
The blog focuses on 3 things,
- Prevention from data redundancy.
- Good design choices.
- Bad design choices.
Prerequisites: Basic knowledge of databases and practices like indexing, normalization, etc.
1. Unique partial index to avoid data duplication
While indexes are generally used to improve database performance, they can also be used to avoid redundancy in data. You can add unique constraints on your columns in DDL, but for conditional unique constraints you will have to define a unique partial index.
Consider an example of a shopping-cart application, where along with orders you would also like to uniquely identify every checkout.
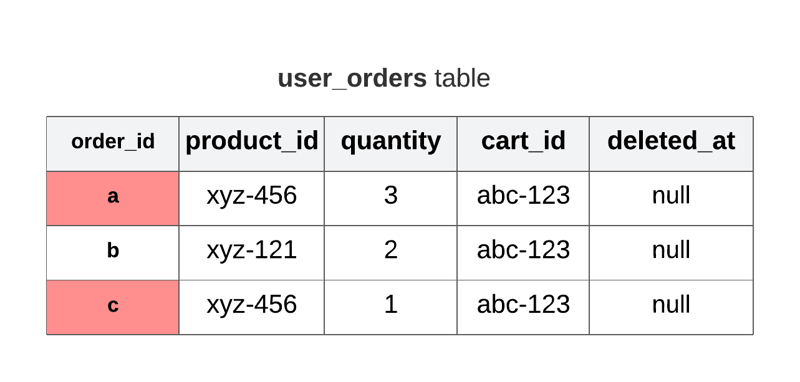
In the above example, under cart_id abc-123, the product_id xyz-456 has a duplicate entry. Such cases can be detected by adding a unique index.
create unique index unique_product_cart on user_orders (product_id, cart_id) where deleted_at is null
2. Soft delete cascades
Keeping soft deleted data in your database is awesome but it makes ensuring data quality difficult. Every time you add a constraint, you'll have to take care of deleted_at column (the first point is a good example).
Managing soft deletes has to be done at application level since in SQL databases cascading on update only happens for foreign keys. If you are lucky, your ORM might support soft delete cascades, otherwise you'll have to implement it by using model observers or extending your ORM's query builder for instance. They can be implemented using triggers too.
3. Transactions at application level
A single operation at application level might be a combination of multiple writes at database level. While you might enforce all kinds of constrains on database, your data will get ruined if you don't implement transactions at application level.
Consider an example of a movie ticket booking application, when you reserve a seat for a movie, it can be a combination of multiple operations at database level, eg: add rows in seat_reservation table, user_activity and snacks_orders table. All of the operations would usually come under a function reserveTicket(). Such a function has to be put under a transaction in application code.
4. Keep historic changes and quick lookup columns.
Sometimes saving historic data in a separate table becomes important. For example consider a credit card company, when you apply for a credit card it goes through multiple intermediate stages before getting approved.

In above example, the applications table keeps track of users' applications while the application_status table keeps track of status of each application.
The reason for keeping historic changes is to keep track of who changed the status (creator_id) and why was the status changed (comments).
Notice that the applications table also has a latest_status_id for quick lookup to latest status, it's a good practice to have such columns.
Although credit card companies don't work this way, but I hope you get my point 🙃.
5. Save last data point in a JSON meta column
Sometimes, you might not need to track how data for some row has changed historically but just keep the last data point for rolling back. Consider the same example in point 4, this time we save the status in the same table but we also save the old status in a JSON column
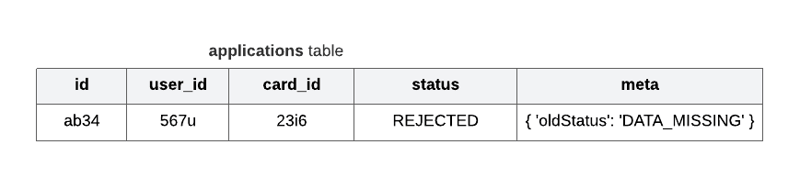
This example doesn't do justice to how useful it is to save old critical data points in JSON meta column 😶, when used in correct place, it has the potential to save you a lot of time while doing data analysis or data rollback.
6. Log data changes
While schema changes are tracked by migration files, it's important to keep track of all data changes in the database, usually this would be implemented using a polymorphic table, which would keep track of changes to all models.
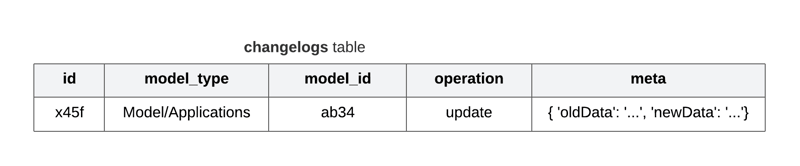
How to do it ?
- Aspect Oriented Programming (you are lucky if your framework has good support for it)
- Database Triggers
- Overriding your query builder's CRUD methods/events or using external libraries that do that.
It's also important to regularly cleanup these logs and store them somewhere else as the table gets heavy quickly.
7. Use Polymorphic tables
The table used in point 6 is a polymorphic table, the column model_id is a foreign_key that points to any table in the database.
Let's take another example of an online forum, the forum can have comment sections at multiple places and from multiple sources, i.e comments from users, admins, automated comments from system, etc. Instead of storing comments in multiple tables we can have a polymorphic table for storing comments.
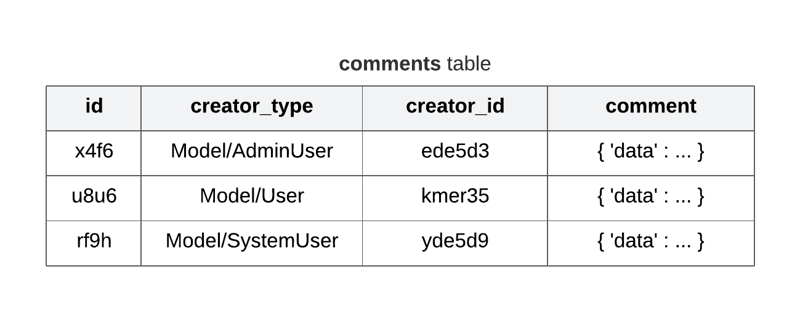
8. Avoid saving UUIDs as string
While keeping UUIDs as primary keys is a good choice. Saving them as binaries is much better than saving them as strings.
UUIDs consists of 32 hexadecimal digits with 4 hyphens. If saved as a string it can take upto 36 bytes (288 bits). Most SQL databases support saving them as binaries i.e 128 bits. Index size of binary UUIDs is less than half the index size of index size of string UUIDs.
9. Avoid un-necessary indexes
Indexes are cool but it's important to keep in mind that indexes occupy memory and need to be updated in every write operation (in Postgres). Too many indexes means too many indexes to be updated for every insert/delete operation, this will basically slow down your database writes.
10. Use views when possible
There are multiple cases where views are a good choice, I'll tell one of them. Consider a case where stakeholders require reports of entire data in all critical tables. For this, you would aggregate data from multiple table using joins, overall that would be a complex query. There can be multiple instances where you would want to re-use such aggregate data i.e reuse the query. In such case writing a view will be a good choice.
Creating a view is same as writing the same query at application level, it's just that in case of view you can reuse the query which is saved at database level.
There are much more things that can be good choices when it comes to designing databases and maintaining data quality. If you have things to share please do in comments.
-- sudheer121





Top comments (3)
💯
so many concepts I'm seeing for first time. nice one!
good examples especially
thanks 🙌