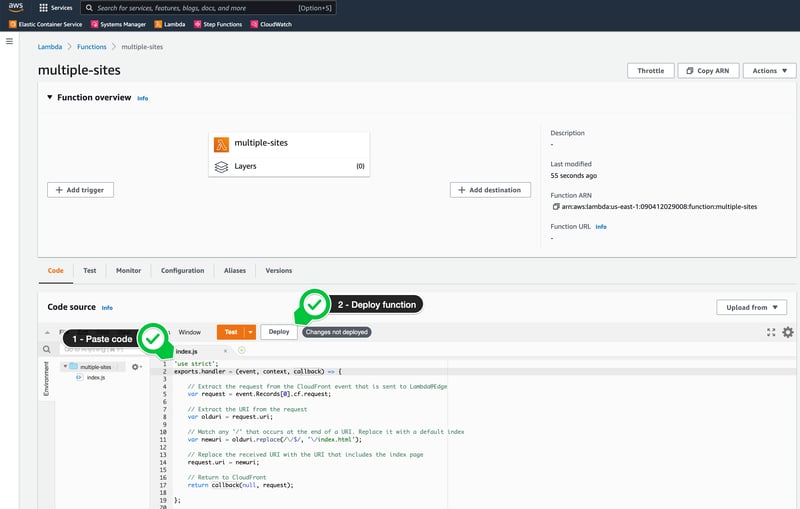
Publish new version
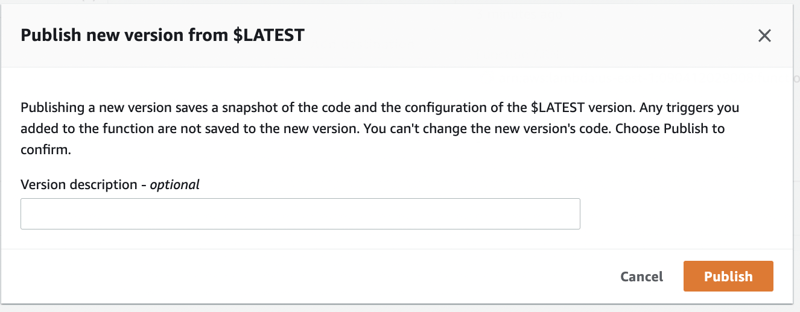
This step is mandatory as Lambda@Edge functions are referenced with versions, unlike normal Lambda Functions can be referenced using the $LATEST alias.
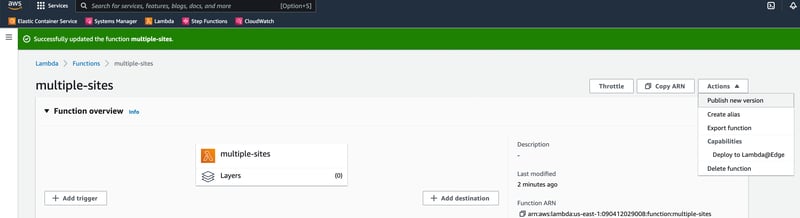
Deploy Lambda@Edge To The CloudFront Distribution
Navigate back to the function and
Deploy to Lambda@Edge!
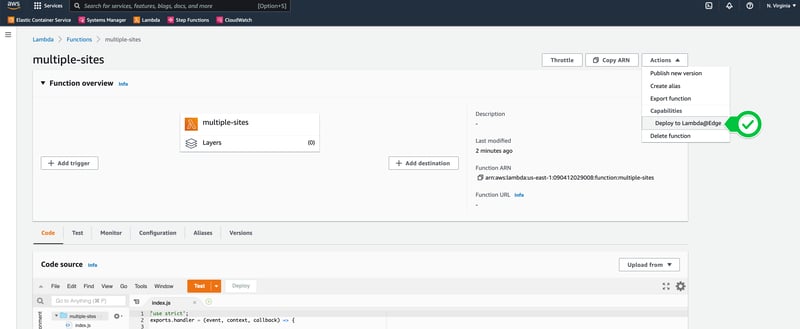

I clicked Deploy (with excitement), and then I got this pop-up message:
Correct the errors above and try again.
Your function's execution role must be assumable by the edgelambda.amazonaws.com service principal.

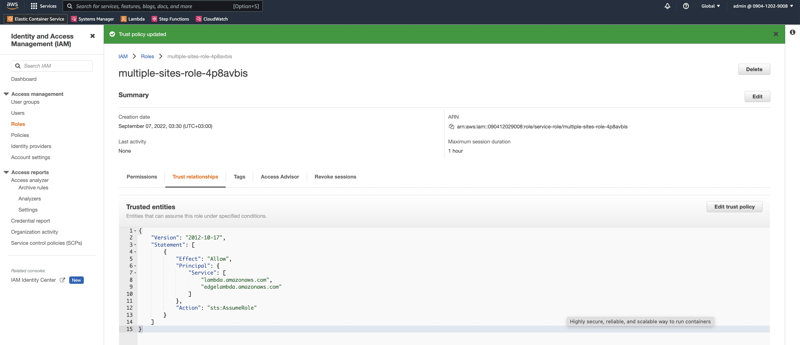
Hold on a sec; I need to add a Trust Relationship, so CloudFront is allowed to execute the function. Googling a bit got me here - Setting IAM permissions and roles for Lambda@Edge; the copying motive continues as I copied the IAM policy from that page
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": [
"lambda.amazonaws.com",
"edgelambda.amazonaws.com"
]
},
"Action": "sts:AssumeRole"
}
]
}
After that, I edited the Lambda Function's IAM role Trust Relationship.
Let's try to deploy the Lambda Function again ... And of course, another error ...
Cannot read properties of undefined (reading 'startsWith')

Oh well, I refreshed the Lambda Function's page ... I Tried to deploy again ... Finally, deployed!
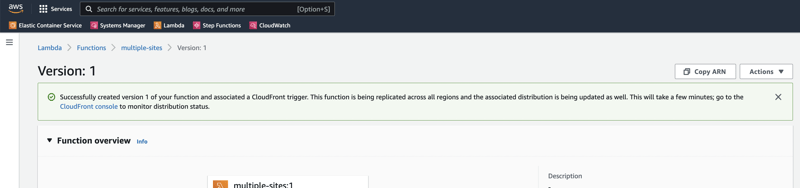
Results
I'm not sure if I did it or if it happened automatically. Still, I think it's important to document it - initially, I got to the 403 Forbidden page when trying to access https://multiple-sites.meirg.co.il/site1/, so I checked the CloudFront distribution and found out that the S3 origin is set to Public, and I have no idea how or why that happened. So I changed it back to Origin access control settings (recommended), and everything works as expected.
Final Words
Initially, I wanted to use an Origin Access Identity (OAI) to restrict to CloudFront only. Then I discovered that OAI is considered legacy, so I proceeded with Access Control, and I'll probably migrate all my OAI resources to Access Control.
I left out (for now) the "S3 redirect from www" part because this blog post is already overkilled.





Top comments (3)
Thank you so much!
Your post helped me big time!
I had a slightly different need where I did not want the directory's leading slash (/) to be the parameter for invoking the index.html page,
instead of =
www.website.com/abcd/I wanted =
www.website.com/abcdand for anything except
/abcdlike =/abcor/abceor/abcdeI wanted my default 404.html page (configured in cloudFront) to load.so I modified the Lambda@Echo function to something like this with help of chatgpt ->
(looks big due to added comments, else it's short only)
With this I don't have to care if the / is written in the URL or not, the site is always accessible. ❤️
For some unknown reason, I had to replace the paths of asset files in my index.html file with their equivalent AWS storage bucket URLs for this to work, because it requires / in the url end to determine the root of folder, which I was purposely trying to avoid in this case as we saw.
I'm still curious is this the only approach?
What if I was using GCP or AZURE?
How can it be done there?
How do people usually get around this?
Any Ideas if possible will be highly appreciated, thanks!
Hey Deepansh, I'm glad you found it useful!
Regarding your query, you said you had to change your paths - usually, when you create a static website, it is generated by a framework like Vue, ReactJS, Angular, etc.
In most of these frameworks there's a "public_path" attribute which acts as the meta base url of your website, and then all paths are relative to that path.
Is that what you mean? Feel free to elaborate
Okay! yes I understand it now… Seems like I was unaware about the "public_path" attribute.
Just looked into it and I’ll implement it now.
Thanks again Meir!