Data Analysis is all about extracting all possible insights from your dataset. A very important step in building a machine learning model is to get to know the data. Spark is widely used for its parallel data processing on computer clusters. Spark supports multiple programming languages (Python, Scala, R, and Java) and includes libraries for SQL(Spark SQL), machine learning(MLlib), stream processing (spark streaming), and graph analytics (GraphX). In this post, I am going to use PySpark and Spark SQL for my data analysis.
If you want to run Spark locally, you should have Java, as well as Python (Python 3), installed on your machine.
Install Spark
i. Go to https://spark.apache.org/downloads.html
ii. Select version and package type

iii. Click on the download link, it will bring you to Apache Software Foundation site. From this site, you can start downloading

iv. Set up some environment variables for Spark home and PySpark in a file called .bash_profile
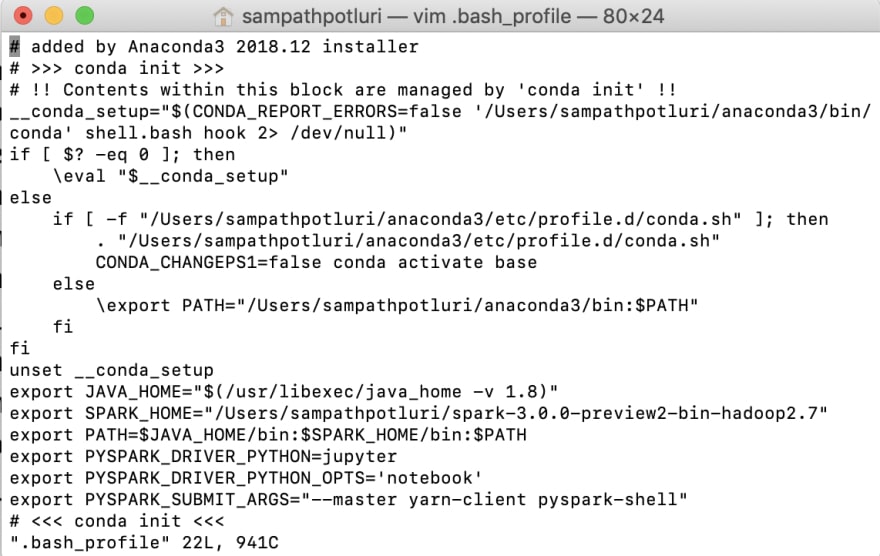
v. Install PySpark - I am using Python installer program (pip) to install PySpark

Launching Jupyter Notebook
i. Install jupyter notebook with python installer

ii. Open terminal window, navigate to your working directory and type jupyter notebook. This will launch jupyter notebook
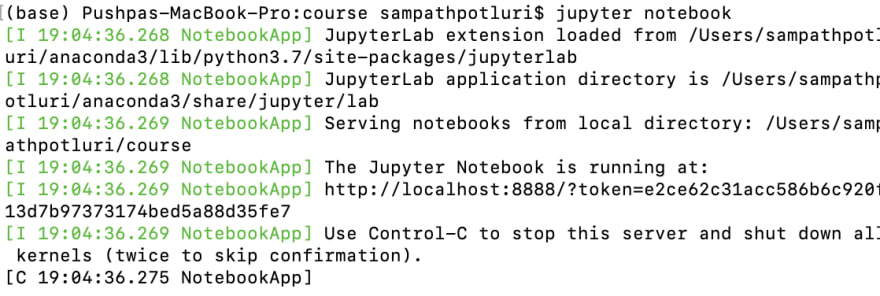

iii. Create new jupyter notebook by clicking on the "New" button on the upper right side and selecting Python 3






Top comments (0)