
Web apps that contain tables, charts, and graphs often include an option to export the data as a PDF. Have you ever wondered, as a user, what's going on under the hood when you click that button?
And as a developer, how do you get the PDF output to look professional? Most free PDF exporters online essentially just convert the HTML content into a PDF without doing any extra formatting, which can make the data hard to read. What if you could also add things like page headers and footers, page numbers, or repeating table column headers? Small touches like these can go a long way toward turning an amateur-looking document into an elegant one.
Recently, I explored several solutions for generating PDFs and built this demo app to showcase the results. All of the code is also available here on Github. Let's get started!
Overview of Demo App
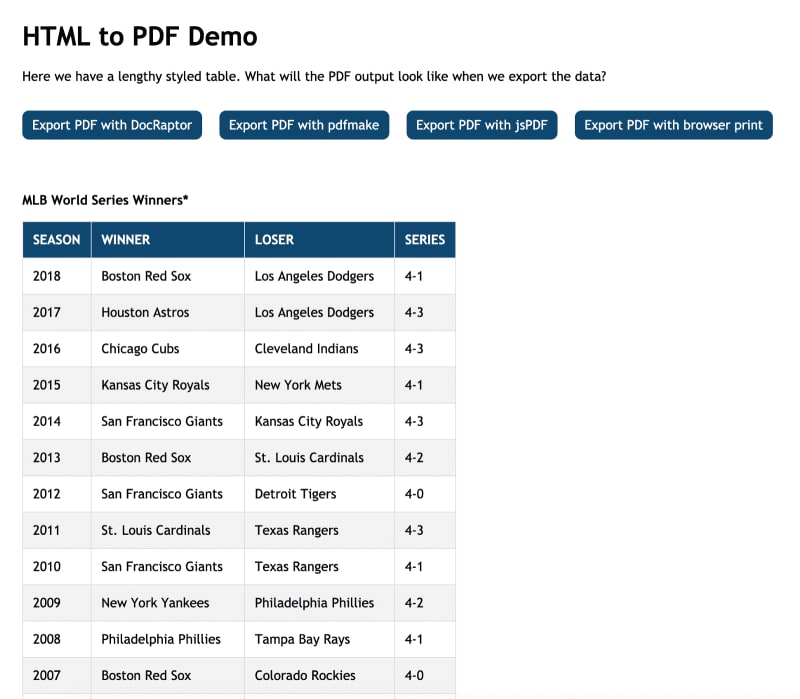
Our demo app contains a lengthy styled table and four buttons to export the table as a PDF. The app is built with basic HTML, CSS and vanilla JavaScript, but you could easily create the same output using your UI framework or library of choice.
Each export button generates the PDF using a different approach. Viewing from right to left, the first uses the native browser print functionality. The second uses an open-source library called jsPDF. The third uses another open-source library called pdfmake. And finally, the fourth uses a paid service called DocRaptor.
Let's dig into each solution one by one.
Native Browser Print Functionality
First off, let's consider exporting the PDF using the browser's built-in tools. When viewing any web page, you can easily print the page by right-clicking anywhere and then choosing the Print option from the menu. This opens a dialog for you to choose your print settings. But, you don't actually have to print the document. The dialog also gives you the option to save the document as a PDF, which is what we'll do. In JavaScript, the window object exposes a print method, so we can write a simple JavaScript function and attach it to one of our buttons like this:
Here's the output from Google's Chrome browser:

I was pleasantly surprised by the output here. Though it isn't flashy – the content is just in black and white – the main table styles were kept intact. What's more, each of the seven pages includes the table column headers and footer, which I assume the browser intelligently picks up due to my choice of semantic HTML in building a properly structured table.
However, I don't love the extra page metadata that the browser includes in the PDF. Near the top, we see the date and HTML page title. At the bottom of the page we have the website from which this was printed as well as the page number.
If my only goal in saving this document is to see the data, then Chrome does a pretty good job. But, the extra lines of text at the top and bottom of the document, while useful, don't make it look very professional.
The other thing to note is that the browser's native print functionality is different from browser to browser. What if we printed this same document using the Safari browser?
Here's the output:

You'll notice that the table looks roughly the same, and so does the page header and footer content. However, the table column headers and table footer are not repeated! This is somewhat unhelpful since you'd need to refer back to the first page any time you forgot what data any given column contains. The bottom of the table on the first page is also a little cut off, as the browser tries to squeeze in as much content as it can before creating the next page.
So it seems that the browser output isn't ideal and can vary depending on what browser the user has chosen.
jsPDF
Let's next consider an open-source library called jsPDF. This library has been around for at least five years and is consistently downloaded over 200,000 times from NPM each week. It's safe to say that this is a popular and battle-proven library.
jsPDF is also fairly easy to use. You create a new instance of the jsPDF class, give it a reference to the HTML content you want to export, and then provide any other additional settings like page margin size or the document title.
Underneath the hood, jsPDF uses a library called html2canvas. As the name implies, html2canvas takes HTML content and turns it into an image stored on an HTML <canvas> element. jsPDF then takes that canvas content and saves it.
Let's take a look at the output we get using jsPDF:

At first glance, this looks pretty good! The PDF includes our nice blue headers and striped table row background. It doesn't contain any of the extra page metadata that the browser print method included.
However, notice what happens between page one and two. The table extends all the way down to the bottom of the first page and then just picks right back up at the top of the second page. There is no extra margin applied, and the table text content has the potential to be cut in half, which is actually what happens between pages six and seven.
The PDF also doesn't include the repeating table column headers or table footer, which was the same problem we saw in Safari's print functionality.
While jsPDF is a powerful library, it seems like this tool may work best when the exported content can fit on just one page.
pdfmake
Let's take a look at our second open-source library, pdfmake. With over 300,000 weekly downloads from NPM and a seven-year lifespan, this library is even more popular and more senior than jsPDF.
While building the export functionality for my demo app, the configuration for pdfmake was considerably harder than it was for jsPDF. The reason for this is that pdfmake constructs the PDF document from scratch using data you provide it rather than converting existing HTML content on the page into a PDF. That means that rather than providing pdfmake with a reference to my HTML table, I had to provide it data for the header, footer, content, and layout of my PDF table. This led to a lot of duplication in my code; I first wrote the table in my HTML and then re-built the table for the PDF export with pdfmake.
The code looks like this:
Before we dismiss pdfmake entirely, let's take a look at the output:

Not too shabby! We get to include styles for our table, so we can still reproduce the blue column headers and striped table row backgrounds. We also get the repeating table column headers to make it easy to keep track of what data we're seeing in each column on each page.
pdfmake also allowed me to include a page header and page footer, so it's easy to add page numbers. You'll notice though that the table content between page one and page two still isn't separated perfectly. The page break partially splits the row for 2002 between the pages.
Overall, it seems like pdfmake's greatest strength is in constructing PDFs from scratch. If, for example, you wanted to generate an invoice based on some order data, and you don't actually show the invoice on the screen inside of your web app, then pdfmake would be a great choice.
DocRaptor
The last option we'll consider is DocRaptor. DocRaptor differs from the first three options we explored in that it is a paid service. It uses the Prince HTML-to-PDF engine underneath the hood to generate its PDF exports. This service is also used via an API, so your code is hitting an external API endpoint which then returns the PDF document.
The basic DocRaptor configuration is fairly simple. You provide it the name of your document, the type of document you want to create ('pdf' in our case), and the HTML content to use. There are hundreds of other options for various configurations depending on what you need, but the basic configuration is an excellent starting point.
Here's what I used:
Let's take a look at the PDF export generated by DocRaptor:

Now there's a good-looking document! We get to keep our nice table styles. The table column headers and table footer are repeated on every page. The table rows don't get cut off, and there is an appropriately sized margin on all sides of the page. The page header is repeated on every page as well, and so are the page numbers at the bottom of each page.
To create the header and footer text, DocRaptor recommends you use some CSS with the @page selector, like this:
When it comes to the PDF output, DocRaptor is the clear winner.
(As an added bonus, check out what a full-bleed styled HTML header can look like!)
Conclusion
So, which option do you choose for your app? If you want the simplest solution and don't need a professional-looking document, the native browser print functionality should be just fine. If you need more control over the PDF output, then you'll want to use a library.
jsPDF shines when it comes to single-page content generated based on HTML shown in the UI. pdfmake works best when generating PDF content from data rather than from HTML. DocRaptor is the most powerful of them all with its simple API and its beautiful PDF output. But again, unlike the others, it is a paid service. However, if your business depends on elegant, professional document generation, DocRaptor is well worth the cost.





Top comments (5)
You should also check out pagedjs.org/ and maybe weasyprint.org/. There are lots of rendering tools that have the complete CSS Paged Media Draft implemented.
Some of them you could try out on my website printcss.live/.
The interactive playground you have on your PrintCSS site is really neat! Thanks for sharing and for your work on this.
I think it would be added value if you also tested whether the text is still selectable in the PDF (probably not the case with jsPDF), whether table styling can be controlled with print media styles and whether the document padding and margin can be changed with pages media css styles.
Thanks for sharing
You are right. I have been looking to see what’s under the hood, so thank you! Do you know if any of these can be used at build time for static sites like Jekyll?