Hash tables are a very time efficient way to store data in the form of key value pairs. Hash tables have a O(1) time complexity in accessing data, and almost nearly as fast in inserting (adding) data.
Hash tables are also called objects in JavaScript, dictionaries in Python, and hashes in Ruby.
To first understand how hash tables work, first lets understand how arrays work.
Say you had an array of your extended familial relations. It might looks like:
fam_array = ["Uncle", "Aunt", "Cousin", "Cousin"]
In this situation the keys of each item are automatically indexed as numbers. With the first item starting at 0 each item is assigned a sequential key. In most languages there is a syntax to access an item in the array via index notation. Calling fam_array[0] would return "Uncle".
This retrieval is very fast and inefficient because behind the scenes the 0 is actually a pointer for a specific location in memory. Memory itself can be thought of as its own array. Memory is a linear line of cells each "indexed" with a its own addressing system. This addressing system uses hexadecimal, which is base-16 numerating.
Let's take a look at this diagram of memory.
=============== Highest Address (e.g. 0xFFFF)
| |
| STACK |
| |
|-------------| <- Stack Pointer (e.g. 0xEEEE)
| |
. ... .
| |
|-------------| <- Heap Pointer (e.g. 0x2222)
| |
| HEAP |
| |
=============== Lowest Address (e.g. 0x0000)
As a refresher, the stack is where the program's functions and variables are loaded, looped, and run. The heap is where non-primitive objects and arrays are stored, and are referenced at by the stack.
In our example, fam_array is declared in the stack then assigned a pointer to a location in the heap which houses the actual array of ["Uncle", "Aunt", "Cousin", "Cousin"]. When fam_array[0] is called, the 0 acts as a pointer to the string "Uncle" in the heap with its addressed as some hexadecimal, like 0x0f403...23c.
This method of using a number 0 as a pointer is extremely, extremely time efficient. It is a direct pointer to a spot in memory.
The idea of hash tables is to bring that access efficiency of arrays to the more human-readable way of storing information in a key-value pair schema.
Let's transform that array into a hash table, and add the following keys with names:
fam = {
bob: "Uncle",
mary: "Aunt",
leo: "Cousin",
cher: "Cousin",
}
Here each key is a string of a name. The value is that person's familial relation.
Computers don't really like using strings such as "bob" to store data. "bob" isn't a pointer to a place in memory and can't be used in the same way a number index like 0 in the previous example of arrays could be.
The solution is to transform the key into an numbered index by using a hash function.
A hash function turns keys into unique index, as if it were an array. This hashing is of course what gives hash tables its name.
The key in the key-value pair "bob": "Uncle" would be run through a hash function, then given an index. What returns a number that is smaller than the length of the hash table. In this case, the hash table is four items long, so the maximum index "bob" would hash into is 3.
In psudeocode this would look like these two steps:
- hashed_key = hash(key)
- index = hashed_key % array_size
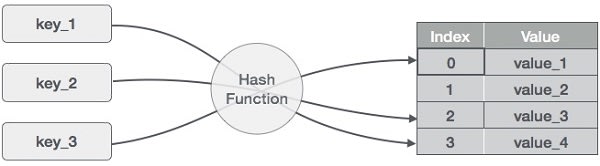
Colloquially these two steps are referred to the "hash function".
This hashing process is run every time a hash table is created, accessed, modified. Hashing is a semi-random process that takes an input and outputs a ranom-looking string of a fixed bit length. Hashing algorithms vary, but their main purpose is to generate a unique looking number based on an input. bob might hash into the hexidecimal 0x34acc53, but bo which is only one letter different might hash into 0x667df3d. Either way hashing bob or bo will always yield the same result.
So, using the example of the hash fam, I could access the value of the "bob" key by writing something like fam[:bob] or fam.bob.
This would require the language to hash the string or symbol bob into a number (often represented as hexidecimal), then modulo it (%) to find its index. When it has the index, then the retrieval process becomes like that of an array: the index is now a pointer to place in memory.
The hashing algorithm used in hash functions varies depending on the language. Ruby, for instance, has some differences than the general hashing alogorithm described above. For one, Ruby does not % array_size. Ruby sets a fixed array size of 11 by default, and indexed each hash by % 11. Ruby calls these 11 spots in array "bins".
There will also be instances where hash functions produce the same index. fam.leo might hash into index 2, and fam.bob might also hash into index 2. This is called a collision. Every language has different collision handling. Ruby creates linked lists to handle collisions. Since both leo and bob are at index 2, both bob and leo will be placed there. This linked list is essentially an array that looks like:
[ ["bob", "next is leo"], ["leo", "next is ?"] ]
Now, when fam.leo is called, "leo" is first hashed into 0xff65cc, then % by 11, which returns index 2. At index two there is a linked list. Now Ruby iterates through this list (this is O(n) time complexity at this point) and looks for matches to the string "leo" using .equal?.
When linked lists get longer than 5 items, then it re-runs the hash through a hashing function and makes a larger bin size.
Linked listing is just one way to handle collisions. There is also linear probing, quadratic probing, and also running % array_size as a technique to reduce collisions. In practice most languages use a mix of techniques.
So the conclusion is that if there are lots of collisions in a hash, then in fact the lookup time is not O(1), but closer to O(log n)!
Sources:
https://www.hackerearth.com/practice/data-structures/hash-tables/basics-of-hash-tables/tutorial/
https://www.sitepoint.com/diving-into-how-hashes-work-in-ruby/





Top comments (2)
Thank you!
what a great explanation of hash under the hood anywhere. I didn't know that the hash also creates a numeric value like arrays do. thank you