
We are in a data-driven world where data is exchanged through users in the internet everyday via several interconnected devices and appliances which generate a lot of assorted data in real-time every second.
Every minute 1.7 MB of data is created for every person on the planet as indicated by the IBM Research Editorial.
This is made possible by the emergence of IoT - a giant network of connected things and people – all of which collect and share data about the way they are used and about the environment around them. That includes an extraordinary number of objects of all shapes and sizes.
Therefore there's need to harness, collect the large and ever-increasing volumes of data collected from our daily activities and store them for future and easy reference and access.
The choice of how and where to store that data is influenced by the factors indicated below.
i) The form of data collected
Data collected can either be structured, unstructured or semi-structured.
Structured Data - is quantitative data consisting of numbers and values which are highly organized.
Unstructured Data - is qualitative data, cannot be processed and analyzed via conventional data tools and methods since they lack a predefined data model and consists of sensors, text files, audio and video files, etc.
Semi-structured Data - is a combination of both structured and unstructured data which do not have a predefined data model and is more complex than structured data, yet easier to store than unstructured data(e.g., JSON, CSV, XML)
Semi-structured data uses “metadata” (e.g., tags and semantic markers) to identify specific data characteristics and scale data into records and preset fields.
ii) The kind of database collected
A database is an organized collection of structured information or data and can be categorized into:
Relational Database - A relational database organizes data into tables which can be linked to create defined relationships for easy data access. It is often referred to as SQL. Oracle, MySQL, PostgreSQL and SQLite are examples of relational databases.
Non-Relational Database - is qualitative data, cannot be processed and analyzed via conventional data tools and methods since they lack a predefined data model and consists of sensors, text files, audio and video files, etc. It is often referred to as NoSQL which stores info in a dynamic, non-normalized and a more flexible manner. MongoDB, Redis, Aerospike and Couchbase are examples of non-relational databases.
The comparison between SQL and NoSQL is displayed below:
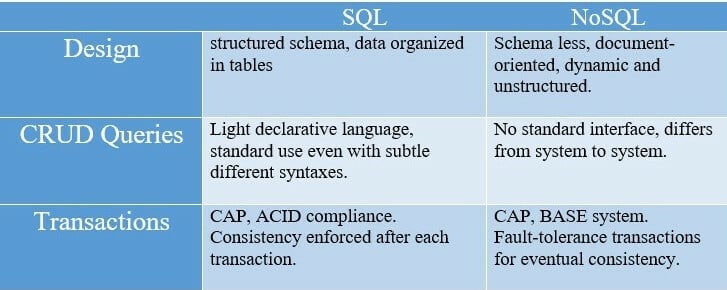
How to choose
This choice is based on the kind of data expected and how it is stored.
For example: A lot of unstructured data, or aggregate information with nesting such as HTML or hierarchical data would best fit in a NoSQL database.
A relational database would require a lot of tables and joints which makes it expensive to pull out aggregates. SQL database is more efficient for a structured data since it easily handles redundancy therefore it's space efficient.
Conclusion
I hope you found it interesting. For any errors observed in this article, please mention them in the comments. 🧑🏻💻
Hope you have a great day! 👋 🌱





Top comments (0)