
Marko recently released a preview for its upcoming Tags API. This is pretty exciting as it adds a minimal API layer over Marko's state management that allows us to express complicated ideas in a more terse way than ever before.
So what's a good place to start. Well, I looked at Marko's TodoMVC example and decided it needed sprucing up. So this simple list managing example feels like the perfect place to get started and introduce this new approach.
In this article, we will build a TodoMVC application using Marko's Tags API. So let's get started.
Setting up our project
It's easy to get set up with a new Marko project using the Tags API.
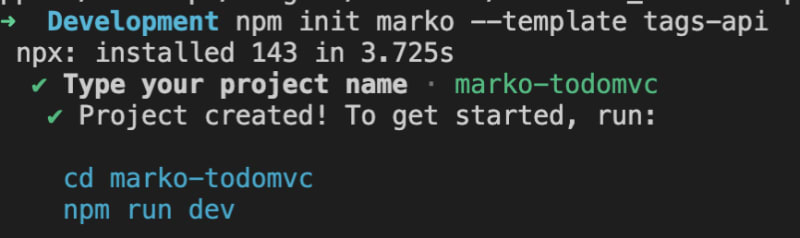
> npm init marko --template tags-api
It prompts us to name the project and gives instructions to get started.
Next, let's open our project in our code editor. I am using VSCode. And we see a simple folder structure.

We are going to keep this folder structure for our TodoMVC app but we will be replacing all the code. Before that, if you want to run npm run dev to see this example open in your browser.
Remove all the files under the src/pages and src/components folders and then we are good to get started with a clean slate.
Building our Page
Marko is a Multi-Page Framework but TodoMVC is a simple single-page example. We won't worry too much about that since our starter project here will take care of all the details. So we start the same as any application and our index page. Create a index.marko file under your src/pages folder.
Let's add some markup to it. .marko files are basically HTML documents so to start we just add the following:
<!doctype HTML>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<meta name="description" content="Marko TodoMVC"/>
<title>Marko - TodoMVC</title>
</head>
<body>
</body>
</html>
And there we have a working app. Just run npm run dev and you should see a blank page with a title. You could add as much markup you want to this page. But let's add our first components.
Creating a Store
TodoMVC is driven off a central store very much in line with Model View Controller from which it gets its name. In our case, Marko isn't an MVC framework but it still makes it easiest to abstract our logic into a template that we will use as a data store.
Create TodoStore.marko under components folder and copy in this code:
<let/nextId=1/>
<let/todos=[]/>
<let/filter="all"/>
<return={
todos,
filter,
setFilter(f) { filter = f },
updateTodo(todoId, newProps) {
todos = todos.map(function(todo) {
if (todo.id !== todoId) return todo;
return { ...todo, ...newProps }
})
},
clearCompleted() {
todos = todos.filter(function(todo) {
return !todo.completed;
});
},
removeTodo(todoId) {
todos = todos.filter(function(todo) {
return todo.id !== todoId;
});
},
toggleAllTodosCompleted(completed) {
todos = todos.map(function(todo) {
if (todo.completed === completed) return todo;
return { ...todo, completed };
});
},
addNewTodo(todoData) {
todos = [...todos, {
title: todoData.title,
id: 'c' + (nextId++),
completed: false
}];
}
}/>
There is a lot going on in this file but really we are just seeing 4 tags being used in the template. The first 3 define state in our Marko Templates using Marko's <let> tag. The <let> tag allows us to define variables in our template. In this case, an id counter, the list of todos, and a variable to hold are filter state.
This leverages Marko's tag variable syntax where we can define a variable by putting it after a slash after the tag name, and Marko's default attribute syntax that lets us pass a value without an attribute name by assigning it to the tag directly.
The <return> tag is how we expose tag variables to a parent template. We are assigning an object that contains our state and some methods to mutate that state.
This template does not render any DOM elements itself but serves as a convenient way to encapsulate the behavior we'd like to use in other templates. We will be using this to drive the rest of our application.
Creating the App
So let's start wiring this together. We're going to create a new <TodoApp> tag because I want to keep my top-level page document clean but this is completely unnecessary. So create TodoApp.marko under the components folder. Also, create a TodoHeader.marko file under the components folder as well since we will need that in a minute.
Let's start by dropping the following into TodoApp.marko:
<TodoStore/{
todos,
addNewTodo
}/>
<section.todoapp>
<TodoHeader addNewTodo=addNewTodo />
<if=todos.length>
<section.main>
<ul.todo-list>
<for|todo| of=todos by=(todo => todo.id)>
${todo.title}
</for>
</ul>
</section>
</if>
</section>
<style>
@import url("https://unpkg.com/todomvc-app-css@2.2.0/index.css");
</style>
We will be coming back to this file a few times in the course of this tutorial but this is the skeleton of our app. The first tag is our <TodoStore> we created in the previous section. We can access the values returned as a tag variable we are destructuring. So far it is just the todos and addNewTodo.
This is the bulk of our template. We are including the <TodoHeader> component we are yet to implement. One of the great things about Marko is it can find tags in your local project automatically saving the need to import them.
Next, we see a conditional <if> tag that only displays the list if todos.length. Marko uses tags for control flow. These use all the same syntax and capabilities you can use in your custom tags.
Inside this block, there is also the <for> tag that iterates over our todos. Each iteration of the loop receives its values via Tag Parameters which we denote with enclosing pipes | |. This allows us to do scoped child templating similar to Render Props in React.
Finally, there is a <style> tag that imports the official TodoMVC CSS from their CDN. Marko automatically strips out the style tag out into its own .css files on build.
We can add our <TodoApp> to the body of our index.marko page and we should now see a grey background when we run it with npm run dev (you can keep this running in the background and it will refresh as we add changes).
<!doctype HTML>
<html lang="en">
<head>
<meta charset="UTF-8"/>
<meta name="viewport" content="width=device-width, initial-scale=1.0"/>
<meta name="description" content="Marko TodoMVC"/>
<title>Marko - TodoMVC</title>
</head>
<body>
<TodoApp />
</body>
</html>
Adding Todos
Right now our app doesn't do very much so let's start working on the <TodoHeader>. This is where we will enter our new Todos.
Copy this into your TodoHeader.marko file:
<attrs/{ addNewTodo } />
<header.header>
<h1>todos</h1>
<form onSubmit(e) {
const titleInput = title();
addNewTodo({ title: titleInput.value });
titleInput.value = "";
e.preventDefault();
}>
<input/title
class="new-todo"
placeholder="What needs to be done?"
/>
</form>
</header>
<style>
.header form {
margin: 0;
}
</style>
The first thing you will notice is the <attr> tag. This is how we define the input that comes into our template. We passed addNewTodo in from the <TodoApp> template and now we can use destructuring to get it here.
You can see Marko's shorthand class syntax on <header.header> which applies the header class to the <header> element. From there we create a <form> with an <input>.
The tag variable on the input element returns an Element Reference Getter. This is a function that when called retrieves the native DOM reference to that tag. We use it in our Submit handler.
Marko supports a shorthand for functions that we are using here that is very similar to JavaScript object methods. This is the equivalent of assigning the function to an attribute of the same name. Our Submit handler calls the addNewTodos method from our store.
Try it in the browser. You should see a large input field, and you should be able to enter some text and click enter and see it added to our page. Right now they all just get appended in a long line of text but we will add more functionality to our Todos in the next section.
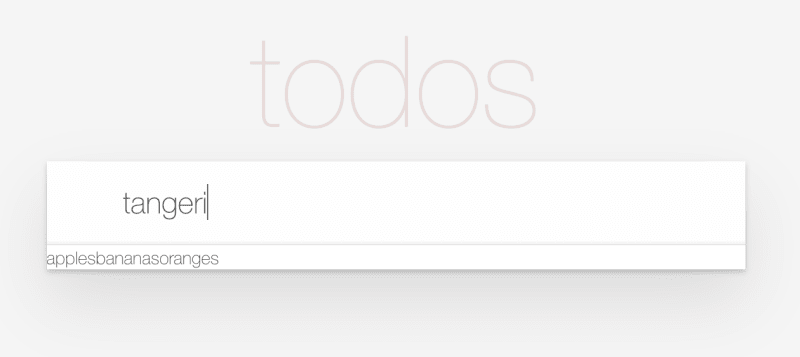
Making our Todos Functional
Well, it works but it ain't pretty. Let's now add our <TodoItem> component. So go ahead and add TodoItem.marko under your components folder and copy in the following.
<attrs/{ todo, updateTodo, removeTodo }/>
<let/isEditing=false />
<let/editingTitle="" />
<const/saveEdit() {
if (isEditing) {
const el = title();
updateTodo(todo.id, { title: el.value });
isEditing = false;
}
}/>
<li
class={ completed: todo.completed, editing: isEditing }>
<div.view>
<input.toggle
type="checkbox"
checked=todo.completed
aria-label="Toggle todo completed"
onChange(e) {
var completed = e.target.checked === true;
updateTodo(todo.id, {completed});
}/>
<label onDblClick() {
isEditing = true;
editingTitle = todo.title;
}>
${todo.title}
</label>
<button.destroy
onClick() { removeTodo(todo.id) }
aria-label="Delete todo"
/>
</div>
<input/title
class="edit"
title="Enter the new todo title"
type="text"
value=editingTitle
onBlur=saveEdit
onChange=saveEdit
onKeydown(e) {
if (e.keyCode === 13 /* ENTER */) {
saveEdit();
} else if (e.keyCode === 27 /* ESC */) {
isEditing = false;
}
}/>
</li>
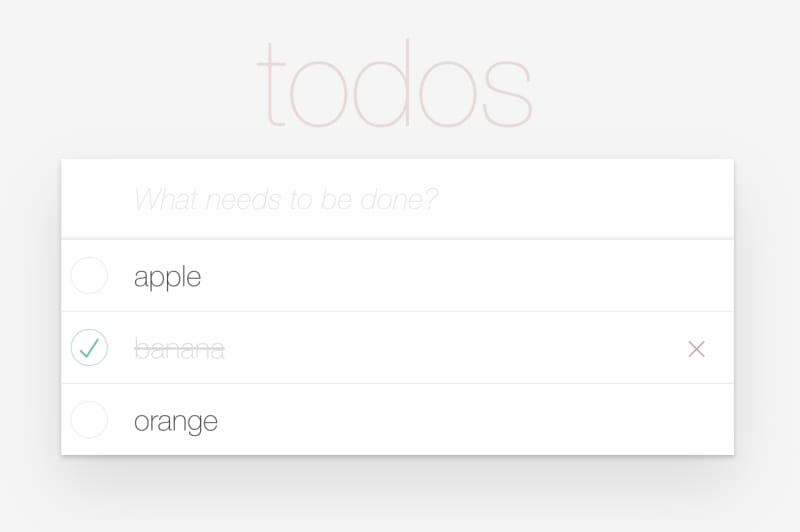
This is our biggest code snippet by far and it's because the Todos do a lot of stuff. You can check them, uncheck them, and double click to edit.
We are seeing the <const> tag for the first time here. It is useful for defining things in our template that do not get reassigned. In this case a function we use in multiple places. We also see nice usage of Marko's support of object syntax for applying classes.
If you add the necessary methods to the store and replace the contents of <for> in TodoApp.marko you should now have a basic working Todo application.
<TodoStore/{
todos,
addNewTodo,
updateTodo,
removeTodo
}/>
<section.todoapp>
<TodoHeader addNewTodo=addNewTodo />
<if=todos.length>
<section.main>
<ul.todo-list>
<for|todo| of=todos by=(todo => todo.id)>
<TodoItem todo=todo updateTodo=updateTodo removeTodo=removeTodo />
</for>
</ul>
</section>
</if>
</section>
Filtering and Other Features
We aren't quite done yet. The rest of our features are going to be focused on TodoApp.marko. First, let's add a toggle all checkbox. We need to add toggleAllTodosCompleted to our list of properties we are pulling out of <TodoStore> and then we can replace the line <section.main> tag with this.
<const/remainingCount=todos.length - todos.filter((todo) => todo.completed).length />
<section.main>
<id/toggleId />
<input.toggle-all
id=toggleId
type="checkbox"
checked=(!remainingCount)
onChange(e) {
toggleAllTodosCompleted(e.target.checked);
}>
<label for=toggleId />
We introduce another new tag here <id>. This one gives us a unique identifier that is stable across server and browser execution and a perfect way to create an id to link our input to its label. And now we can toggle on and off all our todos.
The last feature we need to add is filtering the list by whether they are completed or not. Instead of trying to explain I'm going to just post the final TodoApp.marko:
<TodoStore/{
todos,
filter,
setFilter,
addNewTodo,
updateTodo,
removeTodo,
toggleAllTodosCompleted,
clearCompleted
}/>
<section.todoapp>
<TodoHeader addNewTodo=addNewTodo />
<if=todos.length>
<const/remainingCount=todos.length - todos.filter((todo) => todo.completed).length />
<const/filteredTodos = todos.filter(todo => {
if (filter === "active") return !todo.completed;
if (filter === "completed") return todo.completed;
return true;
})/>
<const/handleFilter=((filter) => (e) => {
setFilter(filter);
e.preventDefault();
})/>
<section.main>
<id/toggleId />
<input.toggle-all
id=toggleId
type="checkbox"
checked=(!remainingCount)
onChange(e) {
toggleAllTodosCompleted(e.target.checked);
}>
<label for=toggleId />
<ul.todo-list>
<for|todo| of=filteredTodos by=(todo => todo.id)>
<TodoItem todo=todo updateTodo=updateTodo removeTodo=removeTodo />
</for>
</ul>
</section>
<footer.footer>
<span.todo-count>
<strong>${remainingCount}</strong> ${remainingCount > 1 ? "items" : "item"} left
</span>
<ul.filters>
<li>
<a
href="#/"
class={ selected: filter === "all" }
onClick=handleFilter("all")>
All
</a>
</li>
<li>
<a
href="#/active"
class={ selected: filter === "active" }
onClick=handleFilter("active")>
Active
</a>
</li>
<li>
<a
href="#/completed"
class={ selected: filter === "completed" }
onClick=handleFilter("completed")>
Completed
</a>
</li>
</ul>
<if=(remainingCount !== todos.length)>
<button.clear-completed onClick=clearCompleted >
Clear completed
</button>
</if>
</footer>
</if>
</section>
<style>
@import url("https://unpkg.com/todomvc-app-css@2.2.0/index.css");
</style>
No new functionality. Just builds on what we have been doing this whole time.
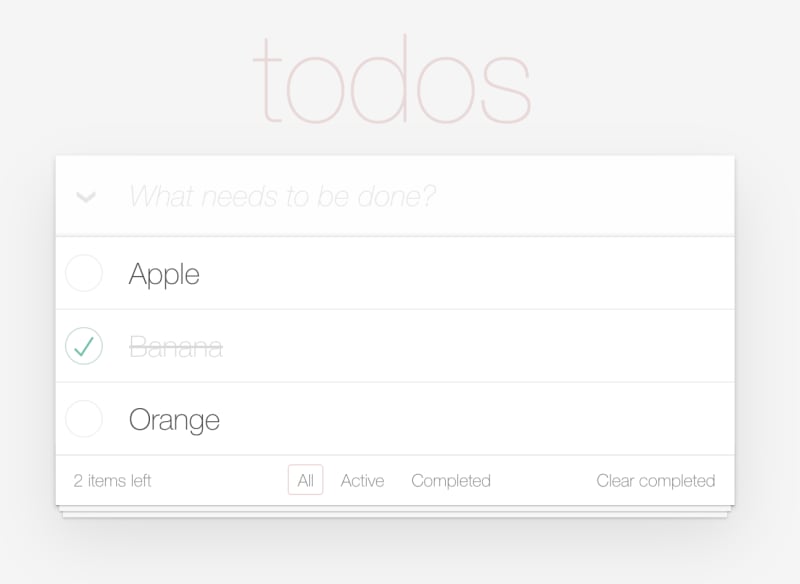
Conclusion
And that is it. We have our TodoMVC app with Marko. There are a few more things we can do. Like add persistence to local storage or database but I will leave that as an exercise for the reader. You can see the repo with our project here.
Hopefully, through this tutorial, you gained an appreciation for how Marko and the new Tags API allows us to easily make stateful templates with some simple extensions over HTML to produce isomorphic apps.
That's right. The app we just made is fully server-rendered and dynamic in the browser. It doesn't get much easier than that.





Top comments (7)
My first impression was that we have moved from "what is that markup doing in my code?" to "why is my code scattered over all these tags?" Then I scrambled back to Introducing the Marko Tags API Preview to get a better sense of this effort's vision. Once I got a twinkle of an insight my first compulsion was to introduce this refactoring:
This brings me to my concern which is expressed in UI as an Afterthought (and by extension Architecture the Lost Years ):
Or put differently: Why is my core client-side application logic complected with the UI (framework)?
Now obviously the
lets andreturnare necessary for the reactive system to track connections and dependencies — however the role of templates is to express structure via containment (and substitution), not interfaces for internal application communication and collaboration. On a different level while the UI depends on parts of application state, managing application state isn't its responsibility. So while the UI needs access to application state and perhaps even manage it's own, minor derived state it shouldn't be in the business of actually managing application state.To elaborate on my perspective:
Conflation vs Separation
I'm familiar with Plank's Principle — especially the last part:
The whole "innovation progresses one funeral at a time" perspective is often used to dismiss established insights justifying "out with the old, in with the new" failing to account for the fact that so called "innovations" have to stand the test of time to retain that title.
I believe one could make a convincing case that the introduction of JSX wasn't an "innovation" but in fact a regression. Even the Vue documentation perpetuates the faulty assumption that its premise is based on:
It never was about the separation of file types. Typically at this point I go into the how the separation relates to the web's approach to fault tolerance and resilience - however in this context it's not relevant as the compiler can be used to ensure the necessary post-compile separation.
The Vue documentation goes then further to claim:
It's this type of argument that managed to get object-orientation programming into the mainstream - but over that past decade or so the cracks in that argument have become more and more noticeable. The argument has an undeniable allure which often enough fuels the popularity of the approach which in turn is then fielded as evidence of the original argument's validity.
Apart from failing to correctly identify the original motives behind the "separation of file types" it also doesn't address additional motivations in favour of maintaining separation deemed beneficial by practitioners:
Ultimately this was popularized as Unobstrusive JavaScript. In retrospect that moniker was unfortunate because it made it all too simple to dismiss it as irrelevant in the age of CSR frameworks which operate entirely in JavaScript. But that unjustifiably dismisses the core tenet and the benefits of:
Separation of behaviour and structure
One may also be tempted to defend the likes of Vue and Svelte because internally (single file) components do have "separation of behaviour and structure" because markup and behaviour exist in separate sections - but ultimately that separation is meaningless as all of that simply compiles to pure conflated client-side JavaScript rather than generating server-side code capable of emitting fully formed markup that can smoothly rendezvous client-side with the JavaScript necessary for interactivity.
In terms of metaphor's one can look towards printing and graphical design. Their artefacts are often authored and produced in layers - often necessitating the use of registration marks to ensure correct alignment during production.
Similarly structure and behaviour are separate layers that have to be "in alignment".
It is easier, at least in the small, to conflate structure and behaviour because there are no "registration marks" to keep track of - however the component approach makes one fundamental assumption - that structural and behavioural boundaries coincide.
The simple approach keeps things separate and boundaries may or may not coincide - it just doesn't matter.
One blatant example of "boundary ambiguity" is a list;
<ul>/<ol>vs<li>. List elements and list item elements are separate tags but are tightly coupled given that:That coupling could indicate that both
<ul>and<li>should be both managed by the "List component" and that there is no need for an "Item Component" as that responsibility is covered by the "List Component".At the same time there could be an argument that there can be behavioural aspects of a list item component that are more related to it being an "item" rather than being part of (and being positioned within) a list - at which point part of the
<li>behaviour resides with the "List Component" while the remainder resides with a "List Item Component". Consequently the "behavioural boundary" doesn't occur cleanly between the "List Element" and<li>but right on top of the<li>element (unless one moves the "item" role to the child element which doesn't necessarily make semantic sense).Inline event handlers to EventTarget.addEventListener() was an early move towards better separation of behaviour and structure.
One issue here from the structural (HTML) perspective is that there is no indication when and where added behaviour can be expected. This is exacerbated by the fact that there are no clear "registration marks" for any behaviour as the implementation could target a specific element through the rather broad means of any type of selector, e.g. by
ID,Classor any other prominent feature in the overall document structure.Contrast this with the clear separation of data and structure in a template, for example, in Nunjucks:
In their own way the double braces and variable names act as registration marks between the structural layer (template) and the data layer (context object).
Supporting a looping construct makes sense for supporting structural repetition; similarly conditional structures; perhaps even parametric structures;
That doesn't mean that Nunjucks (or Jinja) is some kind of gold standard. It (and many other templating languages) offers filters. In the context of their domain this makes sense as there is no behavioural layer.
Templates are primarily crafted to transform data structured for information processing to data structured for display. In the absence of a dedicated behavioural layer it is an accepted trade-off to conflate (some minor) data conversion within the structural template while accepting the consequence of increased complexity of the of the templating system — rather than forcing the wholesale adoption of a "to display data" transformation layer for all templates.
However introduction of any minor conflation is often just the "thin edge of the wedge" of which PHP serves as a historical example:
In many ways the same thing has happened with JSX; people liked it because it's easy even though it conflates matters; JSX elements are neither markup nor DOM elements but are simply a representation of a component instance's position in the component tree (for better or worse).
Many attempts at humour have a kernel of truth to them.
In the presence of a behavioural layer it makes sense to not support data conversion inside the structural layer (template) but instead delegate it to the behavioural layer even if this leads to the introduction of "template adaptors" which are solely responsible for the conversion of "behavioural data/types" to "structural (display) data/types" (and vice versa).
Conflation also makes tooling more complicated. Server-side markup is all about "strings". Typically optimal server-side performance is achieved by pre-compiling templates to functions that transform their inputs into markup via extremely optimized string concatenation. Similarly because HTML is text-oriented the majority of DOM properties are string based. As a result the benefits of "typing" templates should be minimal given that the majority of data handled is string based anyway. Along comes JSX introducing an "XML-like syntax to ECMAScript":
… all for the sake of replacing
or
with
… just because it's easier on the eyes?
When TypeScript gained popularity (for better or worse) JSX increased the burden of adoption that either the "enthusiasts" or the tooling ecosystem had to somehow bear (including popular IDEs — though there is an entirely separate conversation lurking there).
So when I saw
TodoStore.markothe first thought that went through my mind was:where the typical answer is more plugins, loaders, etc. The point is that this type of conflation tends to act as a deterrent to adoption as it doesn't fit into existing workflows and necessitates the creation of additional complex tooling, potentially redirecting effort that could be spent more constructively elsewhere.
Keeping things separate usually means that existing tooling can still be leveraged to maximum effect. For example, before Svelte supported Typescript OOB it was still possible to simply move any component code that Svelte didn't have to be aware of out into a standard module which could then be processed as per usual by the standard tool chain (and micro-tested) — if one was so inclined.
I'm well aware of the Priority of Constituencies:
The way I see it, preferring separation over conflation isn't a case of preferring purity over practicality but choosing simplicity over easiness. While separation in the short term may create authoring inconveniences it should on the whole lead to "parts" that are internally simpler which interact with one another in much simpler ways, reducing system complexity and requiring less complex tooling (leaving more room to invest complexity in other, higher value avenues).
In some ways the current obsession in the web industry with short term DX (and how it's perceived to improve productivity) parallels the development process indulgences prior to the agile manifesto — in particular:
i.e. the additional complexity cost of some forms of DX needs to be carefully assessed against the potential (opportunity) cost on the UX end (and in terms of long term maintainability) — I believe the myth of the "trickle-down economics" from DX to UX has been well and truly debunked. Without that kind of assessment DX efforts often are more about "press of a button, comfy chair development" rather than improving (long-term) product quality.
Admittedly the store example is probably where this is the most involved. But I wonder how far it goes beyond this in Marko apps. This is a simple form. And these sort of pieces are probably the extent of state management in most MPAs.
Still as you may have noted I'm big on aggressive co-location. Mostly looking at if we can bridge the gap between the small and the largest apps better. You've probably noticed this trend in refactoring or software scaling. But where we start on the small side is closer to where we end up on the enormous side than all the steps in between. In Marko's case I think this article better captures our goals that the release announcement for the preview, and especially look at the code example at the bottom and the refactoring story.
I like that example a lot because it mirrors the pattern that I constantly see as we scale things. Every framework would have benefitted going from version 1 directly to version 3 if we knew we were going to version 3 ultimately, but introducing boundaries prematurely is not great. Only Marko in that example seamlessly goes through the 3 versions as a natural progression rather than a bunch of rewriting and refactoring.
When we are small we have everything in a single container. It's easier to see it all in front of us. The complexity is not at a point that this is hard to manage. As we grow this structure it becomes harder and we break it apart. Our first instinct is to group by like things. Whether that is as far as separating out state management from view, or simply reorganizing our component code to make it easier to add more features. Eventually though it scales beyond our ability to scale people or process. And we need to slice things the opposite way. At 90 degrees so to speak. More often this involves undoing what we did in the first step. And funny enough it often looks like having more of the initial thing rather than the intermediate step.
Now to be fair we go through this cycle over and over again. As now each of those pieces will do the same alignment over time and eventual split. That cycle I think is what a lot of the work is looking to address.
Now in my opinion this is all about the old game of hot of potato so to speak of who is left holding the state. When we moved to the client side we brough MVC with us, which was terrible because it didn't account for local state. This is what killed Angular1 etc, and lead to the rise of React. React wasn't the first one though to understand this. The whole MVVM thing was poking the holes in MVC. And Angular and Ember were trying to add a bunch of stuff to MVC to account for the fact they were missing something so vital in their model. It was the complication they added to an architecture that didn't want it that sunk those V1 versions. People probably could have kept using the awkward pattern as the fix was worse than the problem in a sense, but we moved on.
Now what we've been seeing recently is the continuation of that. Global State management has been a source of a lot of friction for frontend development. Well it is a bit more complicated than that. It's more that pulling everything local obviously doesn't exactly work in a naive sense. More boundaries have a cost as we scale. But since frameworks control the change mechanism instead of some externalized controller we end up playing a bit of an awkward game as we try to move certain things out of the components back into something shared. And this is basically where I've felt this whole "UI as an Afterthought" started gaining steam again.
But I just see 2 extremes with misalignment. Client frameworks don't really want global state, but are somewhat doomed to be inefficient without it. And classic server side mentality doesn't want local state. They want to be stateless. So who the hell is left holding the bag. That is why GraphQL has been a big deal, and things like ReactQuery in React ecosystem. Frameworks want to treat all state as local, and backend want to treat all things as stateless, the solution it feels is not to try to force either side to do what it doesn't want to. Just to abstract out the adapter. There is complexity here but there is a surprising amount of alignment.
Now, where does business logic live is the resulting question, because I'm basically advocating for smart backends, smart UIs, and dumb stores, (instead of the proposed smart stores and dumb UIs). The answer is mostly on the backend. Instead of viewing our architectures as 2 distinct MV___ that feed into each other I think we need something else. Classic server mechanics have us go from smart(business layer) to dumb(presentation layer) as we serve out our content. Classic app mechanics have us go from dumb (database) to smart (interactive UIs). So to me this about connecting and wrapping up those dumb parts. Ironically I call them dumb but they consist of some of the hardest problems like caching.
So what does this have to do with anything? I think we need to set ourselves up be able to best slice things the other way. And the way we do that is collapse the client/server model. It's not to say the results end up being that different than UI as an Afterthought but in a world where we offload the "global" state logic outside of our whole frontend mindset leaves the frameworks and UI tools the flexibility to optimize for their usage. Where aggressive co-location is a good thing.
TodoMVC example is fundamentally at odds because our model a client side one. Whereas ideally the store would look more like your refactor except we wouldn't need the separate JS file.
Thank You for your response!
I've revisited
from 2020-Nov-23 as that seems to be the point where you got the most public feedback. Some questions:
Given that
Chartuses a native DOM reference is it safe to assume that it is purely a client-side widget?Consequently what actual HTML is sent from the server to the client? Something like:
Side note: Good thing eBay doesn't plan on adopting Tailwind CSS.
Yeah
<mount>was an early version of our<lifecycle>tag. So this is all client side. So the server HTML would be what you wrote and when hydrated in the browser the chart would be created in this example. The refactor story equally applies to nested state, but nested side effects(browser only) I felt were the most obvious for this example.I understand the motivation of facilitating local reasoning through co-location. But explicit separation makes the need to keep things where they need to be more obvious. And I'm concerned that co-location would lead to coupling that even tooling may have a hard time to pry apart.
Which is why I took your "chart container" example and applied my thinking to arrive at rendezvous (live on glitch).
Maybe you understand something differently by the term "Smart UI" - to me "Smart UI" means this:
The Smart UI “Anti-Pattern”
… That sums up the widely accepted Layered Architecture pattern for object applications. But this separation of UI, application, and domain is so often attempted and so seldom accomplished that its negation deserves a discussion in its own right.
Many software projects do take and should continue to take a much less sophisticated design approach that I call the Smart UI. But Smart UI is an alternate, mutually exclusive fork in the road, incompatible with the approach of domain-driven design. If that road is taken, most of what is in this book is not applicable. My interest is in the situations where the Smart UI does not apply, which is why I call it, with tongue in cheek, an “anti-pattern.” Discussing it here provides a useful contrast and will help clarify the circumstances that justify the more difficult path taken in the rest of the book.
❊ ❊ ❊
A project needs to deliver simple functionality, dominated by data entry and display, with few business rules. Staff is not composed of advanced object modelers.
If an unsophisticated team with a simple project decides to try a Model-Driven Design with Layered Architecture, it will face a difficult learning curve. Team members will have to master complex new technologies and stumble through the process of learning object modeling (which is challenging, even with the help of this book!). The overhead of managing infrastructure and layers makes very simple tasks take longer. Simple projects come with short time lines and modest expectations. Long before the team completes the assigned task, much less demonstrates the exciting possibilities of its approach, the project will have been canceled.
Even if the team is given more time, the team members are likely to fail to master the techniques without expert help. And in the end, if they do surmount these challenges, they will have produced a simple system. Rich capabilities were never requested.
A more experienced team would not face the same trade-offs. Seasoned developers could flatten the learning curve and compress the time needed to manage the layers. Domain-driven design pays off best for ambitious projects, and it does require strong skills. Not all projects are ambitious. Not all project teams can muster those skills.
Therefore, when circumstances warrant:
Put all the business logic into the user interface. Chop the application into small functions and implement them as separate user interfaces, embedding the business rules into them. Use a relational database as a shared repository of the data. Use the most automated UI building and visual programming tools available.
Heresy! The gospel (as advocated everywhere, including elsewhere in this book) is that domain and UI should be separate. In fact, it is difficult to apply any of the methods discussed later in this book without that separation, and so this Smart UI can be considered an “anti-pattern” in the context of domain-driven design. Yet it is a legitimate pattern in some other contexts. In truth, there are advantages to the Smart UI, and there are situations where it works best—which partially accounts for why it is so common. Considering it here helps us understand why we need to separate application from domain and, importantly, when we might not want to.
Advantages
Disadvantages
If this pattern is applied consciously, a team can avoid taking on a great deal of overhead required by other approaches. It is a common mistake to undertake a sophisticated design approach that the team isn’t committed to carrying all the way through. Another common, costly mistake is to build a complex infrastructure and use industrial strength tools for a project that doesn’t need them.
Most flexible languages (such as Java) are overkill for these applications and will cost dearly. A 4GL-style tool is the way to go.
Remember, one of the consequences of this pattern is that you can’t migrate to another design approach except by replacing entire applications. Just using a general-purpose language such as Java won’t really put you in a position to later abandon the Smart UI, so if you’ve chosen that path, you should choose development tools geared to it. Don’t bother hedging your bet. Just using a flexible language doesn’t create a flexible system, but it may well produce an expensive one.
By the same token, a team committed to a Model-Driven Design needs to design that way from the outset. Of course, even experienced project teams with big ambitions have to start with simple functionality and work their way up through successive iterations. But those first tentative steps will be Model-Driven with an isolated domain layer, or the project will most likely be stuck with a Smart UI.
❊ ❊ ❊
The Smart UI is discussed only to clarify why and when a pattern such as Layered Architecture is needed in order to isolate a domain layer.
There are other solutions in between Smart UI and Layered Architecture. For example, Fowler (2003) describes the Transaction Script, which separates UI from application but does not provide for an object model. The bottom line is this: If the architecture isolates the domain-related code in a way that allows a cohesive domain design loosely coupled to the rest of the system, then that architecture can probably support domain-driven design.
Other development styles have their place, but you must accept varying limits on complexity and flexibility. Failing to decouple the domain design can really be disastrous in certain settings. If you have a complex application and are committing to Model-Driven Design, bite the bullet, get the necessary experts, and avoid the Smart UI.
Evans, Eric. "Domain Driven Design: Tackling Complexity in the Heart of Software"; Four: Isolating the Domain, pp.76-79, 2003.
Perhaps now you understand my apprehension with "Smart UIs" — the implication here is that the approach does not scale.
The thing is I think with rendezvous having the bare Solid reactive system wrap the core application and binding it directly into the DOM on mount would be useful.
FYI: Congratulations on having Rich Harris to mention Marko in his Transitional Apps talk!
(Then again you're always talking about Svelte so it's only fair.)
Thanks for this helpful step-by-step code with familiar TodoMVC example. This makes it much easier for me to get familiar and play around with Marko new tags API 👍 I was surprised that you can't mix it with the old
<if()>, or maybe I did something wrong with my code 😅Anyhow, I have some questions.
On the example, you use Marko component for the TodoStore. Is it possible to replace
TodoStore.markowith just JS? Not sure if you implement the store as a Marko component just for an example, or it's a must in order to make it work.Another thing, how can we lint JS code inside Marko template, do we have eslint plugin for Marko? My impression with Marko Tags API that it seems we are putting more and more JS code inside the template. Without linting tool, it would be harder to know if there's syntax error on the code. It seems Marko compiler can catch some but maybe you know better tool to handle this problem.
Thanks!
Yeah mostly that since we are streamlining composability we are replacing the
()(default arguments) with=(default attribute). In this way we can extend this capability out to custom tags you might author. Default attribute has some benefits in that it only accepts a single argument.So
<if(condition)>is now<if=condition>. How we handle backwards compatibility is still open but we wanted the preview to only contain future facing syntax to get a feeling for what the intended experience.As for the store, you could do it with just JavaScript to a point. The unit of change, the equivalent to React's
useStateor Vue'srefor Svelte'sletis Marko's<let>tag. So you could set and update that with JS from the outside but it wouldn't be granular. In the same way you need to update their core primitives you need to do so with Marko. So using the primitives in file makes it easier to make it more performant.It's a bit of a departure but we have primitives for Context API, etc for more advanced patterns, and more interestingly is tags let you colocate in the markup. Nest data exactly where you need to use it without additional imports etc. Not saying you would but when Marko 6 comes along you could make a whole app in a single template with no performance degradation. Components no longer are a limiting factor.
In some ways it's like the diagram when React Hooks came out that showed how we reduced the interweaving of logic compared to class Components. This takes it even further. Basically single cut and paste refactoring. Almost like dealing with plain HTML.
That being said it only raises the bar on tooling in templates. And on this we agree. Work in the last year from Vue and Svelte have given us a pretty clear trajectory in getting TypeScript, Prettier, and ESLint support. Things that these custom DSLs have always struggled a bit with. So this is definitely something being worked on. But as you can imagine with something so big coming around the corner it didn't make the most sense to develop that out with these changes coming down the pipeline.