![Cover image for Introduction to Hive for dummies [Module1.3]](https://media.dev.to/cdn-cgi/image/width=1000,height=420,fit=cover,gravity=auto,format=auto/https%3A%2F%2Fdev-to-uploads.s3.amazonaws.com%2Fi%2Fstsrvi2aau6ab6q8mprw.png)
Why is HiveQL preferred over SQL for BigData? What is Hive? Is it just a simple DBMS like language? Let’s find out in this Module.
Hey Pals! Welcome to Module 1.3 Introduction to Hive. If you are new here, check out Module 1.1 for Introduction of BigData.
In this module, we will be discussing the basic theory of why Hive is part of the Hadoop ecosystem and termed a BigData Technology.

First things first
What is Hive and why is it used?
Hive is a data warehouse infrastructure tool to process structured data in Hadoop. It resides on top of Hadoop to summarize Big Data and makes querying and analysing easy. As already discussed in my previous module, Hive uses SQL like a query language called HiveQL to perform ad-hoc queries and query analysis. However, it is not a relational database.
A little history about Apache Hive will help you understand why it came into existence.
When Facebook started gathering data and ingesting it into Hadoop, the data was coming in at the rate of tens of GBs per day back in 2006. Then, in 2007, it grew to 1TB/day and within a few years increased to around 15TBs/day. Initially, Python scripts were written to ingest the data in Oracle databases, but with the increasing data rate and also the diversity in the sources/types of incoming data, this was becoming difficult. The Oracle instances were getting filled pretty fast and it was time to develop a new kind of system that handled large amounts of data. It was Facebook that first built Hive, so that most people who had SQL skills could use the new system with minimal changes, compared to what was required with other RDBMS
Data warehouse refers to a system used for collecting data from a heterogeneous system but provides a unified view. The data is then cleaned, transformed and analyzed in order to discover useful information. It’s a huge topic on its own, let me know in comments if you’d like me to create a blog on that subject.
Hive holds the advantage of high-speed querying whilst dealing with large datasets distributed across multiple nodes. It provides a structure to the data that is already stored in the database.
What is the Architecture of Hive?
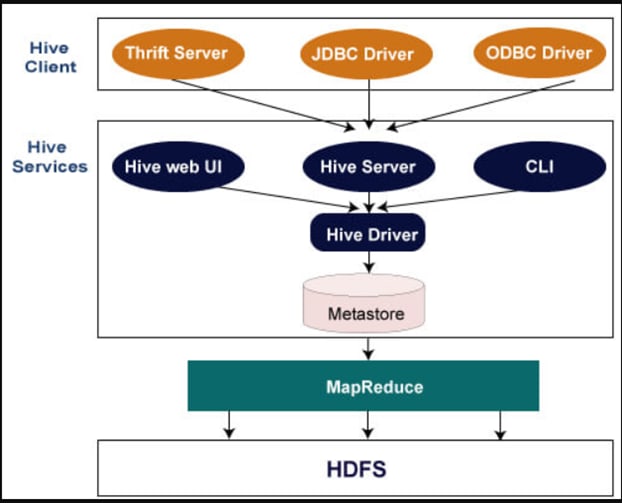
Hive supports applications written in any language for performing queries on Hive. Hive queries are submitted to a HiveServer2 process that typically runs on a master node in the cluster. Then the hive query is primarily converted to a MapReduce job. HiveServer2 enables multiple clients to submit requests to Hive.
What is HiveServer2?
HiveServer2 (HS2) is a service that enables clients to execute queries against Hive. HiveServer2 is the successor to HiveServer1 which has been deprecated since Hive 1.0.0. HS2 supports multi-client concurrency and authentication. It is designed to provide better support for open API clients like JDBC and ODBC.
What is a Thrift Server?
Apache Thrift is basically a set of protocols which define how connections are made between clients and servers. Apache Hive uses Thrift to allow remote users to make a connection with HiveServer2 also can be known as Thrift Server to connect to it and submit queries.
What is ODBC?
The Hive ODBC Driver is a software library that implements the Open Database Connectivity (ODBC) API standard for the Hive database management system, enabling ODBC compliant applications to interact seamlessly (ideally) with Hive through a standard interface. There is no ODBC driver available for HiveServer2 as part of Apache Hive. There are third-party ODBC drivers available from different vendors, and most of them seem to be free.
What is JDBC?
JDBC (Java Database Connectivity) is the Java API that manages connecting to a database, issuing queries and commands, and handling result set obtained from the database.

JDBC was initially conceived as a client-side API, enabling a Java client to interact with a data source. That changed with JDCB 2.0, which included an optional package supporting server-side JDBC connections.
HiveServer2 has a JDBC driver. It supports both embedded and remote access to HiveServer2. Remote HiveServer2 mode is recommended for production use, as it is more secure and doesn’t require direct HDFS/metastore access to be granted for users.
There is a unique JDBC URL that helps us make this connection between our application and the Hive metastore.
jdbc:hive2://<host1>:<port1>,<host2>:<port2>/dbName;initFile=<file>;sess_var_list?hive_conf_list#hive_var_list
We will get into depth about JDBC API Client in a later Module.
Now let’s see what a Hive Driver is?
Basically, for receiving the queries and submitting it to Thrift, JDBC, ODBC, CLI, Web UI interface by a Hive client, hive driver is responsible and it is a part of Hive Services core component. Moreover, to break down the Hive query language statements, it includes the compiler, executor as well as optimizer.
Jeez, so many terms. What is Metastore?
Metastore is the central repository of Apache Hive metadata. It stores metadata for Hive tables (like their schema and location) and partitions in a relational database. It provides client access to this information by using the metastore service API.
Compiler?
As any programming compiler, Hive Compiler parses the query given to the process, checks syntax and query plan (Requirements of the query), then, it sends Metadata a request to Metastore (Database) and once it receives this Metadata, the compiler checks the requirement and resends the plan to the Hive Driver. And with that, our compiler has completed its task.
Optimizer?
It performs various transformation functions and also determines the aptest join type to be used for a particular job. It also splits tasks to improve efficiency and scalability.
Executor?
The executor executes the execution plan formed by the compiler after the steps of compilation and optimization.

But wait, what is all this? How does it all work?
Right, Sorry for all the technicality. Let’s get into simple details in a way that we can understand.
So, Hive is an SQL like technology. Now, the queries we send onto Hive look similar to any SQL query
Let’s take an example of the following table called TEST that is stored in a database called TESTDATABASE:
Now, if I run a query
SELECT * FROM TESTDATABASE.TEST;
I should get the data from the table printed.
So, let’s now take a look at how Hive handles this query within itself to understand the true working of Hive.
- Execution of Query: Command-Line or Web UI sends the query to Driver (any Hive interface such as database driver such as JDBC, ODBC, etc.) to execute.
- Getting a Query Plan: The driver takes the help of query compiler that parses the query to check the syntax and query plan or the requirement of the query.
- Retrieving Metadata: The compiler sends metadata request to Metastore (any database). Metastore sends metadata as a response to the compiler.
- Send Plan: The compiler checks the requirement and resends the plan to the driver. Up to here, the parsing and compiling of a query are complete.
- Execute Plan: The driver sends the execute plan to the execution engine.
- Execute Job: Internally, the process of execution job is a MapReduce job Metadata Ops Meanwhile, in execution, the execution engine can execute metadata operations with Metastore.
- Fetch Result: The execution engine receives the results from DataNodes.
- Send Results: The execution engine sends those resultant values to the driver. The driver sends the results to Hive Interfaces and we get our result.
There are different types of Hive Table
Managed Table
Also referred to as the internal table, a managed table is the default table, meaning there is no need to specify any keyword while creating this table. It gets stored in a specific location in HDFS, which is mostly, “/usr/hive/warehouse” (unless configured otherwise). If a managed table is dropped then the underlying data of the table in HDFS also gets deleted.
It is termed Internal Table as it is stored in the “hive/warehouse” location.
External Table
An external table is generally created when the data stored in the table needs to be used or accessed outside Hive. An external table is created by specifying the keyword “External” to create table query. Whenever an external table is dropped, only the schema of the table gets deleted while the underlying data, i.e., the HDFS folder remains.
What are Hive Partitions?
Using “PARTITIONED BY” clause the columns of Hive table can be divided into specific partitions. Partitioning is a way of dividing a table into smaller parts based on the corresponding values of specified columns. A new folder is created in HDFS inside the table’s folder for every partition created.
So, let's say we have the following table
Here, we can partition this table according to any of the given columns ID, Name, Roll or Subject
Let’s say we partition this table by the column Subject. If so, we will get 2 partitions created, as there are only 2 unique values in that particular column.
English
Maths
English Partition will have 2 rows stored in it, Rahul and Jason
Maths Partition will have 1 row stored in it.
Now, I get it. Why partition? This seems like a simple GROUP BY clause. True. But, group by works in SELECT clause, and it does not alter the schema of the table in any manner. However, a partition literally divides the table at the metastore or wherever the table is located. Too confused?
Let’s take the above table for example.
Let’s say this table was stored at /usr/hive/warehouse/table1
After partitioning, the table will split into the number of partitions that got created, in this case, 2.
So, the underlying data of the table will split according to this, like
/usr/hive/warehouse/table1/Subject=English/
/usr/hive/warehouse/table1/Subject=Maths/
(Note that Subject=Maths and Subject=English are folders here, not files.)
Cool so far?

Great!
But why do we partition? What’s the purpose?
Well, Partitioning increases the speed and efficiency of query performance when someone wants to query on the partitioned columns as Hive now has to deal with a relatively smaller set of data.
Now, there are two types of partitioning in Hive: Static Partitioning and Dynamic Partitioning. Usually, static partitioning is preferred as it saves some time while loading data into the partitioned table. You explicitly create partitions in the table while creating the table in static partitioning. But in dynamic partitioning, data gets loaded in the partitioned destination table from a non-partitioned source table.
Don’t get confused, we’ll take a much deeper look once we get our hands on Hive Modules.
Have you heard of Hive Buckets?
Sometimes, even after partitioning the data to perform a query on is still huge, in that case Hive bucketing method is used. Using Hive buckets, partitions are further divided into more manageable parts.
The cool thing is, Buckets can be created on a non-partitioned table also.
Hive buckets are created using the CLUSTERED BY clause. unlike partitioning, the bucketed parts will be created as files. Bucketing helps in performing queries on the smaller size of data which can be helpful while debugging.
Sorting in hive
Hive table is sorted using four clauses:
ORDER BY
Its use case is the same as in SQL. In Hive, ORDER BY guarantees total ordering of data, but for that, it has to be passed on to a single reducer, which is normally performance-intensive and therefore in strict mode, Hive makes it compulsory to use LIMIT with ORDER BY so that reducer doesn’t get overburdened
SORT BY
This clause sorts data on a per-reducer basis which means the data in each reducer is sorted independent of the data present in other reducers. Sort by does not provide total ordering. The sort order will be dependent on the column types. If the column is of numeric type, then the sort order is also in numeric order. If the column is of string type, then the sort order will be lexicographical order.
DISTRIBUTE BY
Hive uses the columns in Distribute By to distribute the rows among reducers, All rows with the same Distribute By columns will go to the same reducer. It ensures each of N reducers gets non-overlapping ranges of the column, but doesn’t sort the output of each reducer. You end up with N or more unsorted files with non-overlapping ranges.
CLUSTER BY
Cluster By is a short-cut for both Distribute By and Sort By. “CLUSTER BY X” ensures each of N reducers gets non-overlapping ranges, then sorts by those ranges at the reducers.
SerDe
SerDe refers to Serializer and Deserializer. It helps Hive to read data from a table and write it back to HDFS in any custom format. There are built-in SerDes and anyone can create their own SerDes as well.
However, these are some built-in SerDes
- Avro (Hive 0.9.1 and later)
- ORC (Hive 0.11 and later)
- RegEx
- Thrift
- Parquet (Hive 0.13 and later)
- CSV (Hive 0.14 and later)
- JsonSerDe (Hive 0.12 and later in hcatalog-core)
Beeline
It is a newly launched product of Hive and is used as an alternate way for submitting Hive queries. As Hive CLI is not compatible with HiveServer2 but only with its predecessor, HiveServer1, beeline was introduced.
Alright alright alright, Are you guys ready for a minor assessment?

And with that, I conclude this module, this is a basic introduction of Hive, we’ll take a much more in-depth look at this when we get to Module 3.x series, where we will be completely dealing with Hive and its functionalities with help of Hadoop.
Hope you guys haven’t gotten bored, I understand the theory is a little draggy, I personally like to get my hands dirty with the code and that’s how I learn, but, it’s crucial to understand the limitations and performance capabilities of these technologies in order to make the most out of them.
Oh and as always,
Ciao!
References:





Top comments (0)