
- What will be scraped
- Full Code
- Preparation
- Code Explanation
- Using Google Play Movies Store API from SerpApi
- Links
What will be scraped
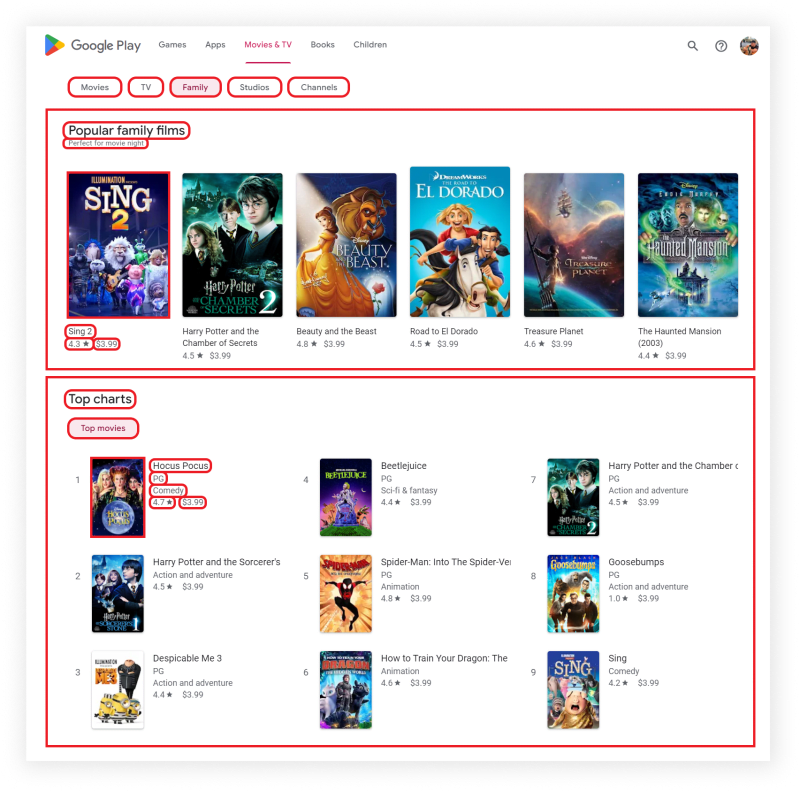
📌Note: Google Play gives different results for logged in and not logged in users.
Full Code
If you don't need explanation, have a look at full code example in the online IDE.
import time, json
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from parsel import Selector
google_play_movies = []
def scroll_page(url):
service = Service(ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--lang=en")
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
options.add_argument("--no-sandbox")
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
old_height = driver.execute_script("""
function getHeight() {
return document.querySelector('.T4LgNb').scrollHeight;
}
return getHeight();
""")
while True:
driver.execute_script("window.scrollTo(0, document.querySelector('.T4LgNb').scrollHeight)")
time.sleep(1)
new_height = driver.execute_script("""
function getHeight() {
return document.querySelector('.T4LgNb').scrollHeight;
}
return getHeight();
""")
if new_height == old_height:
try:
driver.execute_script("document.querySelector('.snByac').click();")
time.sleep(1)
except:
break
old_height = new_height
selector = Selector(driver.page_source)
driver.quit()
return selector
def scrape_top_charts(selector):
section = {
'title': 'Top charts',
'chart': {
'Top movies': []
}
}
for result in selector.css('.itIJzb'):
title = result.css('.DdYX5::text').get()
link = 'https://play.google.com' + result.css('::attr(href)').get()
category = result.css('.ubGTjb > .w2kbF:nth-child(1)::text').getall()
rating = result.css('.ubGTjb div .w2kbF::text').get()
rating = float(rating) if rating else rating
price = result.css('.ePXqnb::text').get()
extracted_price = float(price[1:]) if price else price
thumbnail = result.css('.j2FCNc img::attr(srcset)').get().replace(' 2x', '')
section['chart']['Top movies'].append({
'title': title,
'link': link,
'category': category,
'rating': rating,
'price': price,
'extracted_price': extracted_price,
'thumbnail': thumbnail,
})
google_play_movies.append(section)
def scrape_all_sections(selector):
for result in selector.css('section'):
section = {}
section['title'] = result.css('.kcen6d span::text').get()
if section['title'] is None:
continue
elif section['title'] == 'Top charts':
scrape_top_charts(result)
continue
section['subtitle'] = result.css('.kMqehf span::text').get()
section['items'] = []
for movie in result.css('.UVEnyf'):
title = movie.css('.Epkrse::text').get()
link = 'https://play.google.com' + movie.css('.Si6A0c::attr(href)').get()
rating = movie.css('.LrNMN:nth-child(1)::text').get()
rating = float(rating) if rating else rating
price = result.css('.VixbEe span::text').get()
extracted_price = float(price[1:]) if price else price
thumbnail = movie.css('.etjhNc::attr(srcset)').get()
thumbnail = thumbnail.replace(' 2x', '') if thumbnail else thumbnail
video = movie.css('.TjRVLb button::attr(data-trailer-url)').get()
section['items'].append({
'title': title,
'link': link,
'rating': rating,
'price': price,
'extracted_price': extracted_price,
'thumbnail': thumbnail,
'video': video
})
google_play_movies.append(section)
print(json.dumps(google_play_movies, indent=2, ensure_ascii=False))
def scrape_google_play_movies(lang: str = 'en_GB', country: str = 'US', category: str = 'MOVIE'):
params = {
'hl': lang, # language
'gl': country, # country of the search
'category': category # defaults to MOVIE. List of all movie categories: https://serpapi.com/google-play-movies-categories
}
URL = f"https://play.google.com/store/movies?hl={params['hl']}&gl={params['gl']}"
if params['category'] in ['MOVIE', 'TV', 'FAMILY']:
URL = f"https://play.google.com/store/movies/category/{params['category']}?hl={params['hl']}&gl={params['gl']}"
elif params['category'] in ['promotion_collections_movie_studios', 'promotion_collections_tv_networks']:
URL = f"https://play.google.com/store/movies/stream/{params['category']}?hl={params['hl']}&gl={params['gl']}"
result = scroll_page(URL)
scrape_all_sections(result)
if __name__ == "__main__":
scrape_google_play_movies(lang='en_GB', country='US', category='FAMILY')
Preparation
Install libraries:
pip install parsel selenium webdriver webdriver_manager
Reduce the chance of being blocked
Make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
There's a how to reduce the chance of being blocked while web scraping blog post that can get you familiar with basic and more advanced approaches.
Code Explanation
Import libraries:
import time, json
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from parsel import Selector
| Library | Purpose |
|---|---|
time |
to work with time in Python. |
json |
to convert extracted data to a JSON object. |
webdriver |
to drive a browser natively, as a user would, either locally or on a remote machine using the Selenium server. |
Service |
to manage the starting and stopping of the ChromeDriver. |
Selector |
XML/HTML parser that have full XPath and CSS selectors support. |
Define the list in which all the extracted data will be stored:
google_play_movies = []
Top-level code environment
The function takes the lang, country and category parameters that are passed to the params dictionary to form the URL. You can pass other parameter values to the function and this will affect the output:
params = {
'hl': lang, # language
'gl': country, # country of the search
'category': category # defaults to MOVIE. List of all movie categories: https://serpapi.com/google-play-movies-categories
}
I want to draw your attention to the fact that by clicking on different categories, different links are formed. This is illustrated more clearly in the GIF below:
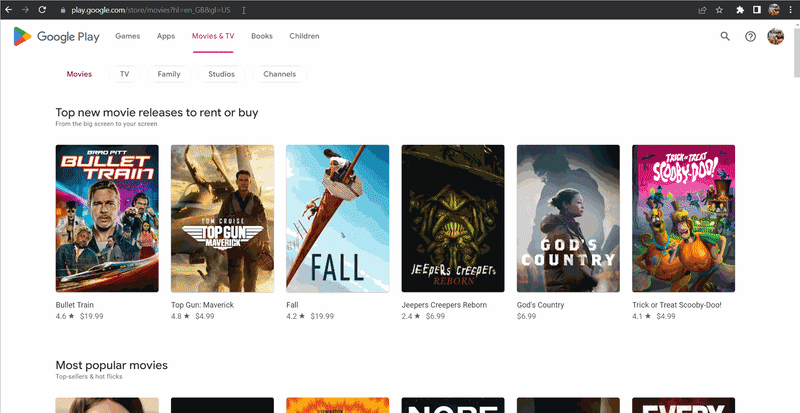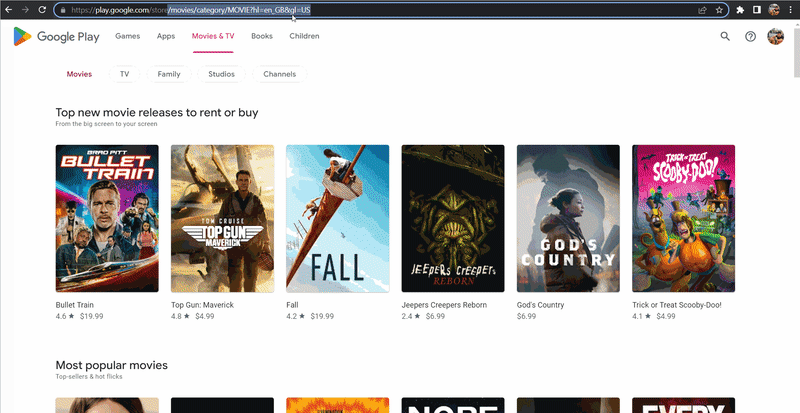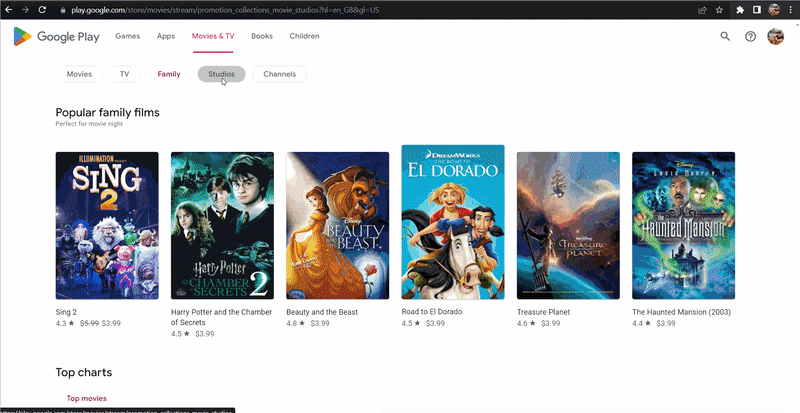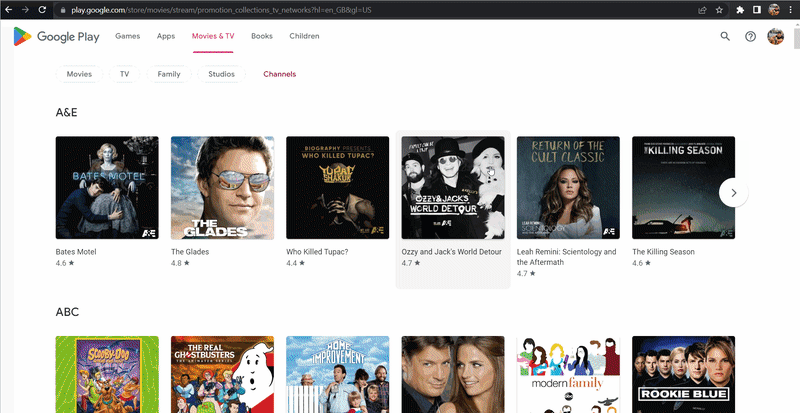
As you can see, there are 3 link options:
- By clicking on the Movies & TV button in the site header, the
https://play.google.com/store/movieslink is generated, which by default displays the Movies category. - By clicking on the Movies, TV or Family category, the
https://play.google.com/store/movies/category/[MOVIE/TV/FAMILY]link is generated. - By clicking on the Studios or Channels category, the
https://play.google.com/store/movies/category/[promotion_collections_movie_studios/promotion_collections_tv_networks]link is generated.
In order for the code to work correctly with each of the categories, it was decided to create a condition according to which the corresponding link will be formed. The first version of the link is left in case the user accidentally passes an incorrect category parameter value to the function:
URL = f"https://play.google.com/store/movies?hl={params['hl']}&gl={params['gl']}"
if params['category'] in ['MOVIE', 'TV', 'FAMILY']:
URL = f"https://play.google.com/store/movies/category/{params['category']}?hl={params['hl']}&gl={params['gl']}"
elif params['category'] in ['promotion_collections_movie_studios', 'promotion_collections_tv_networks']:
URL = f"https://play.google.com/store/movies/stream/{params['category']}?hl={params['hl']}&gl={params['gl']}"
Next, the URL is passed to the scroll_page(URL) function to scroll the page and get all data. The result that this function returns is passed to the scrape_all_sections(result) function to extract the necessary data. The explanation of these functions will be in the corresponding headings below.
result = scroll_page(URL)
scrape_all_sections(result)
This code uses the generally accepted rule of using the __name__ == "__main__" construct:
def scrape_google_play_movies(lang: str = 'en_GB', country: str = 'US', category: str = 'MOVIE'):
params = {
'hl': lang, # language
'gl': country, # country of the search
'category': category # defaults to MOVIE. List of all movie categories: https://serpapi.com/google-play-movies-categories
}
URL = f"https://play.google.com/store/movies?hl={params['hl']}&gl={params['gl']}"
if params['category'] in ['MOVIE', 'TV', 'FAMILY']:
URL = f"https://play.google.com/store/movies/category/{params['category']}?hl={params['hl']}&gl={params['gl']}"
elif params['category'] in ['promotion_collections_movie_studios', 'promotion_collections_tv_networks']:
URL = f"https://play.google.com/store/movies/stream/{params['category']}?hl={params['hl']}&gl={params['gl']}"
result = scroll_page(URL)
scrape_all_sections(result)
if __name__ == "__main__":
scrape_google_play_movies(lang='en_GB', country='US', category='FAMILY')
This check will only be performed if the user has run this file. If the user imports this file into another, then the check will not work.
You can watch the video Python Tutorial: if name == 'main' for more details.
Scroll page
The function takes the URL and returns a full HTML structure.
In this case, selenium library is used, which allows you to simulate user actions in the browser. For selenium to work, you need to use ChromeDriver, which can be downloaded manually or using code. In our case, the second method is used. To control the start and stop of ChromeDriver, you need to use Service which will install browser binaries under the hood:
service = Service(ChromeDriverManager().install())
You should also add options to work correctly:
options = webdriver.ChromeOptions()
options.add_argument('--headless')
options.add_argument('--lang=en')
options.add_argument('user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36')
options.add_argument('--no-sandbox')
| Chrome options | Explanation |
|---|---|
--headless |
to run Chrome in headless mode. |
--lang=en |
to set the browser language to English. |
user-agent |
to act as a "real" user request from the browser by passing it to request headers. Check what's your user-agent. |
--no-sandbox |
to make chromedriver work properly on different machines. |
Now we can start webdriver and pass the url to the get() method.
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
Let's understand how pagination works on the Google Play Movies & TV page. Data does not load immediately. If the user needs more data, they will simply scroll the page and site download a small package of data.
In most categories, you have to scroll to the bottom of the page to get all the data. But we will face the problem that on some categories, when scrolling, the SHOW MORE button additionally appears. By clicking on it, you will get a piece of data. A page scroll demo is shown below:
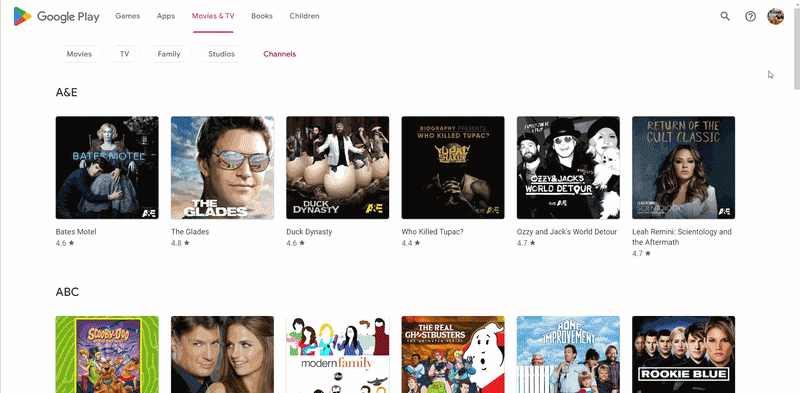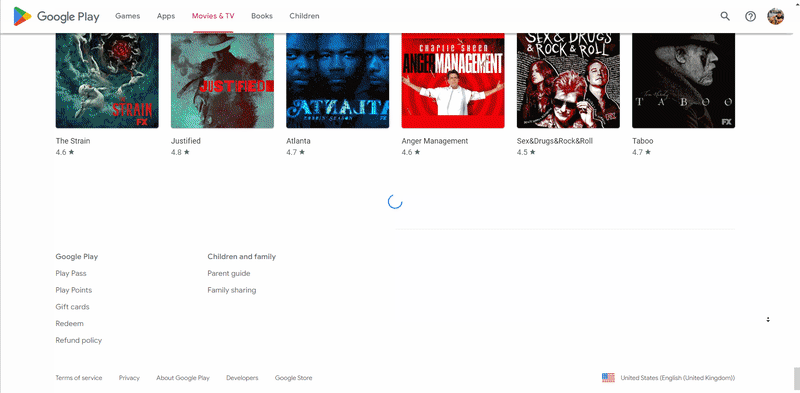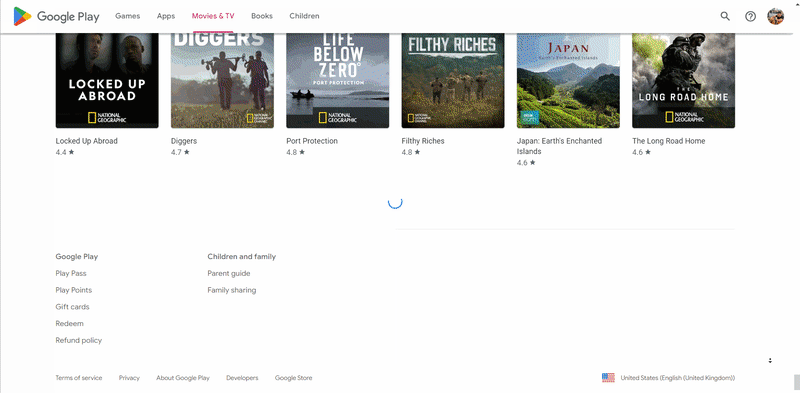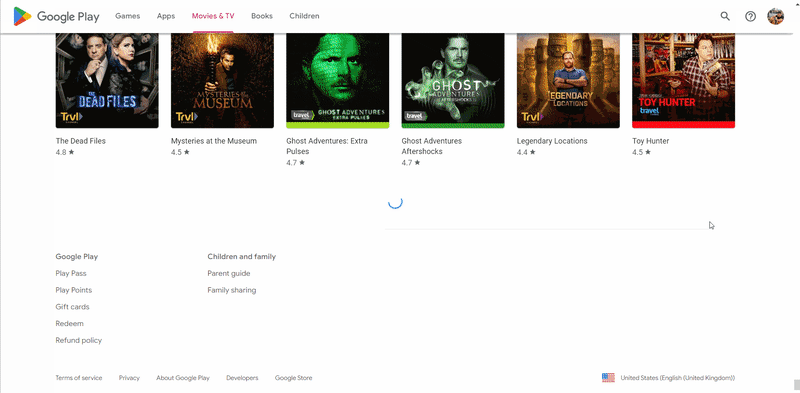
The page scrolling algorithm looks like this:
- Find out the initial page height and write the result to the
old_heightvariable. - Scroll the page using the script and wait for the data to load.
- Find out the new page height and write the result to the
new_heightvariable. - If the variables
new_heightandold_heightare equal, then the program looks for the button selector. If the button exists, then the program is clicking on it and proceed to the next step, else we complete the algorithm. - Write the value of the
new_heightvariable to theold_heightvariable and return to step 2.
Getting the page height and scroll is done by pasting the JavaScript code into the execute_script() method.
# 1 step
old_height = driver.execute_script("""
function getHeight() {
return document.querySelector('.T4LgNb').scrollHeight;
}
return getHeight();
""")
while True:
# 2 step
driver.execute_script("window.scrollTo(0, document.querySelector('.T4LgNb').scrollHeight)")
WebDriverWait(driver, 10000).until(EC.visibility_of_element_located((By.TAG_NAME, 'body')))
# 3 step
new_height = driver.execute_script("""
function getHeight() {
return document.querySelector('.T4LgNb').scrollHeight;
}
return getHeight();
""")
# 4 step
if new_height == old_height:
try:
driver.execute_script("document.querySelector('.snByac').click();")
time.sleep(1)
except:
break
# 5 step
old_height = new_height
Now we need to process HTML using from Parsel package, in which we pass the HTML structure with all the data that was received after scrolling the page. This is necessary to successfully retrieve data in the next function. After all the operations are done, stop the driver:
selector = Selector(driver.page_source)
driver.quit()
The function looks like this:
def scroll_page(url):
service = Service(ChromeDriverManager().install())
options = webdriver.ChromeOptions()
options.add_argument("--headless")
options.add_argument("--lang=en")
options.add_argument("user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.0.0 Safari/537.36")
options.add_argument("--no-sandbox")
driver = webdriver.Chrome(service=service, options=options)
driver.get(url)
old_height = driver.execute_script("""
function getHeight() {
return document.querySelector('.T4LgNb').scrollHeight;
}
return getHeight();
""")
while True:
driver.execute_script("window.scrollTo(0, document.querySelector('.T4LgNb').scrollHeight)")
time.sleep(1)
new_height = driver.execute_script("""
function getHeight() {
return document.querySelector('.T4LgNb').scrollHeight;
}
return getHeight();
""")
if new_height == old_height:
try:
driver.execute_script("document.querySelector('.snByac').click();")
time.sleep(1)
except:
break
old_height = new_height
selector = Selector(driver.page_source)
driver.quit()
return selector
Scrape all sections
This function takes a full HTML structure and prints all results in JSON format.
To retrieve data from all sections, you need to find the section selector of the section. You need to iterate each section in the loop:
for section in selector.css('section'):
# data extraction will be here
The section dictionary structure consists of the keys title, subtitle and items. The values in these keys are retrieved for each section.
Pay attention to the value check in the title key:
- The first condition is used because sometimes an empty section with no values is retrieved.
- The second condition is used to retrieve data from the top charts section. In the Top charts section, the data is retrieved differently and for this the
scrape_top_charts(result)function is used, which will be discussed in the corresponding heading.
section = {}
section['title'] = result.css('.kcen6d span::text').get()
if section['title'] is None:
continue
elif section['title'] == 'Top charts':
scrape_top_charts(result)
continue
section['subtitle'] = result.css('.kMqehf span::text').get()
section['items'] = []
To extract the necessary data, you need to find the selector where they are located. In our case, this is the .UVEnyf selector, which contains all movies. You need to iterate each movie in the loop:
for movie in section.css('.UVEnyf'):
# data extraction will be here
For each movie, data such as title, link, rating, price, extracted_price, thumbnail and video are extracted. You need to find the matching selector and get the text or attribute value. I want to additionally note that the thumbnail is retrieved from the srcset attribute, where it is of better quality:
title = movie.css('.Epkrse::text').get()
link = 'https://play.google.com' + movie.css('.Si6A0c::attr(href)').get()
rating = movie.css('.LrNMN:nth-child(1)::text').get()
rating = float(rating) if rating else rating
price = result.css('.VixbEe span::text').get()
extracted_price = float(price[1:]) if price else price
thumbnail = movie.css('.etjhNc::attr(srcset)').get()
thumbnail = thumbnail.replace(' 2x', '') if thumbnail else thumbnail
video = movie.css('.TjRVLb button::attr(data-trailer-url)').get()
📌Note: When extracting the rating, extracted_price and thumbnail, a ternary expression is used which handles the values of these data, if any are available.
After the data is retrieved, it is appended to the section['items'] dictionary:
section['items'].append({
'title': title,
'link': link,
'rating': rating,
'price': price,
'extracted_price': extracted_price,
'thumbnail': thumbnail,
'video': video
})
At the end of the function, the section dictionary with the received data from the current category is added to the google_play_movie list:
google_play_movies.append(section)
The complete function to scrape all sections would look like this:
def scrape_all_sections(selector):
for result in selector.css('section'):
section = {}
section['title'] = result.css('.kcen6d span::text').get()
if section['title'] is None:
continue
elif section['title'] == 'Top charts':
scrape_top_charts(result)
continue
section['subtitle'] = result.css('.kMqehf span::text').get()
section['items'] = []
for movie in result.css('.UVEnyf'):
title = movie.css('.Epkrse::text').get()
link = 'https://play.google.com' + movie.css('.Si6A0c::attr(href)').get()
rating = movie.css('.LrNMN:nth-child(1)::text').get()
rating = float(rating) if rating else rating
price = result.css('.VixbEe span::text').get()
extracted_price = float(price[1:]) if price else price
thumbnail = movie.css('.etjhNc::attr(srcset)').get()
thumbnail = thumbnail.replace(' 2x', '') if thumbnail else thumbnail
video = movie.css('.TjRVLb button::attr(data-trailer-url)').get()
section['items'].append({
'title': title,
'link': link,
'rating': rating,
'price': price,
'extracted_price': extracted_price,
'thumbnail': thumbnail,
'video': video
})
google_play_movies.append(section)
print(json.dumps(google_play_movies, indent=2, ensure_ascii=False))
| Code | Explanation |
|---|---|
css() |
to access elements by the passed selector. |
::text or ::attr(<attribute>) |
to extract textual or attribute data from the node. |
get() |
to actually extract the textual data. |
float() |
to make a floating number from a string value. |
replace() |
to replace all occurrences of the old substring with the new one without extra elements. |
Scrape top charts
This function takes a top charts section selector and appends the results to the google_play_movies list.
The top charts section is not present in every category. Therefore, it is not possible to determine the correct structure for retrieving data in advance. Accordingly, it is necessary to define the structure of the section at the beginning of the function:
section = {
'title': 'Top charts',
'chart': {
'Top movies': []
}
}
This section has a certain number of movies that should also need to iterate in a loop using the .itIJzb selector:
for result in selector.css('.itIJzb'):
# data extraction will be here
The difference in data extraction in this function is that there is no way to get video, but it is possible to get category. Data is also retrieved by other selectors:
title = result.css('.DdYX5::text').get()
link = 'https://play.google.com' + result.css('::attr(href)').get()
category = result.css('.ubGTjb > .w2kbF:nth-child(1)::text').getall()
rating = result.css('.ubGTjb div .w2kbF::text').get()
rating = float(rating) if rating else rating
price = result.css('.ePXqnb::text').get()
extracted_price = float(price[1:]) if price else price
thumbnail = result.css('.j2FCNc img::attr(srcset)').get().replace(' 2x', '')
After the data is retrieved, it is appended to the section['chart']['Top movies'] dictionary:
section['chart']['Top movies'].append({
'title': title,
'link': link,
'category': category,
'rating': rating,
'price': price,
'extracted_price': extracted_price,
'thumbnail': thumbnail,
})
At the end of the function, the section with the extracted top charts is in turn appended to the google_play_movie list:
google_play_movies.append(section)
The complete function to scrape top charts would look like this:
def scrape_top_charts(selector):
section = {
'title': 'Top charts',
'chart': {
'Top movies': []
}
}
for result in selector.css('.itIJzb'):
title = result.css('.DdYX5::text').get()
link = 'https://play.google.com' + result.css('::attr(href)').get()
category = result.css('.ubGTjb > .w2kbF:nth-child(1)::text').getall()
rating = result.css('.ubGTjb div .w2kbF::text').get()
rating = float(rating) if rating else rating
price = result.css('.ePXqnb::text').get()
extracted_price = float(price[1:]) if price else price
thumbnail = result.css('.j2FCNc img::attr(srcset)').get().replace(' 2x', '')
section['chart']['Top movies'].append({
'title': title,
'link': link,
'category': category,
'rating': rating,
'price': price,
'extracted_price': extracted_price,
'thumbnail': thumbnail,
})
google_play_movies.append(section)
Output
Output for scrape_google_play_movies(category='FAMILY') function:
[
{
"title": "Popular family films",
"subtitle": "Perfect for movie night",
"items": [
{
"title": "Sing 2",
"link": "https://play.google.com/store/movies/details/Sing_2?id=74GR3HZ5fI0.P",
"rating": 4.3,
"price": "$3.99",
"extracted_price": 3.99,
"thumbnail": "https://play-lh.googleusercontent.com/Z94mZzSVqG975oT1dQ7h1Adiql0wAywGbfatetwyv1Bw08KG_CGAzOFAzZ73roku4WGbGWN4SuplfOjNJXc=s512-rw",
"video": "https://play.google.com/video/lava/web/player/yt:movie:j7MgT6LWNEE.P?autoplay=1&embed=play"
},
... other movies
]
},
{
"title": "Top charts",
"chart": {
"Top movies": [
{
"title": "Hocus Pocus",
"link": "https://play.google.com/store/movies/details/Hocus_Pocus?id=XmFT2zzxE5c.P",
"category": [
"PG",
"Comedy"
],
"rating": 4.7,
"price": "$3.99",
"extracted_price": 3.99,
"thumbnail": "https://play-lh.googleusercontent.com/O7o8Ogmsb3GRgTDmFl2pFy5Lgf5Cs8Gk9wKfOtR5Iy0EzuJxcW0O-j-LkQtBC9jRum73JI73Zz7WuOccJLxK=w176-h264-rw"
},
... other movies
]
}
},
... other sections
{
"title": "Storybook favorites",
"subtitle": "From book to screen",
"items": [
{
"title": "Matilda (1996)",
"link": "https://play.google.com/store/movies/details/Matilda_1996?id=dFBYH6GHNzE",
"rating": 4.7,
"price": "$3.99",
"extracted_price": 3.99,
"thumbnail": "https://play-lh.googleusercontent.com/0rsOBWkQc6ydJHDm0A-mOKMuLOb7papinIqyiDxn-fNCJtoMvdjFsxRbfnVZE2VgbO0=s512-rw",
"video": "https://play.google.com/video/lava/web/player/yt:movie:mPvuVAUEETg?autoplay=1&embed=play"
},
... other movies
]
}
]
Using Google Play Movies Store API from SerpApi
This section is to show the comparison between the DIY solution and our solution.
The main difference is that it's a quicker approach. Google Play Movies Store API will bypass blocks from search engines and you don't have to create the parser from scratch and maintain it.
First, we need to install google-search-results:
pip install google-search-results
Import the necessary libraries for work:
from serpapi import GoogleSearch
import os, json
Next, we write a search query and the necessary parameters for making a request:
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_play', # SerpApi search engine
'store': 'movies' # Google Play Movies. List of all movie categories: https://serpapi.com/google-play-movies-categories
}
We then create a search object where the data is retrieved from the SerpApi backend. In the result_dict dictionary we get data from JSON:
search = GoogleSearch(params)
result_dict = search.get_dict()
The data is retrieved quite simply, we just need to turn to the corresponding key. All sections with required data are in the 'organic_results' key, so you need to iterate over them. For each section, we create a dictionary structure that will contain such data as the title, subtitle and items section.
Some sections are missing a subtitle. Therefore, the dict.get() method was used to get it, which by default returns None if there is no data. This will look much better than exception handling which is also used to prevent errors but makes the code less readable and more cumbersome:
google_play_movies = []
for result in result_dict['organic_results']:
section = {}
section['title'] = result['title']
section['subtitle'] = result.get('subtitle')
section['items'] = []
The 'items' key contains data about each movie in this section. Therefore, it also needs to be iterated in a loop. To get the data, you need to refer to the corresponding key. Sometimes, data such as rating or video is missing. Therefore, the dict.get() method was also used here:
for item in result['items']:
section['items'].append({
'title': item['title'],
'link': item['link'],
'product_id': item['product_id'],
'serpapi_link': item['serpapi_link'],
'rating': item.get('rating'),
'price': item['price'],
'extracted_price': item['extracted_price'],
'video': item.get('video'),
'thumbnail': item['title'],
})
The dict.get(keyname, value) method can be used to extract all the data from the dictionary, but I decided to demonstrate the possible errors that the user might encounter.
Example code to integrate:
from serpapi import GoogleSearch
import os, json
params = {
# https://docs.python.org/3/library/os.html#os.getenv
'api_key': os.getenv('API_KEY'), # your serpapi api
'engine': 'google_play', # SerpApi search engine
'store': 'movies' # Google Play Movies. List of all movie categories: https://serpapi.com/google-play-movies-categories
}
search = GoogleSearch(params) # where data extraction happens on the SerpApi backend
result_dict = search.get_dict() # JSON -> Python dict
google_play_movies = []
for result in result_dict['organic_results']:
section = {}
section['title'] = result['title']
section['subtitle'] = result.get('subtitle')
section['items'] = []
for item in result['items']:
section['items'].append({
'title': item['title'],
'link': item['link'],
'product_id': item['product_id'],
'serpapi_link': item['serpapi_link'],
'rating': item.get('rating'),
'price': item['price'],
'extracted_price': item['extracted_price'],
'video': item.get('video'),
'thumbnail': item['title'],
})
google_play_movies.append(section)
print(json.dumps(google_play_movies, indent=2, ensure_ascii=False))
Output:
[
{
"title": "Top new movie releases to rent or buy",
"subtitle": "From the big screen to your screen",
"items": [
{
"title": "Bullet Train",
"link": "https://play.google.com/store/movies/details/Bullet_Train?id=IE8cncuxU1w.P",
"product_id": "IE8cncuxU1w.P",
"serpapi_link": "https://serpapi.com/search.json?engine=google_play_product&gl=us&hl=en&product_id=IE8cncuxU1w.P&store=movies",
"rating": 4.6,
"price": "$19.99",
"extracted_price": 19.99,
"video": "https://play.google.com/video/lava/web/player/yt:movie:q6epB1Ls7vo.P?autoplay=1&embed=play",
"thumbnail": "https://play-lh.googleusercontent.com/QzL3UA85yMmbBEo1XRAiXHWTOzsuQKVm1cP-GaqtR_KEzYaWRGfrdKSB8S84Vu-ch_GdDNKXGm2BYVnaBJQ7=s256-rw"
},
... other items
{
"title": "The Munsters (2022)",
"link": "https://play.google.com/store/movies/details/The_Munsters_2022?id=1rmQZZMRRKY.P",
"product_id": "1rmQZZMRRKY.P",
"serpapi_link": "https://serpapi.com/search.json?engine=google_play_product&gl=us&hl=en&product_id=1rmQZZMRRKY.P&store=movies",
"rating": 2.7,
"price": "$5.99",
"extracted_price": 5.99,
"video": "https://play.google.com/video/lava/web/player/yt:movie:1xx8qPa00x0.P?autoplay=1&embed=play",
"thumbnail": "https://play-lh.googleusercontent.com/HM-EQruQ03GXjSfxm9vt672Z38EFps_M4Zd-5NP9ivnQIQGI3dpFFMrnb41_2mlVtmQYwPpHgdXTAxriMV9-=s256-rw"
}
]
},
... other sections
{
"title": "New to Rent",
"subtitle": "Watch within 30 days of rental",
"items": [
{
"title": "Top Gun: Maverick",
"link": "https://play.google.com/store/movies/details/Top_Gun_Maverick?id=PnS5p3AmpRE.P",
"product_id": "PnS5p3AmpRE.P",
"serpapi_link": "https://serpapi.com/search.json?engine=google_play_product&gl=us&hl=en&product_id=PnS5p3AmpRE.P&store=movies",
"rating": 4.8,
"price": "$4.99",
"extracted_price": 4.99,
"video": "https://play.google.com/video/lava/web/player/yt:movie:q8CxTfNkwyA.P?autoplay=1&embed=play",
"thumbnail": "https://play-lh.googleusercontent.com/UJHa0DJftoFAt7rj1M8w7OmVoPxcFoRJAAqV2hbbz8QI-p5xHTxbjidNKM7gE-jxKzDfCuCfIJ7VBxQIcQ=s256-rw"
},
... other items
{
"title": "Masking Threshold",
"link": "https://play.google.com/store/movies/details/Masking_Threshold?id=ysdRpYTDb_0.P",
"product_id": "ysdRpYTDb_0.P",
"serpapi_link": "https://serpapi.com/search.json?engine=google_play_product&gl=us&hl=en&product_id=ysdRpYTDb_0.P&store=movies",
"price": "$3.99",
"extracted_price": 3.99,
"video": "https://play.google.com/video/lava/web/player/yt:movie:FmnComuP-dU.P?autoplay=1&embed=play",
"thumbnail": "https://play-lh.googleusercontent.com/mil3qkrBd7_4EtmOLH7YDq4zSER3DduBMJRd48jGOzG4jAhgKIKQPyvOH-hqC_tn8eE3UDm5DVc-3qDtafLu=s256-rw"
}
]
}
]
Links
Add a Feature Request💫 or a Bug🐞





Oldest comments (0)