FLaNK: Real-Time Transit Information For NY/NJ/CT (TRANSCOM)
SOURCE : XML/RSS REST ENDPOINT
FREQUENCY : Every Minute
DESTINATIONS : HDFS, Kudu/Impala, Cloud, Kafka
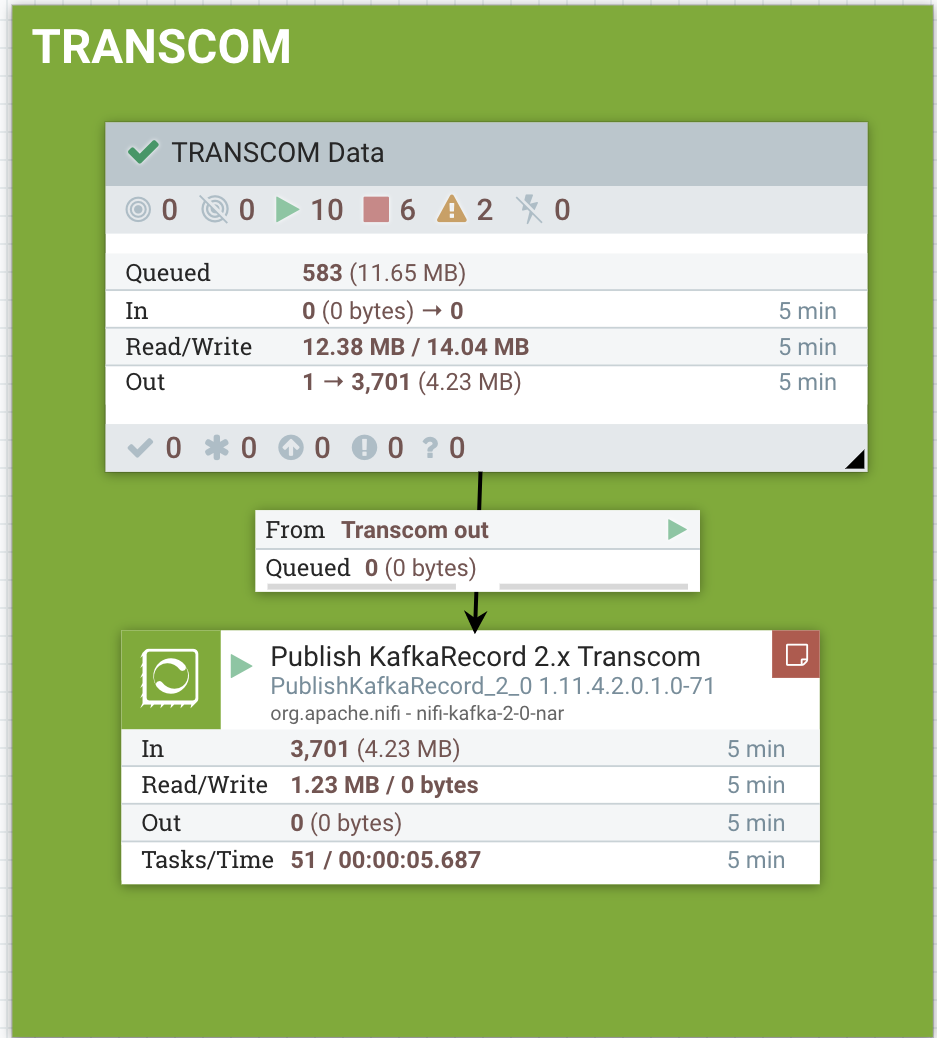
The main source of this real-time transit updates for New Jersey, New York and Connecticut is TRANSCOM. I will read from this datasource every minute to know about real-time traffic events that occurring on the roads and transportation systems near me. We will be reading the feed that is in XML/RSS format and parse out the hundreds of events that come with each minutes update.
I want to store the raw XML/RSS file in S3/ADLS2/HDFS or GCS, that's an easy step. I will also parse and enhance this data for easier querying and tracking.
I will add to all events a unique ID and a timestamp as the data is streaming by. I will store my data in Impala/Kudu for fast queries and upserts. I can then build some graphs, charts and tables with Apache Hue and Cloudera Visual Applications. I will also publish my data as AVRO enhanced with a schema to Kafka so that I can use it from Spark, Kafka Connect, Kafka Streams and Flink SQL applications.
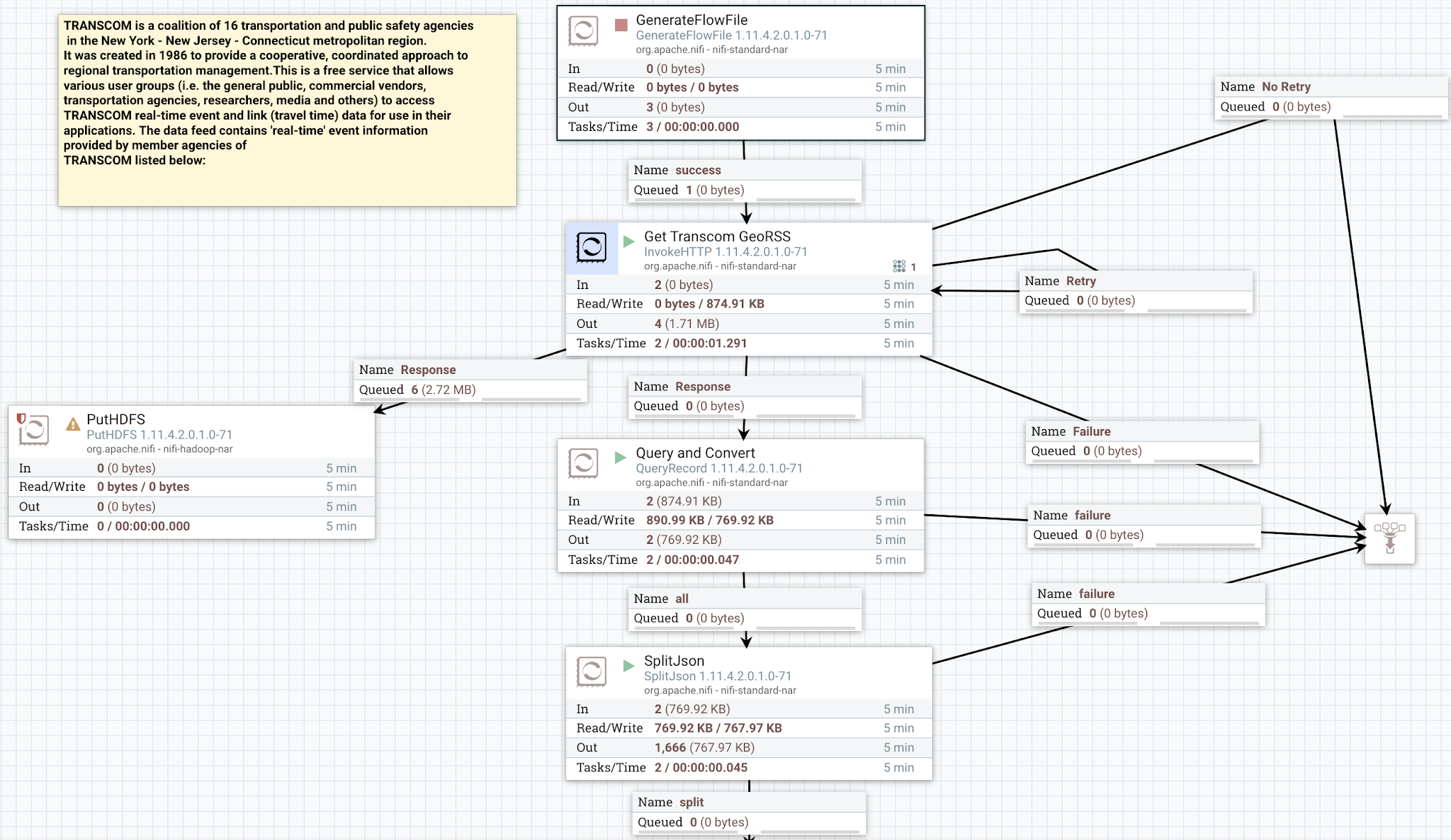
- GenerateFlowFile - optional scheduler
- InvokeHTTP - call RSS endpoint
- PutHDFS - store raw data to Object or File store on premise or in the cloud via HDFS / S3 / ADLSv2 / GCP / Ozone / ...
- QueryRecord - convert XML to JSON
- SplitJSON - break out individual events

- UpdateAttribute - set schema name
- UpdateRecord - generate an add a unique ID and timestamp
- UpdateRecord - clean up the point field
- UpdateRecord - remove garbage whitespace

- PutKudu - upsert new data to our Impala / Kudu table.
- RetryFlowFile - retry if network or other connectivity issue.
Send Messages to Kafka
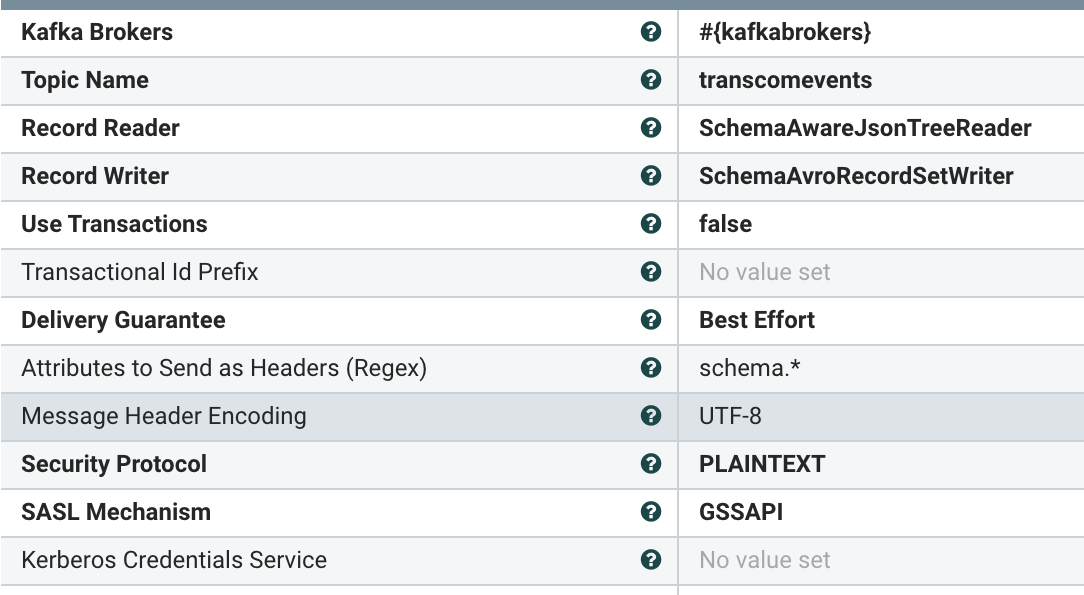

Our flow has delivered many messages to our transcomevents topic as schema attached Apache Avro formatted messages.



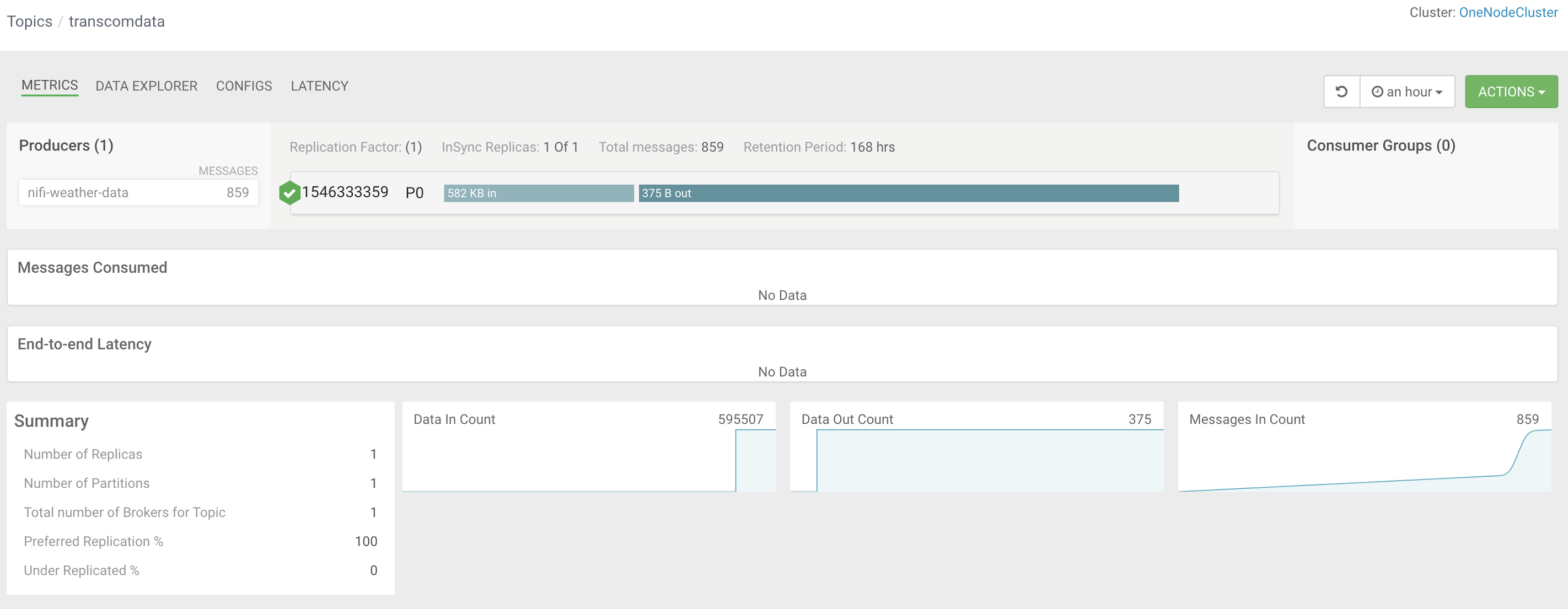
SMM links into the Schema Registry and schema for this topic.
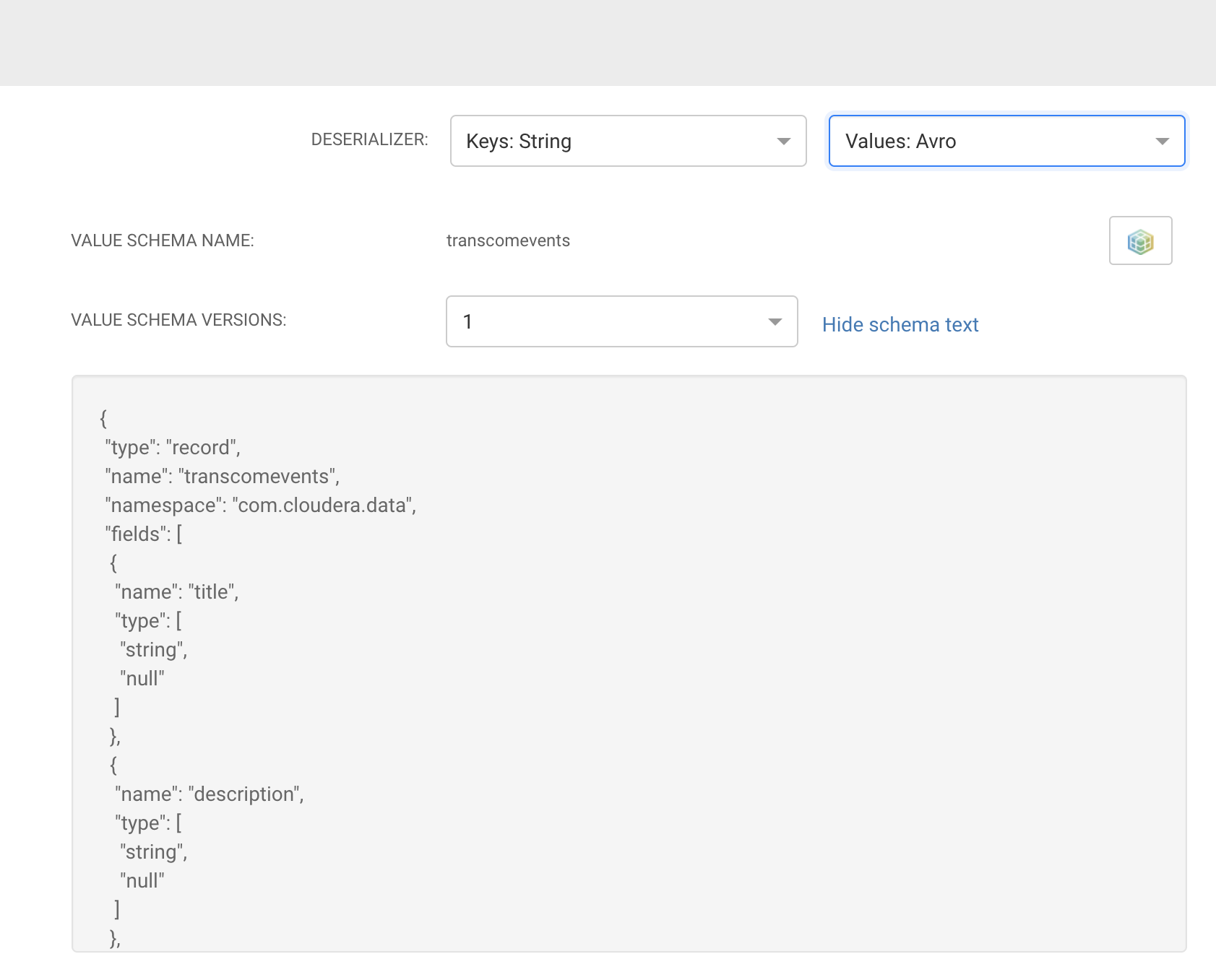
We use a schema for validation and as a contract between consumers and producers of these traffic events.
![]()
Since events are streaming into our Kafka topic and have a schema, we can query them with Continuous SQL with Flink SQL. We can then run some Continuous ETL.


We could also consume this data with Structured Spark Streaming applications, Spring Boot apps, Kafka Streams, Stateless NiFi and Kafka Connect applications.
We also stored our data in Impala / Kudu for permanent storage, ad-hoc queries, analytics, Cloudera Visualizations, reports, applications and more.
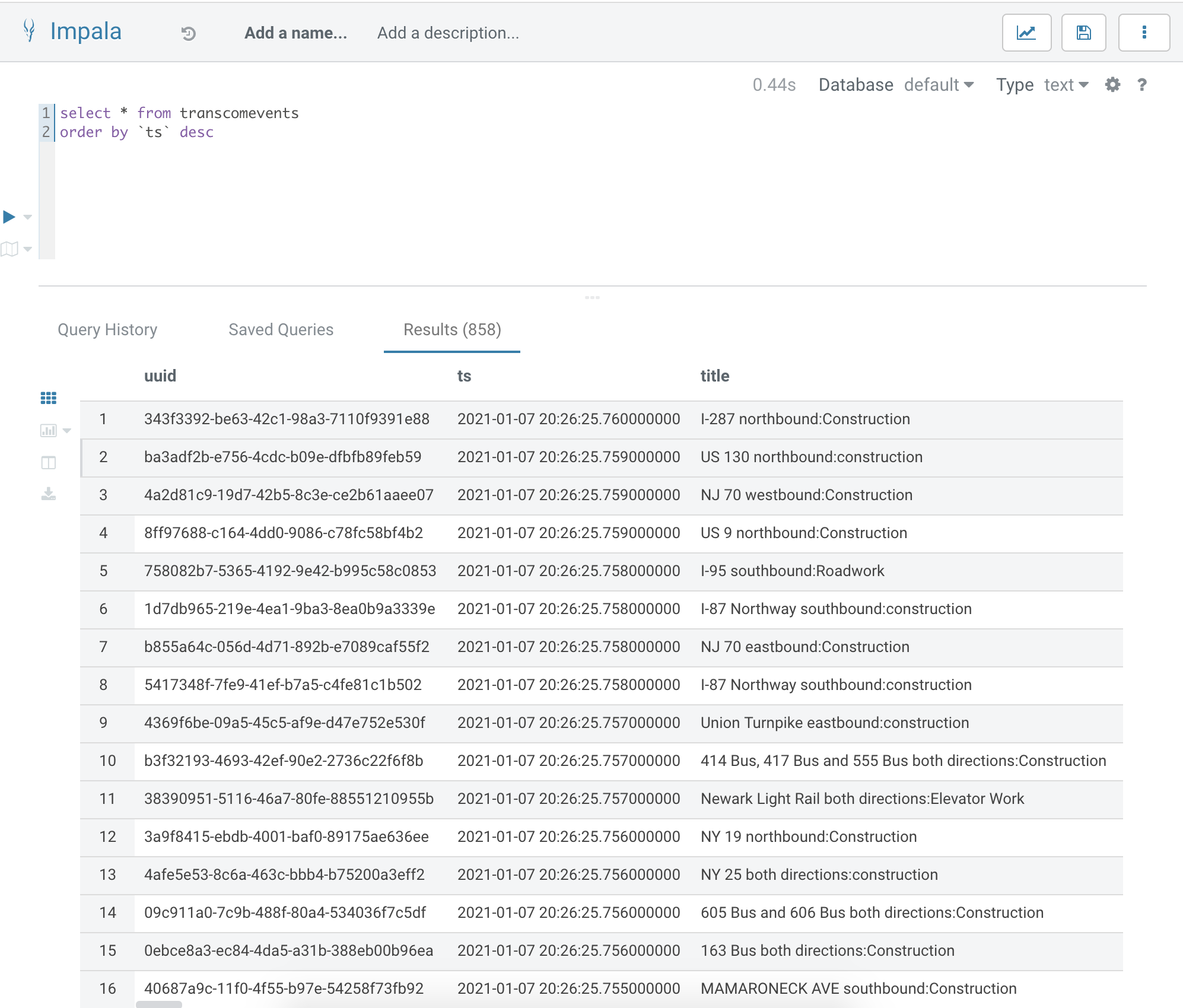
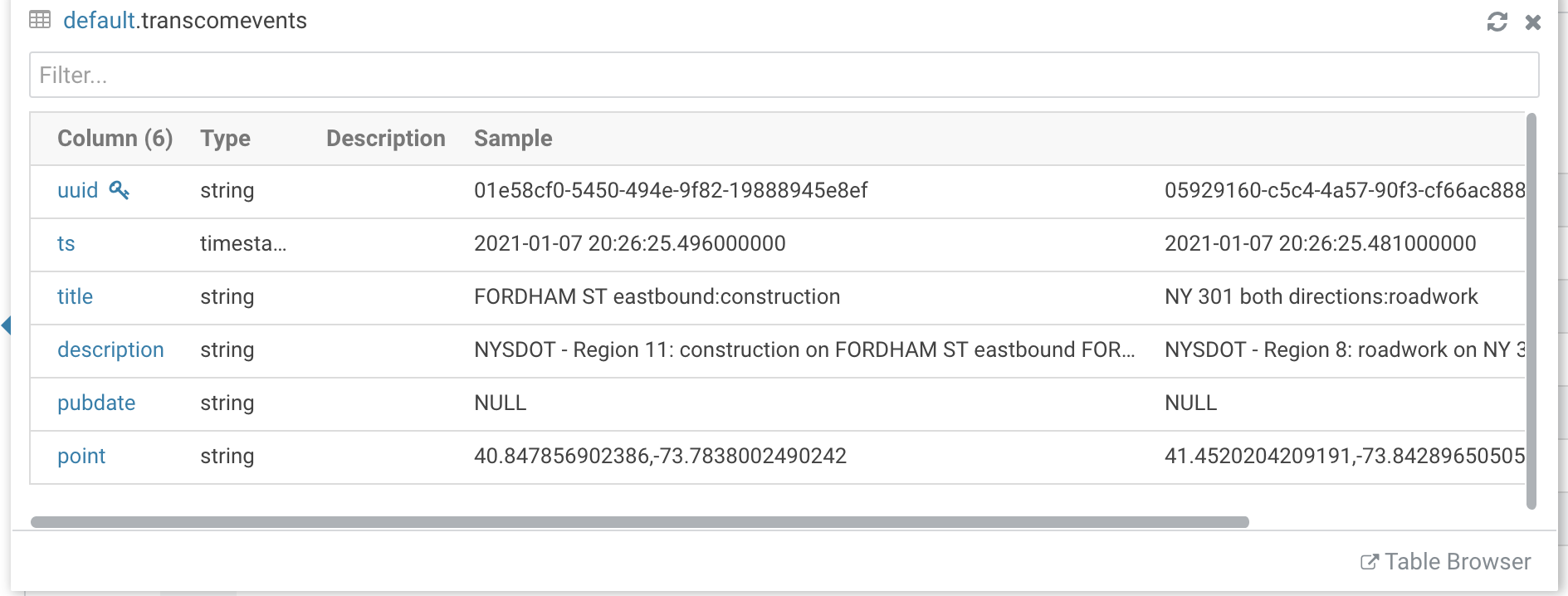
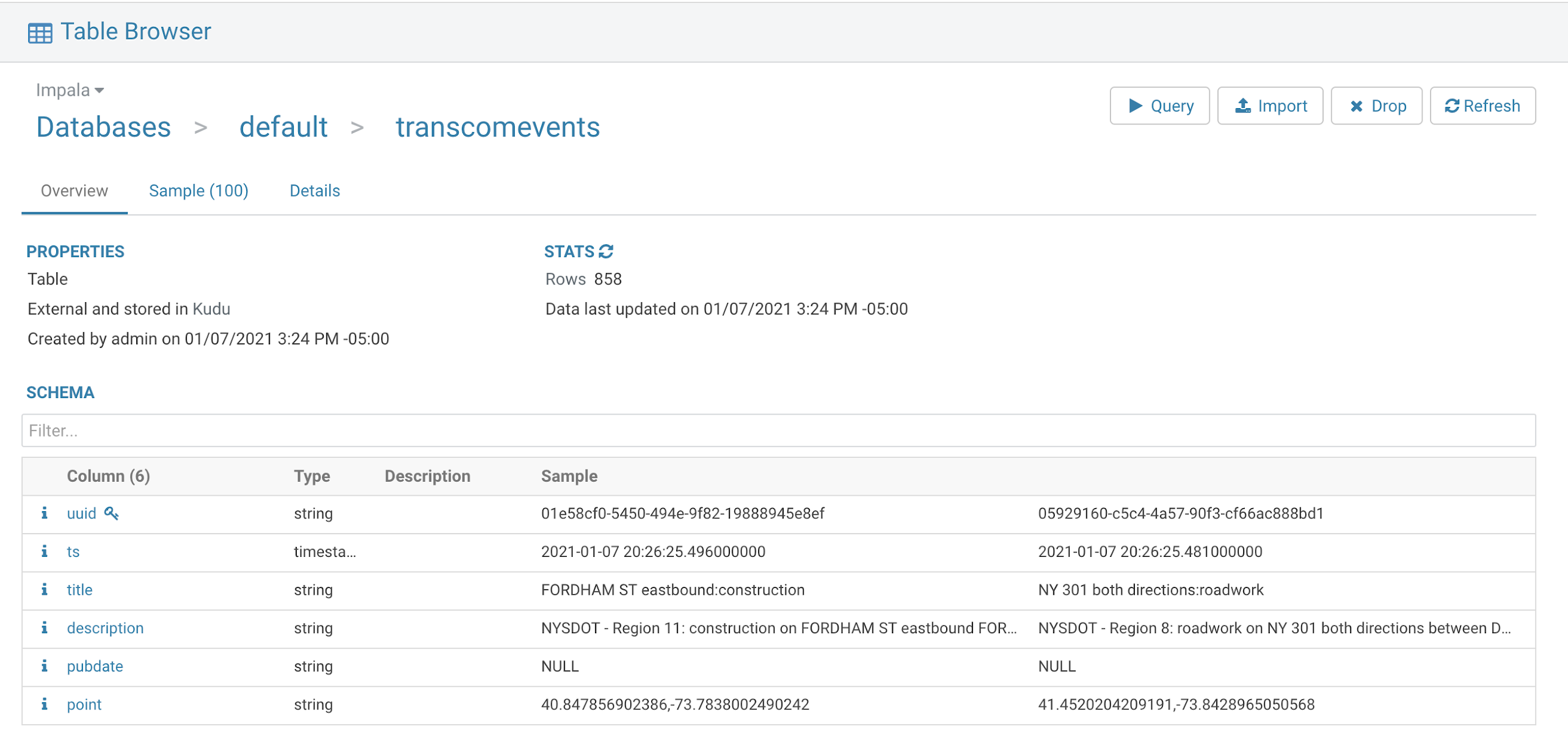
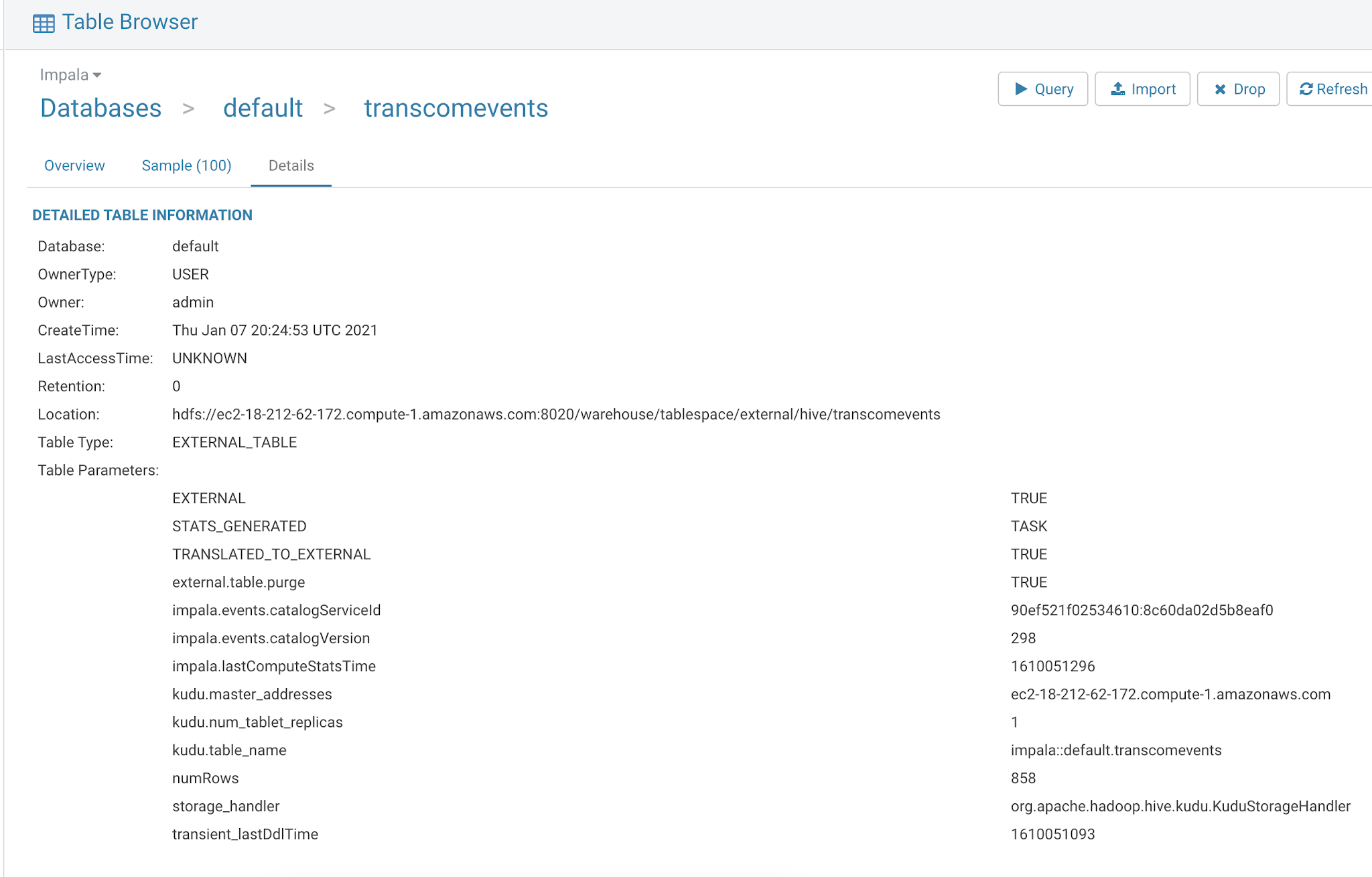
It is very easy to have fast data against our agile Cloud Data Lakehouse.





Top comments (1)
Hi Tim, We have a Flafka cluster with Kafka-Ambari-Zookeeper-Flume-RabbitMQ-HDFS Clouderra stack, we had a electric surge a month ago, after that incident, we lost some blocks in HDF with bad, but now Flume fails to deliver the same count of topic partition messages to HDFS, there is no lag or offset difference, but balance of messages flown from Kafka is dissipated in Flume sinks or lost without reaching HDFS destination successfully, flume dissolving messages in the headband. We are having problems sinking hdfs. When it restarts, it corrects, but after a certain time flume cannot write.
dev-to-uploads.s3.amazonaws.com/i/...