Ok! If you are here, you are just like me, always wondering, why complexity of algorithms, and how do I calculate one. As much as I love reading books, sometimes they make things too intricate, with mathematical notations, graphs, and formulas. Or, maybe I am just wrong, and you are here just for a refresher on the topic. Nevertheless, let's just get over this concept. This is gonna be a long post, so have some snacks to crunch or a hot tea by your side so you don't get bored. But, let me tell you this. If you manage to read through the end of this post, then complexity vanishes.
As much as I would like to avoid mathematical notation while describing the concept, I'm afraid I cannot completely skip over it. But, I'll try to make the suffering much easier (devil laugh)
Let's begin.
Why determine the complexity of Algorithms?
But, should we not rather discuss What is an algorithm? first?
An algorithm is a set of well-defined steps, which ..... (Would you for god's sake, just skip over it ?)
Ok, say you've just written a piece of code, based on your own algorithm. And, your algorithm looks something like this.
For each hour in a 24 hrs day
Run 1 piece of code every hour.
If the code compiles and executes,
Then, display "I love programming! "
If it does not compile,
Then, display "I'm leaving programming for good"
So, you have beautifully converted your algorithm into code, which looks something like this.
for i in range(24):
if code_compiles:
print("I love programming")
else:
print("I am leaving programming for good")
Now, if we look into this code, how much time do you think, it would take for us to execute this code? 2 secs, 5 secs, ?
You might argue that the code ran in 2 secs for you, while your friend says that, it ran in just 1 sec because he has the latest Dell XPS PC, powered by Intel core I9 Processor. For me, it takes almost 10 secs to execute (because my computer is old, just like me).
So, the question is How do we effectively measure the runtime and space requirement of an algorithm?, because obviously, it varies depending upon the processing speed of your computer, memory, etc, and different people have different computers with different processing capabilities.
Also, say I have a different code implementation of an algorithm, that does the same task and runs much faster on my PC but, takes forever to run in your system. How do we know which algorithm is better, your's or mine?
Well, you guessed it right? Asymptotic complexity to the rescue.
What is Asymptotic Complexity, how it is related to Big O?
First, let's restate our problem, in a simple and different way.
So, we have different computers, with different speeds and memory, and also we have different code implementations to perform a certain task. We'd like to know how much time they'll take to run, and which one's better?
Since we have very little control over who holds the fastest computer (IBM Summit? ), we can rather improvise and shift our attention to another important aspect to gauge the complexity of algorithms. i.e, the input size.
Correct! Input size, kinda sounds nice and relevant. After all, the bigger our input, the longer it takes our computer to do a certain task, and this is true for other computers as well.
This avoids our problem of comparing runtime based on computers of different processing capabilities, to determine the complexity of algorithms.
But, does it really matter, if it takes someone 5 secs to execute a code and another person 10 secs?
If you are thinking like me, and if we could donate time, I'd rather donate that extra 5 secs to my competitor, and stop reading here.
But, the interesting question is, what if the time required is hours, or maybe even days? We cannot simply donate or avoid that, can we?
No AWS, I don't wanna pay for extra compute. I'd rather take another algorithm, which runs faster. - Don't worry if you didn't get this joke
This is exactly the meaning of Asymptotic. When our input gets sufficiently larger, what behavior does the algorithm have, in terms of the runtime and maybe, space?
Time to see a diagram now.
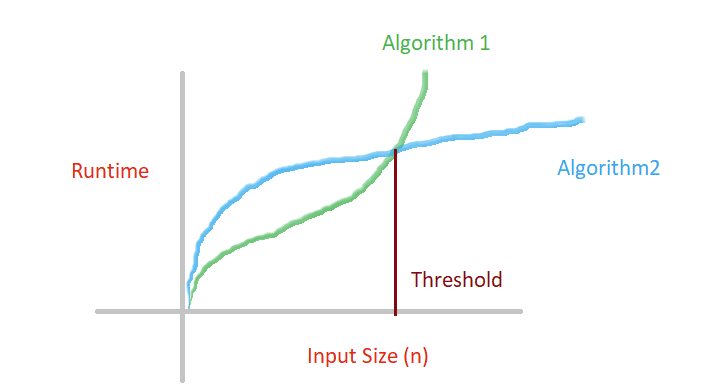
If you see the above diagram properly, you'll see that before the threshold point, Algorithm 1 is the winner in that, it takes less time to run. But, if we see beyond the threshold i.e., when our input is larger, we have a different winner Algorithm 2.
So, how do we represent these complexities? In what form ?
We do that using three different notations.
- Big O, --> Worst case Complexity
- Big Omega -- > Best case complexity
- Big Theta -- > Avergae case complexity.
Let's just be concerned with Big-O and, throw the rest of the notation in dustbin.
Why ? you ask.
Before I answer that, let's just understand what Big-O represents.
Big-O gives the upper bound on the runtime of an algorithm. Time to see the diagram again!!
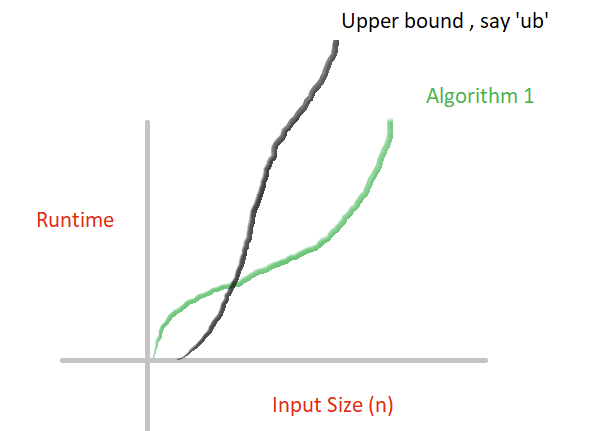
For eg., if we write the complexity of algorithm as O(ub)
That is to say, given your algorithm, the worst it can perform, in terms of the input size, is ub. And, if we are fine with ub time in the worst case, we are fine with any time when algorithm performs in best-time or average-time.
Because all other times i.e., best and average time are never gonna exceed the worst time. This may be why, we threw the Big Omega, and Big Theta in the dustbin.
And yes, if you are looking for the correct mathematical representations, in terms of functions and bla bla, you can always get those from simple google search.
Common Big O notations and code snippets
Things get more complex and detailed here. So, if you are not already familiar with the basics of Asymptotic Complexity, I suggest you take a walk in the Google Search Engine Park and return after you are thorough with the precursors.
Moving on, let's see some Big O notations that occur often.
O(1), Also called constant time, because no matter the size of the input, the time it takes to do a job is always the same.
For e.g.,
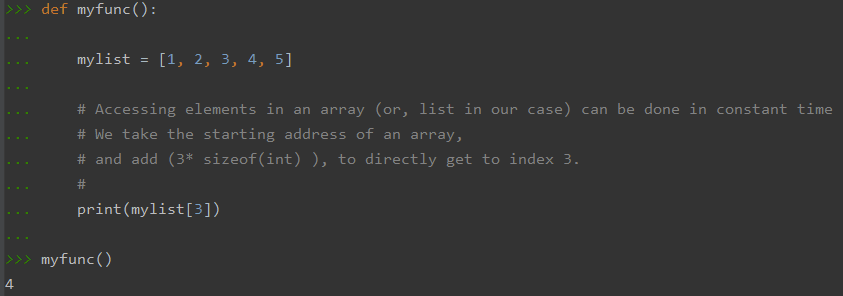
Although most operations on data structures such as arrays, linked-list, set, maps, etc., has similar runtime complexity in major programming languages, it may vary based on the programming language of your choice, because of varying implementation of these data structures in the languages.
Also, there will be numerous compiler optimizations (e.g., loop unrolling) and hardware optimizations(e.g., block size compuation) in order to make your code run faster.
.
.
.
Therefore, I strongly recommend to refer to the documentation of the programming language of your choice, to get to know the runtime complexities of different operations on those data structures. Yes, obviously after we are done reading through the post.
.
.
.
O(n), Also called linear time, because the run-time is proportional to the linear size of the input. Recall the implementation of algorithm that we saw at the beginning of this post.
int n = 24
for (int i= 0 ; i < n; i++)
{
if code_compiles == true
cout << "I love programming"<<endl;
else
cout<<"I am leaving programming for good"<<endl;
}
The only difference in the above implementation is, it is written in C++ instead of Python (because I don't wanna add more intricacy that comes from using, python's range based for loop)
So, how is the runtime complexity of above code, linear ?
Let's say T(n) is the total runtime of the code, with input size of n. Then we can see that the for loop runs for a total of 24 times i.e., n. And, in each iteration of for loop, we are checking if code_compiles variable is true or not, which will again be done 24 times, i.e, n. And, finally depending upon the result of if statement, we print a message which will again be done 24 times.
Therefore, T(n) = n + n +n
i.e., T(n) = 3n
Since, in big O representation, we are only concerned with the behavior of code, when input is sufficiently large, we can get rid of the constant 3 in T(n) = 3n, and say that the code runs in O(n) time.
The same time O(n), is also true for these statements.
for(int i= 0; i <n; i=i+2)
for(int i= n; i >=0 ; i=i-2)
It does not matter if you, increment or decrement the step size by 1, or 2, or even 5. In the long run, for larger inputs, these step sizes would be insignificant. But, do not confuse the increment or decrement with multiplication or division. We'll get there shortly.
To generalize this, let's say you computed the runtime of your algorithm, by summing up times of individual operations and come up with a polynomial,
T(n) = 5n^2 + 2n.Also, your friend, who wants to compete with your implementation, came up with the runtime of
T(n) = n^2 + 10n + 5
To compare both of these algorithms, although the coefficients of n^2 and n terms are different, we don't usually care about these coefficients, along with any lower-order terms such as 5 in , T(n) = n^2 + 10n + 5. Therefore, it's safe to say that, the runtime for both of your algorithms in worst-case in O(n^2).
Remember to always take into consideration, only the highest degree of your polynomial, and disregard everything else.
.
.
.
O(logN), Also called log-linear time, because the run-time is proportional to the logarithm of the linear size of the input.
For eg.,
int n = 24
for (int i= 1 ; i <= n; i= i*2)
{
if code_compiles == true
cout << "I love programming"<<endl;
else
cout<<"I am leaving programming for good"<<endl;
}
Here, we are changing our step size by i*2, rather than just incrementing by 1. Therefore, the loop runs only for log(24) base 2 times i.e., 4.58 times, or to round up 5 times.
This log-linear time is also true for following.
for (int i = n; i > 0; i=i/2)
What if, if we multiply or divide the step size by 3, rather than 2?
Then the runtime would be
log(n) base 3.
.
.
.
O(N ^ 2), Also called quadratic time, because the run-time is proportional to the specific degree of the size of the input.
For eg.,
int n = 24
for (int i= 1 ; i <= n; i++)
{
for(int j = 1; j <= n; j++)
{
if code_compiles == true
cout << "I love programming"<<endl;
else
cout<<"I am leaving programming for good"<<endl;
}
}
Try to guess, how many times the message is printed while executing the above code? If you guessed 24 * 24 times, then congratulations! you've won MultiLoop Badge.
We can easily tell that the loop runs for (N*N ) times, therefore the runtime complexity is O(N^2)
The same is true for the following.
for (int i= 1; i<=n;i++)
{
for (int j=1; j<= i; j++)
{
// statements
}
}
You might argue here that, the nested for loop with j, runs only fewer times, because i increases in order 1,2,3, and so on and, for loop with j, only executes up to i . Therefore, the total runtime should be less than O(N^2). But, think about it. Eventually when i reaches 24, the loop with j would also need to execute for 24 times. Hence, the highest number of iterations is n*n, giving us complexity of O(n^2).
What if you have 3 nested loops, like the following?
for (int i = 0; i<n; i++)
{
for (int j = 0; j<n; j++)
{
for (int k = 0; k<n; k ++) { // statements}
}
}
Then, it would be O(n^3)
.
.
.
Ok, now that we have some grasp of the concept, we can look into more examples below.
What is the time complexity of following?
int n = 24;
for (int i= 1; i<=n;i++)
{
//statements
}
for (int j=1; j<= n; j++)
{
// statements
}
Since the loops are not nested, the 1st for loop runs for n times, and the 2nd for loop runs for n time again. That would give us a total of n+n times, rather than nested loops which we saw earlier having n*n runs.
Therefore, the runtime complexity is still O(n).
.
.
.
And, how about the time complexity of the following?
int p = 0;
int n = 24;
for (int i= 0; p< n; i++, p += i)
{
printf("%s","hey");
printf("\n");
}
Try to analyze and come up with the time complexity, before continuing reading on.
If you have followed through this article, you may have noticed that, determining complexity essentially depends on 3 things, i.e., base case when your program / loop stops running, the rate at which you are progressing on the base case, and the operation you do on each iteration. So, the place to look here is the test condition i.e., p < n
Unlike the previous case, where we had for (int i= 1 ; i <= n; i += 2) having runtime complexity of O(n), the code in above example have some pattern on which the condition variable p increases over the time to reach the base case. It is not the same as adding +2, or +3 on the counter variable continuously over the period of loop.
Did you notice the pattern yet?
The pattern is that the variable p, increases depending upon increments on i. So, let's trace it.
After 1st iteration i = 1, and p is updated by i, which is 1 i.e., p=1
2nd iteration, i =2, and p= 1 +2, since i=2
3rd iteration, i=3 and p = 1 + 2+ 3.
Let's suppose the loop stops after k iterations, which would give us p = 1+2+3+.....+k. This pattern is the sum of natural numbers, given by (k(k+1)) / 2, which we can write k^2 as a rough estimate since in big O, (you already know what I'm trying to say here), we are not concerned on lower order terms.
We know that the loop stops when p=n. Since we know, p = k^2, and we want the big O notation in terms of input size n, we can take square roots on both sides, like
sqrt(n) = sqrt(k^2) i.e., k = sqrt(n).
Therefore, the time complexity is O(sqrt(n)).
.
.
.
Pheww!! That was a long explanation. If you have made it this far, then my congratulations to you, because things are gonna get twisted now when we introduce recursions. Therefore, take a break, refill your cup of tea or, do whatever needs to be done to bring your concentration back. (Research says that, the maximum time you can concentrate on something is between 15- 30 mins.)
.
.
.
Ok, let's begin
.
.
Say, we have a recursive function, that prints out the factorial of a number. For eg., Factorial of 5 is 5*4*3*2*1 = 120. The code is given below.
int myfactorial(int n)
{
if (n == 1) //base case
return 1;
else
return n * myfactorial(n-1);
}
To analyze the time complexity for recursive function, there is a mathematical equation called as
Masters theorem, so if you want the shortcut then you are better off studying that. Here's we'll try to find the complexity using general intuition.
It's very important to visualize the code using recursion tree when we are dealing with such recursive functions.
Similar to what we discussed in the earlier method, we need 3 things to determine the complexity. Can you guess what?
The base case (when does your recursion stop?)
The subproblems(How is your problem reducing in size? What are the subproblems and what rate?)
The computation that you are doing in each of those subproblems?
Time to see the diagram again. The following diagram is the diagram for our myfactorial function.
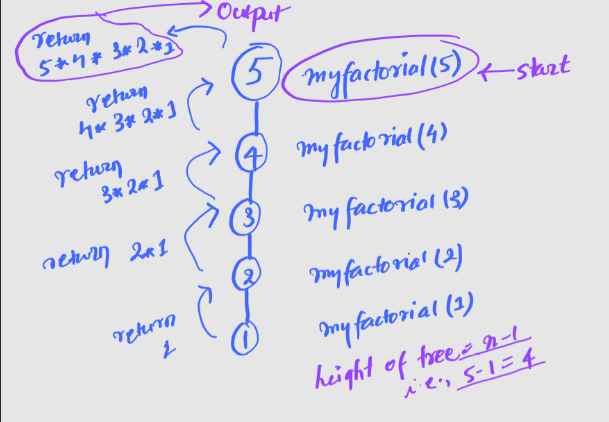
It's self-evident that the initial problem size is n, since we are trying to find the factorial of given number n. And, in each recursive calls we are reducing the problem size by 1 i.e., myrecursion(n-1). Therefore, there would be a total of n-1 recursive calls to the function, which is also height of our recursion tree. Recall that, the height of a tree, is the number of edges on longest downward simple path from root to a leaf.
Each of these recursive calls does some operation (multiplication in our case), which is O(1), and since we have only 1 subproblem in each recursive call, with a total of n calls to the function, the time complexity is O(n).
What if, we replace
n*myfactorial(n-1), byn*myfactorial(n-2), or evenn*myfactorail(n-3)?
It'll be the same as what we discussed for the for loops. The step size would not matter in long run, as long as we are adding or subtracting to the problem size n.
Side note: Multiplication is usually O(n^2), but for our problem, we are rather concerned with the number
n, which we want to find the factorial for. Therefore, thinking in abstract way helps.
.
.
What is the complexity for the following code?
int randomRecursion(int n)
{
if (n <= 0) //base case
return 1;
else
return n * myfactorial(n/2);
}
Here, we are reducing the problem size by a factor of 2, which can be seen in n*myfactorial(n/2). Therefore there would be log(n) base 2 recursive calls. Each recursive call have subproblems, that does the multiplication O(1). Therefore, the run time is O(1* log(n) base 2) i.e., O(log(n) base 2).
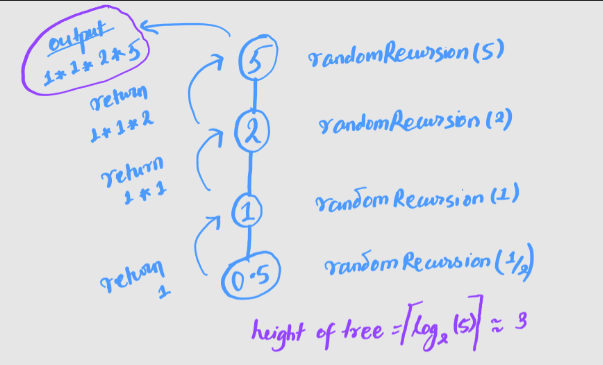
What if, if we replace
n/2byn/4?Then, the time would be O(log(n) base 4).
.
.
.
What is the time complexity for the following code?
int sub2Recursion(int n)
{
if (n <= 0 || n > 10) //base case
return 1;
else
{
int left = sub2Recursion(n-1);
int right = sub2Recursion (n-1);
return left + right ;
}
}
Unlike the previous case where we just had 1 recursive call, in the function, here we have 2 recursive call within the code. Each time, we are reducing the problem size by 1on both the subproblems. Let's observe the recursion tree.
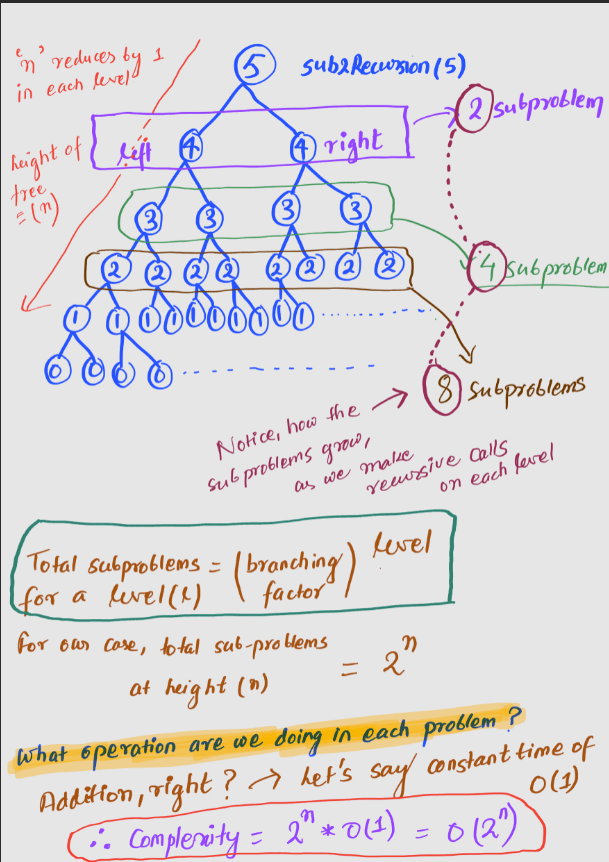
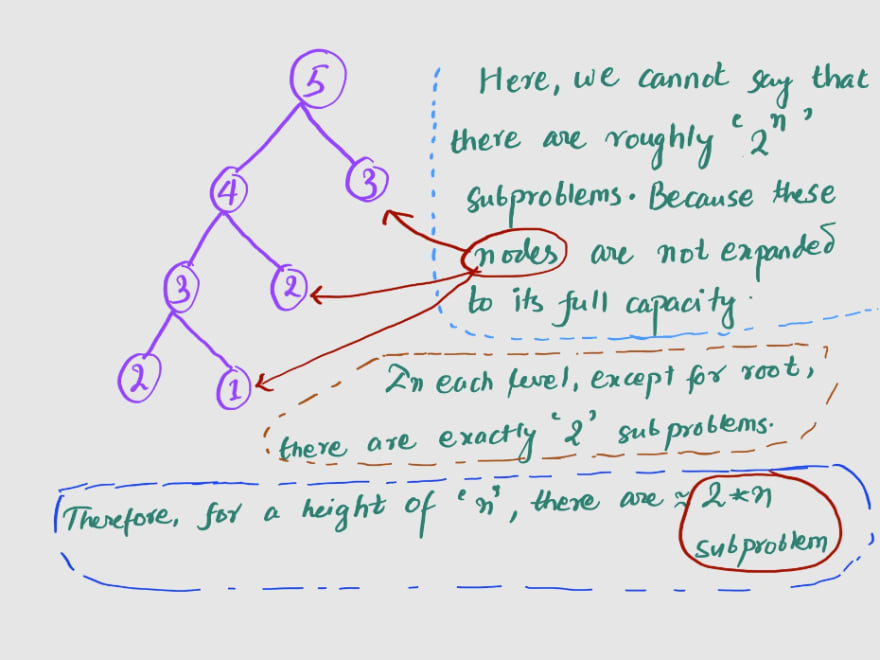
Alternatively, we can also say that, for a complete tree with a branching factor of
2, and heightn, we'll have(2 ^ (n+1)) -1number of nodes (roughly2^n, since we care not for constants). Each of these nodes performs a task, that takes a constant time O(1). Therefore, complexity is O(1) * (2^n) = O(2^n).
.
.
.
What is the time complexity for the following code?
int diffRecurse(int n)
{
if (n <= 0 ) //base case
return 1;
else
{
for (int i=0; i < n; i++)
{
; // dont do anything, just pass
}
return n+ diffRecurse(n-1);
}
}
Here, we just have 1 subproblem in each call to the function diffRecurse. However, on each subproblem, we have to iterate using for loop until n. Iterating using the for loop is O(n) and since there would be a total of n recursive calls to the function, the total runtime complexity would be O(n*n) i.e., O(n^2).
What happens if we change the loop to for (int i=0; i < n; i/2) in above example?
Well, we know that the for loop in this scenario, takes O(logN) time, and there would be n recursive calls as before. Therefore, the complexity would be O(nlogn).
.
.
.
Let's see one final problem, but this time we'll only look at the recursion tree and try to figure out the complexity.
Therefore, for the above diagram (recursion tree for Fibonacci numbers, using memoization), the runtime complexity would be O(n).
I also wanted to cover the space complexity in this post, but since dev.to already marked this post as 15 mind read, I think I'll just skip and conclude this post.
But before we go, let's see the trend of how these functions, increase over the input size. Have a look at the graph below.
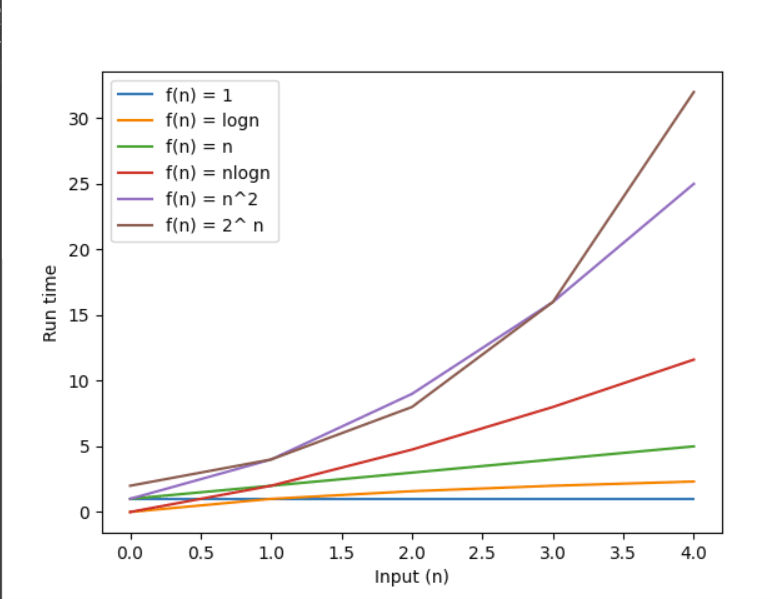
We can clearly see from the above chart that,
O(1) is better than O(logN).. is better than O(N) ... O(NlogN) ... O(N^2) ... O(2^N).
I'll let you fill in the blanks above. Thankyou. Until next time.





Oldest comments (0)