
While Phoenix is becoming a popular MVC framework to build modern web applications with, diving deeper into the BEAM VM and OTP can seem quite daunting at first. If you're familiar with Elixir/Erlang and OTP, you'd have already heard about ETS. While there are other powerful abstractions like GenServers, Agents, GenStage, Observer, etc that the BEAM VM and OTP provide out of the box, let's dive deeper into ETS in this post.
Couple of topics we'll tackle in this post are:
Before we dive into these topics, a brief disclaimer -
I will use the terms Elixir and Erlang interchangeably in this post since Elixir programming language has Erlang interoperability similar to what Kotlin and Clojure has for Java. Also, you can skip the first section if you're already familiar with the basics of ETS.
What is ETS?
ETS or Erlang Term Storage is an in-memory key-value data store that OTP provides to store tuples of Erlang terms. ETS data lookups are fast and of constant time, except in the case of ordered_set ETS table. There are 4 types of ETS tables -
:setis the default type of ETS table, with a single object/value against unique keys.:ordered_set, as the name suggests, is the ordered cousin of:settype. It guarantees retrieval order and the access time is proportional to the logarithm of the number of stored objects.:bagtype enables object insertion with duplicate keys, but the entire row shouldn't be identical.and lastly
:duplicate_bag, which allows duplicate rows and has the least definition on data insertion.
The insert/2 function is consistent across different table types and guaranteed to be atomic in nature, but they are destructive updates in nature. You can unwittingly shoot yourself in the foot with overwriting sensitive data, so you'd want to be familiar with insert_new function which returns a boolean flag in case of insertion failure due to duplicity of key.
You can pass more options on top of type during ETS initialization to leverage optimizations as per need -
-
:named_table- By default, ETS tables are unnamed and can be accessed only by their reference that is returned during initialization. You can instead use this option to set a name to the tables for access. -
:public/:protected/:private- You can set the table's access rights. These rights dictate what processes are able to access the table. We'll discuss their implications later in this post. -
:read_concurrency/:write_concurrency- These concurrent performance tuning optimization flags are set tofalseby default for both of these values. These options make read and write throughput extensively cheaper if bursts of read and write operations are common in the application, however, interleaved read and write operations will accrue penalty in performance. -
:compressed- Disabled by default, but enabling makes the table data be stored in a more compact format to consume less memory. However, it will make table operations slower. -
:decentralized_counters- Defaults to true for:ordered_settables with:write_concurrencyenabled, and defaults to false for all other table types. This option has no effect if the write_concurrency option is set to false. When this option is set to true, the table is optimized for frequent concurrent calls to operations that modify the tables size and/or its memory consumption.
Example ETS initialization with options:
{:ok, table_ref} = :ets.new(:example_table, [:set, :named_table, :protected, read_concurrency: true, write_concurrency: true])
When should you use ETS in your application
Official Elixir documentation uses ETS as a cache, but that is just one of the many use cases. You could very well use the process (GenServer/Agent) state as cache, so how do you recognize the need for ETS in your processes. Recognizing the need for ETS tables is essential especially when the official documentation itself mentions the warning below while showing ETS's use cases.
Warning! Don’t use ETS as a cache prematurely! Log and analyze your application performance and identify which parts are bottlenecks, so you know whether you should cache, and what you should cache. This chapter is merely an example of how ETS can be used, once you’ve determined the need.
What is so special about ETS tables that process states don't fulfill?. After all, they are, as transient as process state. They die when the owner process that has spawned them die as well (unless an heir is declared, we'll get to that later).
ETS tables are stored in off-heap memory, so your Garbage Collection on a process doesn't do overtime for the frequent data operations on ETS tables as they are not garbage collected till the time process is alive. Since ETS is a data store, it provides excellent abstractions to query on data in an optimized and efficient way, some of these abstractions are lookup/2, lookup_element/3, match/2, match_object/2 and select/2 functions (select function's queries are not quite developer-friendly, so you could use fun2ms/2 function to create queries that select function can ingest). You can see its usage here - Elixir School. You should use ETS tables if you want to operate on large set of data and query them efficiently.
While :private access ETS tables do not allow read and write operations outside the owner process, :protected access tables allow read access to all the processes that have reference to the table and :public access tables allow read plus write operations to all the processes with reference. Since all the messages to GenServers or Agents are serialized, meaning all operations on them are performed one at a time, (heeding to the Actor model of concurrency computation) ETS tables come to rescue to enable concurrent data access and manipulation across processes.
ETS tables can also store Elixir structs, so objects like %User{id: 1} do not need to be deserialized after retrieval.
ETS and table management
More often than not, you'd store sensitive data in your ETS tables and would not want that data to be wiped out with unexpected process terminations. For that, ETS can shed ownership in the event of owner process crash and delegate itself to the heir process declared at the time of initialization.
Loss of ETS tables can have widespread implications if they are not architected right. The advantages of ETS tables of providing optimizations on concurrent data access would be lost if processes that depend on that data terminate because of errors in the owner process, with no fault of their own. It's easier and more manageable to architect your ETS tables in a manner that it doesn't necessarily always need heir processes to be more resilient.
Since the public access ETS tables allow reads and writes across application processes you might be tempted to create ETS tables way higher up in supervision/process tree hierarchy than it needs to be in. It will technically work, but it's not worth the developer confusion and data lifecycle as you'd not want data to live forever till application restart. You should rather think in terms of data-localisation when architecting processes that own ETS tables. Processes that access data via ETS tables should be co-located and by virtue, should be restarted together.
A good approach could be to have a dedicated GenServer for the ETS initialization. Since, it won't don't do much more than owning the table; it's less prone to die out of computational errors. Another approach can be to initialize ETS tables in the Supervisor and drill its reference down to its child processes. In this scenario, if your Supervisor dies with reasonable restart threshold and strategy for its children before it terminates itself, it should be fine for the ETS table to be restarted with it.
It's pretty straightforward to trap exit of a process and delegate the ETS table to an heir process, you can get the syntax and insight on the topic in this post - Don't lose your ETS tables
ETS in production
ETS tables are a type of data store and not a database, so there's limited support for transactions - the last write wins, although the writes are atomic and isolated. To implement pseudo-transactional writes for a table, the write operations need to be behind a process, evaluating each mailbox's write message to the table one at a time. For proper transaction support, you should look into Mnesia before integrating PostgreSQL or MySQL.
You might find the use case where you'd need to iterate over all the rows in an ETS table to report to a process or an external service. You can use tab2list/1, foldl/3, or foldr/3 functions for this. While tab2list/1 returns the dump of ETS data reduced in a list, foldl/3 and foldr/3 are essentially reduce functions and you can design the accumulated data. There are other functions like first/1, next/2, prev/2 and last/1 to iterate over tables, but these operations are not isolated and do not guarantee safe travel of tables (meaning objects can be updated/removed/added concurrently while the iteration job is processing) and could introduce side-effects when not used alongside safe_fixtable/2 function unlike foldl/3, foldr/3 and tab2list/1.
If you do have a use case of iterating over ETS tables, you'd want to shard your ETS tables for scalability and by association, processes. You can use Swarm or pg2 to register these processes to a group and trigger group calls which then have to iterate over smaller sets of data. Since these group calls will trigger concurrent iterations with smaller datasets to cover, it'd be much faster to iterate over iterating a giant ETS table.
In ETS, when you do a lookup to get the associated object to the key specified in the table, that value is copied over to the heap of the process. Which has minor to no implications for most use cases, but if your object is significantly large that it incurs penalty on copying amongst processes, you'd want to take a look at persistent_term. The module is similar to ETS in that it provides storage for Erlang terms that can be accessed in constant time, but with the difference that persistent_term has been highly optimized for reading terms at the expense of writing and updating terms.
For debugging ETS tables in production, you can use Observer tool provided by OTP to inspect your table's data. You can connect remotely to the production node and see ETS data in a UI out of the box.
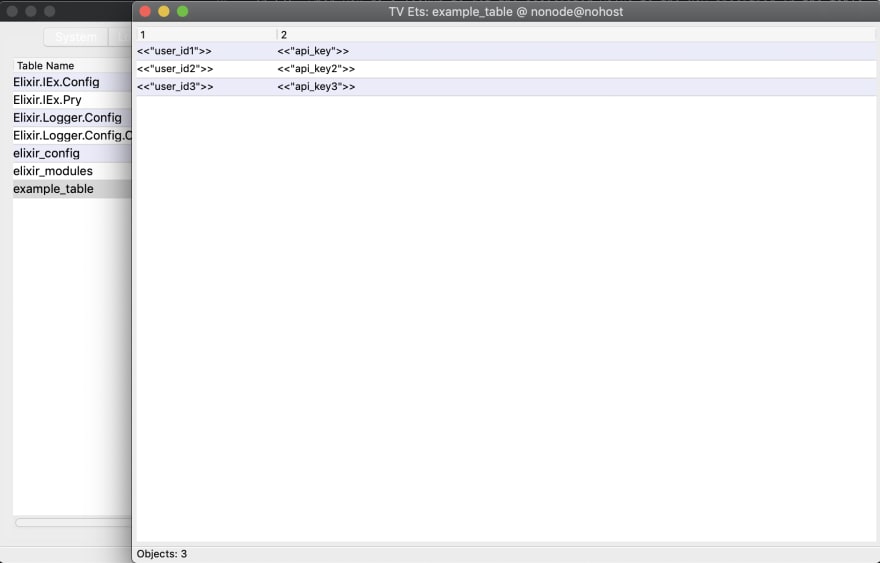
You can get data you'd get from :ets.info/1 for your ETS tables in the Observer in production as well.

Although, the table viewer doesn't provide write access to the tables; Observer do provide the means to kill the owner process. Be very careful when debugging in production as production can easily go down due to unintended actions in Observer.
Another unpopular and very dangerous way to debug large ETS tables, would be of starting a shell inside the release directory and running <release_dir>/bin/yourapp remote_console. This gives you the IEx shell inside the running remote server process. This way, your deployments are no black box, you interact with it the same way you would with a local development environment. You can insert, update, and delete ETS objects in production with this.
I would recommend you not to use this method in production unless you really know what you're doing.
Hope this post has been helpful in introducing and dealing with ETS tables in your systems going forward
Subscribe to the newsletter for early updates, I usually cross-post my articles a little later here - Link :)





Top comments (0)