
Table of Contents
- What's a Solution Architecture?
- The Foundation with Kentico 12 MVC
- Solution Architectures
- Conclusion
What's a Solution Architecture?
For a .NET developer, a solution architecture is the pattern that defines the way projects and classes are organized in our Visual Studio solution.
This includes how things are named and also the relationships between projects (the project-to-project dependencies) and classes (abstractions or dependencies) 🤔.
The choices we make in our solution architecture, when we start building a new Kentico EMS application, can have significant impacts on many things 🧐:
- Time to completion of the project
- Ease of on-boarding of developers
- New team members
- Anyone tasked with quickly diagnosing and solving problems
- Ourselves in the future when we've forgotten everything
- Maintainability of the code base
- Prevention of regressions when introducing new features or corrections
- Flexibility of the application to handle changes
- New business requirements
- Upgrades
- Introductions of new technology
- Testability (both manual and automated)
We cannot have the ideal amounts of everything above 😟.
Some of the choices that would improve testability can increase development time and cost.
A quickly built website may end up being un-maintainable, and require a re-write if the business needs substantial functionality changes.
At an even higher level, choosing the right (and potentially different) approach for each project is more flexible, but could make it more difficult for team members to move between projects if we build multiple websites.
For any agencies developing with Kentico, this is likely something you will want to discuss before choosing an architecture.
The Foundation with Kentico 12 MVC
Before we begin analyzing our options for solution architecture, we should establish the foundation defined for us when we decide to create a Kentico 12 MVC site 👍.
Take a look at Kentico's documentation on the differences between the Portal Engine and MVC development models and also the description of Kentico's MVC implementation if you haven't already.
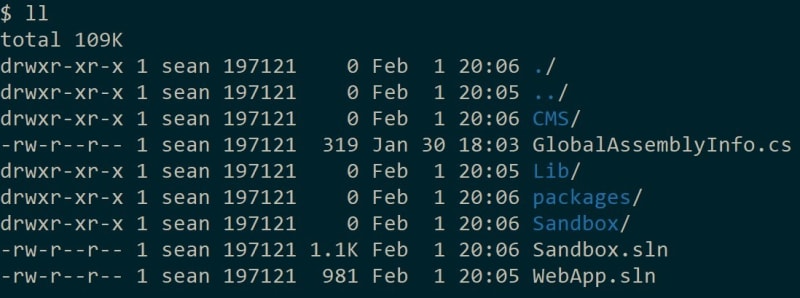
Above we see what the Kentico Installation Manager (KIM) creates when we choose to install a brand new Kentico 12 MVC code base.
We can note a couple things about the solution architecture we are provided:
- There are (2) projects:
- ✔ Content Management - identified by the
CMSfolder, this is the same Kentico Web Forms application we've been using for years to manage and maintain our content. - ✔ Content Delivery - identified by the
Sandboxfolder, this is a standard empty ASP.NET MVC 5 codebase with only a few extra lines sprinkled in for Kentico EMS integration.
- ✔ Content Management - identified by the
- Besides the "MVC" project, the directory looks identical to what we'd see if we had a new Portal Engine site.
From here on I'm going to refer to the "MVC" project as Content Delivery and the "CMS" project as Content Management. This is a differentiation that exists in many other CMS products and frameworks, and I think it's a valuable one 😉.
It also avoids tying us to a specific technology - couldn't our Content Delivery be built on Web API 2 and a React client application? We don't call the CMS project by the technology (Web Forms) it is built on 🤔!
What this means is that we are already working with, at least, a (2) project solution, whereas with previous Kentico Portal Engine sites, we could build everything with (1) project.
We can no longer just think about our project as "My app manages and displays content". Instead we have a clear separation of "Content Management" and "Content Delivery" 😮 (though we can blur those lines with shared libraries, as we will see going forward).
For all the options below, I recommend adding both the Content Management and Content Delivery projects to the same solution file, if only so you don't have to keep (2) instances of Visual Studio running during development 🤗.
I am also going to present all architectures as using Feature Folders for file organization 🏆, which I detailed earlier in my Design Patterns series:

Let's now take a look at our solution architecture options.
Solution Architectures
No Abstractions, Single Layer
The simplest solution architecture takes what we are given "out of the box" and makes very few modifications to it.
I'm calling this architecture "No Abstractions, Single Layer" because we are not creating any custom abstractions (beyond what we get from Kentico) and we only have the (2) .NET projects we start out with.
We create custom Page Types and use them to retrieve data in our Content Delivery project.
Class organization and naming are still important, but we don't need to separate our solution into additional new projects because there is no shared code - we can consider the Content Management part of our code, complete, and we won't make modifications to that project 😄.
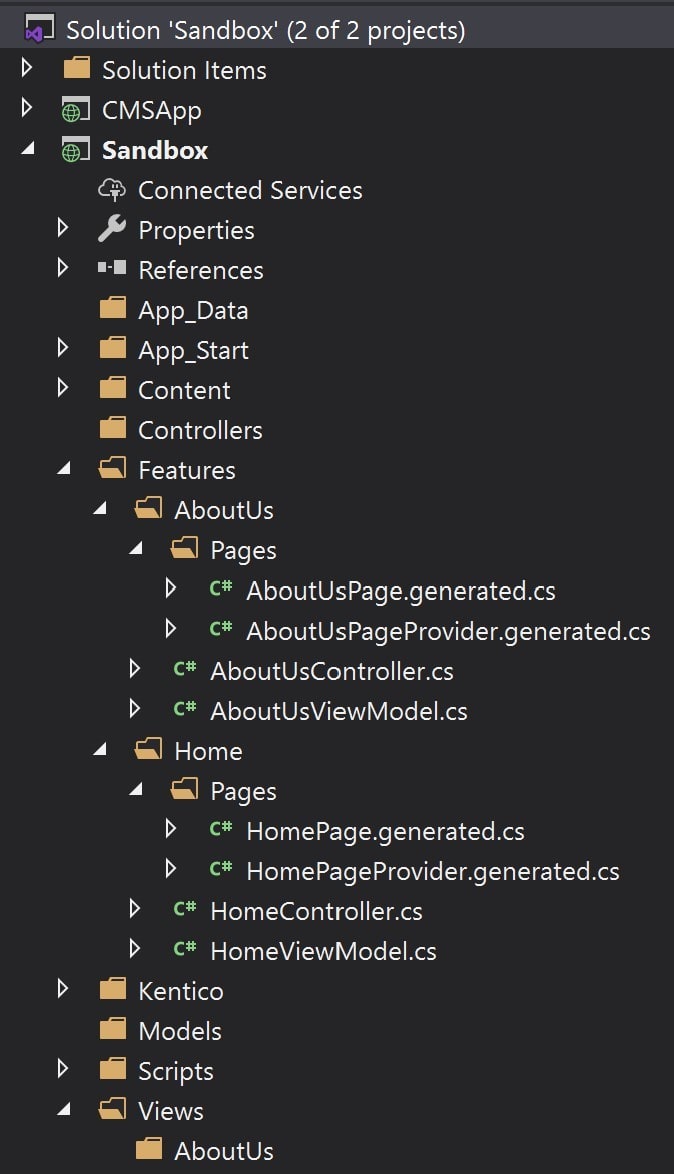
Above we can see how each Feature (in this case, each page), has its own folder and all the classes that implement that feature are contained within it. Classes used for rendering the View (HomeController, HomeViewModel) are next to classes used for data access (HomePageProvider, HomePage).
Below we can see what a very simplistic implementation of our HomeController might be. It includes data access directly in the Index action method, but still creates a HomeViewModel to pass data to the Razor view.
We still create a view model because this post is about making trade-offs, not cutting corners 😎.
// HomeController.cs
public class HomeController : Controller
{
[HttpGet]
public ActionResult Index()
{
var page = HomePageProvider.GetHomePages()
.OnSite(SiteContext.CurrentSiteName)
.Culture(LocalizationContext.CurrentCulture.CultureCode)
.CombineWithDefaultCulture()
.TopN(1)
.TypedResult
.FirstOrDefault();
if (page is null)
{
return HttpNotFound("Could not find page 🤷🏿♀️");
}
var viewModel = new HomeViewModel
{
Text = page.Fields.Text
};
return View(viewModel);
}
}
What if we want to leverage caching and Kentico's powerful MVC-based Page Builder functionality 🤔?
Well, since we are keeping this as simple as possible, we will implement these things in our controller action method:
public class HomeController : Controller
{
[HttpGet]
public ActionResult Index()
{
var page = CacheHelper.Cache(() =>
HomePageProvider.GetHomePages()
.OnSite(SiteContext.CurrentSiteName)
.Culture(LocalizationContext.CurrentCulture.CultureCode)
.CombineWithDefaultCulture()
.TopN(1)
.TypedResult
.FirstOrDefault(),
new CacheSettings(1, nameof(HomeController), nameof(Index)));
if (page is null)
{
return HttpNotFound("Could not find page 🤷🏿♀️");
}
HttpContext.Kentico().PageBuilder().Initialize(page.DocumentID);
var viewModel = new HomeViewModel
{
Text = page.Fields.Text
};
return View(viewModel);
}
}
We can already see that if we continue to add functionality (marketing automation, logging, multiple data sources) to the home page, we are going to end up with a large and complex controller 😖.
This approach is often referred to as the Fat Controller and is considered an anti-pattern.
It's comparable to placing all our code in a Web Forms page code-behind when building a Kentico Portal Engine site 💣.
There are ways we can help solve the increasing complexity of our controller with abstractions and infrastructure. That said, if we need to grow the code base we will run into additional architecture problems.
Let's summarize the benefits and problems with this approach:
-
Pros
- Extremely quick to implement
- Easy to locate the right classes
- No project dependencies (simple builds)
- Few abstractions or layers ("just look in the controller!")
- Changes to our Page Types propagate through the code quickly (minimal data mapping)
-
Cons
- Difficult or impossible to unit test (due to direct use of
*Context,CacheHelperand data access in the controller) - Cross-cutting concerns (caching, logging, Page Builder) are not DRY
- Lack of abstractions means the controller has to know how to do everything
- Growth in controller complexity is not sustainable
- Difficult or impossible to unit test (due to direct use of
With this solution architecture we could probably build a site extremely quickly, and that might be its best sales-pitch 💰.
It does, however, come with all the caveats, our industry has discussed for years, that show up when we build the entire application in the view layer 💩.
Multiple Abstractions, Single Layer
Moving on from the simplest approach, we next see the design that Kentico uses in its DancingGoat demo site 🤓.
This architecture has plenty of infrastructure and abstractions, but continues with a single layer of projects (Content Management and Content Delivery).
The DancingGoat sample project uses the traditional MVC class organization that we get when creating a blank MVC project (File -> New Project) in Visual Studio. I'm not a fan of this organization (I call it "Framework Features" organization, instead see "Feature Folders" above).
So, what are the key differences we see with the "Multiple Abstractions, Single Layer" architecture and the previous one?
Let's look at the HomeController code as an example:
public class HomeController : Controller
{
private readonly IHomeRepository homeRepository;
public HomeController(IHomeRepository homeRepository)
{
if (homeRepository is null)
{
throw new System.ArgumentNullException(nameof(homeRepository));
}
this.homeRepository = homeRepository;
}
[HttpGet]
public ActionResult Index()
{
var page = homeRepository.GetHomePage();
if (page is null)
{
return HttpNotFound("Could not find page 🤷🏿♀️");
}
HttpContext.Kentico().PageBuilder().Initialize(page.DocumentID);
var viewModel = new HomeViewModel
{
Text = page.Fields.Text
};
return View(viewModel);
}
}
Looking at this code, we can see that we have a constructor dependency, IHomeRepository, in the HomeController, which handles getting data from our data source.
// IHomeRepository.cs
public interface IHomeRepository
{
HomePage GetHomePage();
}
// HomeRepository.cs
public class HomeRepository : IHomeRepository
{
public HomePage GetHomePage() =>
CacheHelper.Cache(() =>
HomePageProvider.GetHomePages()
.OnSite(SiteContext.CurrentSiteName)
.Culture(LocalizationContext.CurrentCulture.CultureCode)
.CombineWithDefaultCulture()
.TopN(1)
.TypedResult
.FirstOrDefault(),
new CacheSettings(1, nameof(HomeRepository), nameof(GetHomePage)));
}
Page Builder functionality is still handled in the controller and the Kentico custom Page Types are exposed to the view layer, via the IHomeRepository.
I consider all the pieces of the MVC paradigm (Models, Views, Controllers) to be concerns of the View layer. So anything we have access to in a controller is exposed to the view layer.
With the addition of abstractions we can have the possibility of automated unit tests. The more abstractions we add, the easier it is to unit test the parts of our application in isolation 😁.
While the solution architecture has changed, these new abstractions are not being shared with the Content Management application and there are no shared libraries.
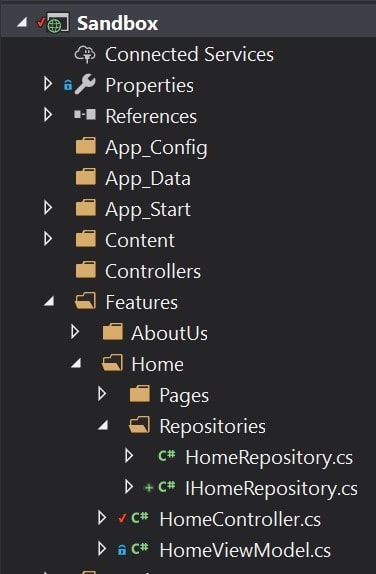
Let's summarize the benefits and problems with this approach:
-
Pros
- Still relatively quick to implement
- Easy to locate the right classes (feature folders, single project)
- No project dependencies (simple builds)
- Changes to our Page Types propagate through the code quickly (weak abstraction layers)
- Parts of our application can be verified by automated tests
- Cross-cutting concerns (caching, logging, Page Builder) can be DRY by applying them to abstractions
- More flexible application architecture
-
Cons
- Requires setting up a composition root and thinking differently about dependencies
- Abstractions cannot be shared with the Content Management application
- The flexibility that abstractions create also introduces some complexity
- Controllers still have to know about data access (custom Page Type classes) types
To learn about how we can take advantage of abstractions for Cross-cutting concerns, see my post Kentico 12: Design Patterns Part 12 - Database Query Caching Patterns
N-Tier Architecture - Layers as Abstractions
Once we begin to focus on our abstractions we see that the most obvious and common area of abstractions is in data access - especially in a Kentico application 🧐.
The next evolution of our application architecture moves data access into its own project layer.
This results in the classic N-Tier Layered Architecture for the solution:

Above, we can see a new Sandbox.Data project where all the data access code lives. The Kentico generated HomePage type has been moved to this project, along with the repository abstraction and implementation.
The
Sandbox.Dataproject will need to add the Kentico.Libraries NuGet package as a dependency to enable the underlying Kentico database access types.
In addition to the move of these files from the view-layer-focused Sandbox project, we have added a new HomePageData class which helps preserve the boundary between the view layer and the data access layer 😄.
Let's look at how our Home feature classes have changed:
// HomePageData.cs
public class HomePageData
{
public int DocumentId { get; set; }
public string Text { get; set; }
}
// IHomeRepository.cs
public interface IHomeRepository
{
HomePageData GetHomePage();
}
// HomeRepository.cs
public class HomeRepository : IHomeRepository
{
public HomePageData GetHomePage() =>
CacheHelper.Cache(() =>
HomePageProvider.GetHomePages()
.OnSite(SiteContext.CurrentSiteName)
.Culture(LocalizationContext.CurrentCulture.CultureCode)
.CombineWithDefaultCulture()
.TopN(1)
.Columns(
nameof(HomePage.DocumentID),
nameof(HomePage.HomePageText)
)
.TypedResult
.Select(page => new HomePageData
{
DocumentId = page.DocumentID,
Text = page.Fields.Text
})
.FirstOrDefault(),
new CacheSettings(1, nameof(HomeRepository), nameof(GetHomePage)));
}
The addition of the HomePageData class means we gain a couple things:
- ✔ The "View" layer doesn't have to interact with Kentico's data access technology for unit testing.
- ✔ We can be more specific in our querying because we know exactly how much we expose to consumers of the
IHomeRepository. - ✔ The Content Management application could consume our
Sandbox.Dataproject if there are common ways of querying and updating data in our data access, or business logic implementations.
From the points above, 1) is great for being able to focus on verifying the quality and accuracy of our code and prevent regressions since it makes testing easier 👏🏿.
2) reduces flexibility of the application in some ways (we now have 2 classes to map our data to HomeViewModel and HomePageData), while increasing it in others (we can make optimizations and changes in the data access without affecting consumers) 👍.
3) is helpful if we have a need for code re-use at the data access level, and many larger projects do see these opportunities (ex: Scheduled Tasks, Global Events) 🤓.
Our HomeController code is effectively unchanged since we had already abstracted away the querying details in our Multiple Abstractions, Single Layer architecture.
- Pros
- Somewhat easy to locate the right classes (feature folders and abstractions co-located with implementations, but there are multiple projects)
- Data access logic is easier to optimize
- Our View layer has no dependencies on Kentico data access, making automated unit testing much simpler
- Cross-cutting concerns (caching, logging, Page Builder) can be DRY by applying them to abstractions
- Data access code can be re-used in the Content Management application
- More flexible application architecture
- Cons
- Takes longer to implement since more preparation and design is required up-front
- More complex builds and project dependencies requires a better understanding of how Visual Studio and .NET work
- Requires setting up a composition root and thinking differently about dependencies
- Changes to our Page Types propagate through the code slowly because the abstractions are stronger (we have to update 3 "data transfer" classes with each Page Type change)
A Brief Discussion of N-Tier Architectures
If we look at what we've created, it's not too hard to see that the entire Sandbox.Data project is layer and also an abstraction. It exposes new types (HomePageData) to the consuming layer above it (Sandbox).
With the N-Tier Architecture, we can add as many layers as we need, which means a new abstraction for each layer.
Imagine we need to add a layer of complex business logic in a Sandbox.Service project.
Sandbox.Service exposes IHomeService and implements this interface through HomeService. HomeService has a dependency on IHomeRepository to get its data. IHomeService is then consumed by HomeController.
HomeController->IHomeService->IHomeRepository(-> means "depends on")
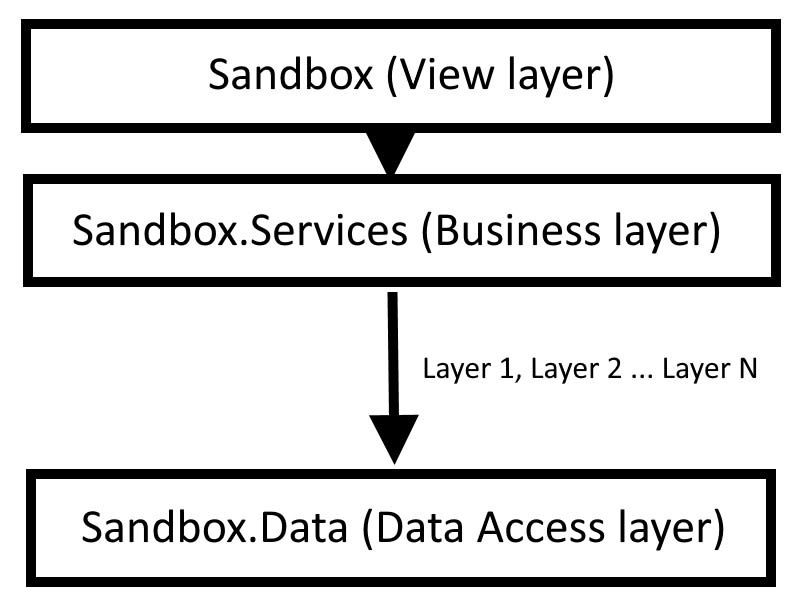
Each layer we add brings its own abstractions and implementations and the direction of dependencies of these layers is from the top (View layer) down (to the data layer) 🤔.
Classic N-Tier applications didn't use interfaces and so the layers were very tightly coupled, with the View layer being coupled to the data access layer through transitive dependencies 😨.
But, we've taken advantage of interfaces so we've escaped that tight coupling, right?
Technically yes, but mentally no 😕.
We are still looking at the application as layers stacked on each other with the database being the foundation. This mental model will inevitably lead us into decisions that reinforce this perspective and potentially introduce coupling (perhaps through leaky abstractions) that we did not intend 🤯.
N-Tier Architectures work fine for a large number of applications, especially when the layers are clearly defined and abstractions are introduced to lessen coupling 👍.
However, there is one more evolution of our solution architecture to help resolve this issue.
Onion Architecture - Layers as Implementations
We've already created our abstractions and implementations, so this final change will focus more on their separation.
The N-Tier Architecture has us looking at our application as a vertical set of layers, with each layer depending on those below it. This treats the layers as abstractions.
The Onion Architecture treats layers as implementations because it places the abstractions and core "domain" data classes at the center of multiple layers, like an onion 🤓.

Above we can see that all the interfaces (including our made up IHomeService) are contained within the center of the architecture, whereas the implementations are all in the outer layers.
It might be strange to think about the View layer being the same as the Data Access layer, but this mental shift brings some benefits.
With an Onion Architecture we stop thinking of the database as the foundation or center of the our world and instead we have to fill that void with abstractions and models of our data 🙂.
For smaller and less complex applications this is definitely overkill 😅.
For larger ones that source data from multiple locations (web service, remote database, local database, file system, ect...) or have complex business rules about how that data is retrieved and modified, then focusing on the shape of the data that flows through the application and the abstractions that work with that data, independent of their implementation, helps us manage complexity and maintain flexibility 😎.
Let's implement this approach in our Sandbox solution:
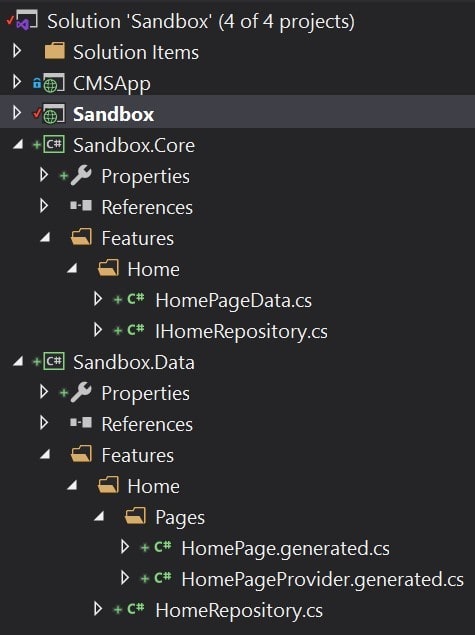
Above we can see that the IHomeRepository and HomePageData have been moved to a new project Sandbox.Core. This project only includes models and interfaces 😮.
We've also changed the implementation details of HomePageData, treating it as a readonly object once created that also protects its internal state with constructor guards:
public class HomePageData
{
public int DocumentId { get; }
public string Text { get; }
public HomePageData(
int documentId,
string text)
{
if (text is null)
{
throw new System.ArgumentNullException(nameof(text));
}
DocumentId = documentId;
Text = text;
}
}
Since this type has become the core package of data passed around our application, we want to ensure it can't be created incorrectly or modified in a way that puts it into an invalid state 💪.
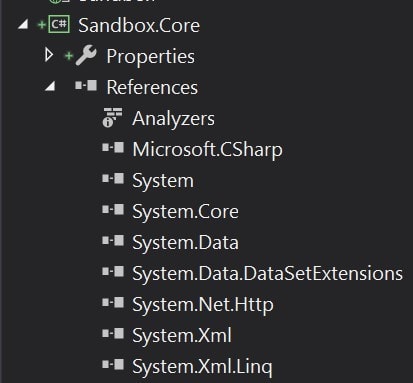
If we look at the dependencies of Sandbox.Core we can see there are almost none, especially dependencies like Kentico libraries that define implementation details:
Our Sandbox.Data project depends on Sandbox.Core for the IHomeRepository interface and HomePageData model class.
The Sandbox project depends on Sandbox.Core as well, for the IHomeRepository interface, which is still a constructor dependency of HomeController.
While, Sandbox will have to take a dependency on Sandbox.Data to configure the composition root (likely for an Inversion of Control container library like Autofac), we won't expose the types of Sandbox.Data anywhere - it has now become an implementation detail unto itself 👍.
The rest of our code remains unchanged with the exception of some namespace updates to reflect moving some types to Sandbox.Core.
Now that we've identified our abstractions and pushed the implementation details to the outside of our "onion", we are in good position to review the requirements of our application and start identifying other areas that could be moved around.
What's part of our core? What's part of the outer shell? What should be in the middle 🤔?
These questions are not always easy to answer, but by changing the way we think about the architecture and patterns of our application, adopting an inside -> out approach with an Onion Architecture, we are in a good place to consider them 👏🏿.
- Pros
- Data access logic is easier to optimize
- Our View layer has no dependencies on Kentico data access, making automated unit testing much simpler
- Our business logic (if it exists) has no dependencies on implementations (View layer, Data Access, Web Service technologies), making it very easy to unit test
- Cross-cutting concerns (caching, logging, Page Builder) can be DRY by applying them to abstractions
- Data access code can be re-used in the Content Management application
- Extremely flexible and robust application architecture that forces us to focus on abstractions and data flow and consitency
- Cons
- Separating abstractions from implementations makes implementations harder to locate
- Takes the longest to implement since we think about abstractions and models instead of technologies and implementations
- More complex builds and project dependencies requires a better understanding of how Visual Studio and .NET work
- Requires setting up a composition root and thinking differently about dependencies
- Changes to our Page Types propagate through the code slowly because the abstractions are stronger
Conclusion
We've covered a lot of ground in this post 😅!
We started out reviewing what a Solution Architecture really is and why the choices we make around this architecture should matter to us, touching on a few examples of the impact that our decisions could have.
Then we looked at the foundation of our Kentico 12 MVC projects - the separation of Content Management from Content Delivery. This set the stage for the different architectures that were proposed.
The No Abstractions, Single Layer architecture was the simplest and fastest to implement. It's a great option for small sites with limited complexity that need to be built quickly 🤗.
The Multiple Abstractions, Single Layer design can be seen in Kentico's DancingGoat demo site. This architecture allows for plenty of complexity and abstraction 😊, but still treats the Content Delivery application as a homogeneous unit.
Many sites will probably start out using this approach but then migrate into the N-Tier - Layers as Abstractions architecture as they mature.
The creation of separate .NET projects for layers of our application enables code re-use in the Content Management app and also places a strong focus on our abstractions 👍🏿.
The N-Tier Architecture is a classic approach which models where most applications end up. There are variations of it, but the consistent factor in all of them is that Data Access is the foundation of the application, and the View or Presentation layer is the top.
Finally, we looked at Layers as Implementations with Onion Architectures, as an alternative to building a Data Access centered application.
By moving all of our implementations to the outer shell of our architecture and then focusing on abstractions and data models as our Core, we end up with a design that forces us to consider, more flexibly, how everything fits together 💪.
If you have any questions about the architectures we reviewed or how to implement the patterns, leave a comment below.
As always, thanks for reading 🙏!
We've put together a list over on Kentico's GitHub account of developer resources. Go check it out!
If you are looking for additional Kentico content, checkout the Kentico tag here on DEV:
Or my Kentico blog series:





Oldest comments (5)
Thank you for this post and for the entire series. It's very interesting to read. After using Kentico for a year, I definitely learned a lot and it nice to see other ideas and solutions.
I have a question about the Onion Architecture. How would you handle page types with a lot of fields? In your
HomePageDataclass, passing two values into the constructor works great, but what if you have 10, 30, or even more properties? Right now, I'm passing in an instance of the Kentico page type class (e.g.HomePage) into the constructor and have the Data/Dto class take care of copying the value it needs. However, this approach requires references to Kentico libraries. Another option would be to have theHomeRepositoryset the values, but this requires public setters inHomePageData, so it's no longer a read-only object.Is there a good solution for this without having an excessive amount of constructor properties?
Hey Andy!
Thanks for reading and I'm glad the posts have been helpful.
Hmm... that seems like a lot. Does your page type actually have 20-30 fields? This might be a content modeling issue that is leading to a technical one.
Have you looked at AutoMapper? It can help with passing data between layers, especially when the types and property names are pretty well aligned. This allows each layer to own its own types which is important when keeping them loosely coupled.
Another option is to break up the data into groups that get mapped to the view through child actions. Assuming your data access is cached, calling the same DB query APIs multiple times won't cause issues, and you can then map your page type into different DTOs that returned by separate child action calls in the same view.
You can try this same approach with MVC widgets if you also need a flexible layout (have different widgets display different sets of values from the current page).
Finally, all rules and patterns are meant to be broken when appropriate.
If you don't have complex business rules and instead are mapping page type fields directly to the view, then it might make sense to even put the DB access in the controller and have the page type be the view model.
This last approach trades loose coupling and the ability to decorate and apply cross cutting for the benefit of simplicity.
Kentico Experience 13 is going to have Route To View where you are provided a strongly typed view model that is your page type instance... no customer controllers or repositories are needed.
There are pros and cons to each approach. Some require more up front work but allow more flexibility while others are far faster (and maybe less complex).
The key is to make informed trade offs where you (and your fellow devs) understand and agree on the costs and benefits.
Content sites might not need an Onion architecture, just like CRUD apps might not need Event Sourcing and Kuberentes... 😁
I just realized I might have skipped answering your specific question 🤦♂️!
If you are using an Onion architecture, then you should have a domain class (
HomePageData) that is in yourCoreproject. By having it there you can't take a dependency on your data access implementation project (let's call itData).This means
HomePageDatawill need to have a constructor that only accepts:CoreprojectSo you can't use the generated
HomePagepage type class as a parameter.Each layer should own its abstractions, which means the
HomePageDataand (if you are using a repository pattern) theIHomePageRepositoryshould be defined inCore, while theDataproject will have an implementation ofIHomePageRepositorywhich will returnHomePageData.Core
HomePageData(domain class)IHomePageRepository(domain abstraction)Data
HomePage(custom page type class)KenticoHomePageRepository(implementation of domain abstraction)Now your presentation project (let's call it
Web) will rely on the abstraction and domain type and never access the types inDatadirectly:Notice here that it's ok for the
HomePageViewModelto depend on the domain abstractionHomePageData- domain types are meant to be used everywhere since they don't have any volatile dependencies themselves, instead it's the implementations that we want to keep isolated.Great post Sean, thanks for explaining in detail.
In your Sandbox.Core, how would you represent data such as PageAttachment. We use BasePageData for all other "Page" things such as NodeId, Guid, etc. including IList where PageAttachment class has a property of Kentico.Content.Web.Mvc.IPageAttachmentUrl. Do you have any tips on how to set it up in core without referencing Kentico libs?
Thanks
I handle page attachments and media library files the same way I handle Page Type data.
I create POCO class that represents the minimum about of information the presentation layer needs about that object and project the
*Infotype into it within my data access layer.I typically have a
ImageContenttype and aMediaContenttype. These have theGuidand ID fields of the database objects they represent and other important values like URLs and Labels. Images have width/height properties.But the key part is that I'm returning a limited set of values and only working with the Kentico types in the data access implementation methods.
This makes my caching slimmer and allows me to adjust my data access implementation more easily (returning an
AttachmentInfomakes it hard to return additional metadata from an external system, for example).Specially to your question, the
IPageAttachmentUrlare resolved and turned into a stringURLproperty on myMediaContenttype in the data access implementation.