It's incredible how much we can achieve in the browser today, I'm still blown away by how far the platform has gone, from 3D to Bluetooth, to semi-persistent storage, there is now little that can't be done entirely from the browser.
And this is also true for machine learning. Tensorflow.js has made extremely easy to use existing models, or even train new ones, entirely client side.
In this experiment I'm going combine this with hls.js, a polyfill that adds HTTP livestream support to all major browsers, to perform real time object detection on a live stream.
It turned out to be quite straightforward, the core bit looks like this:
async function init() {
const videoNode = document.getElementById("video");
const model = await CocoSsd.load();
const video = await createVideoStream(videoNode, getStreamUrl());
const onDetection = await startDetection(model, video);
const canvas = drawPredictions(video, onDetection);
videoNode.parentNode.appendChild(canvas);
}
CocoSsd is a TensorFlow.js porting of the COCO-SSD model we can use straight away.
Once the model has loaded createVideoStream takes the HTTPS live stream URL and uses hsl.js to load it in a video element. startDetection then takes the video element and pass it to the model, in return we get a list of all the objects detected, their bounding box and the confidence of the detection:
async function startDetection(model, video) {
let detectionCallback = null;
const callback = async () => {
let predictions = [];
try {
predictions = await model.detect(video);
} catch (error) {
pace(callback);
}
if (detectionCallback) {
detectionCallback(predictions);
}
pace(callback);
};
return (onDetection) => {
detectionCallback = onDetection;
pace(callback);
};
}
pace is simply window.requestIdleCallback || window.requestAnimationFrame, also a try\catch block ensures that when the model throws we simply re-queue the function without breaking the whole experiment.
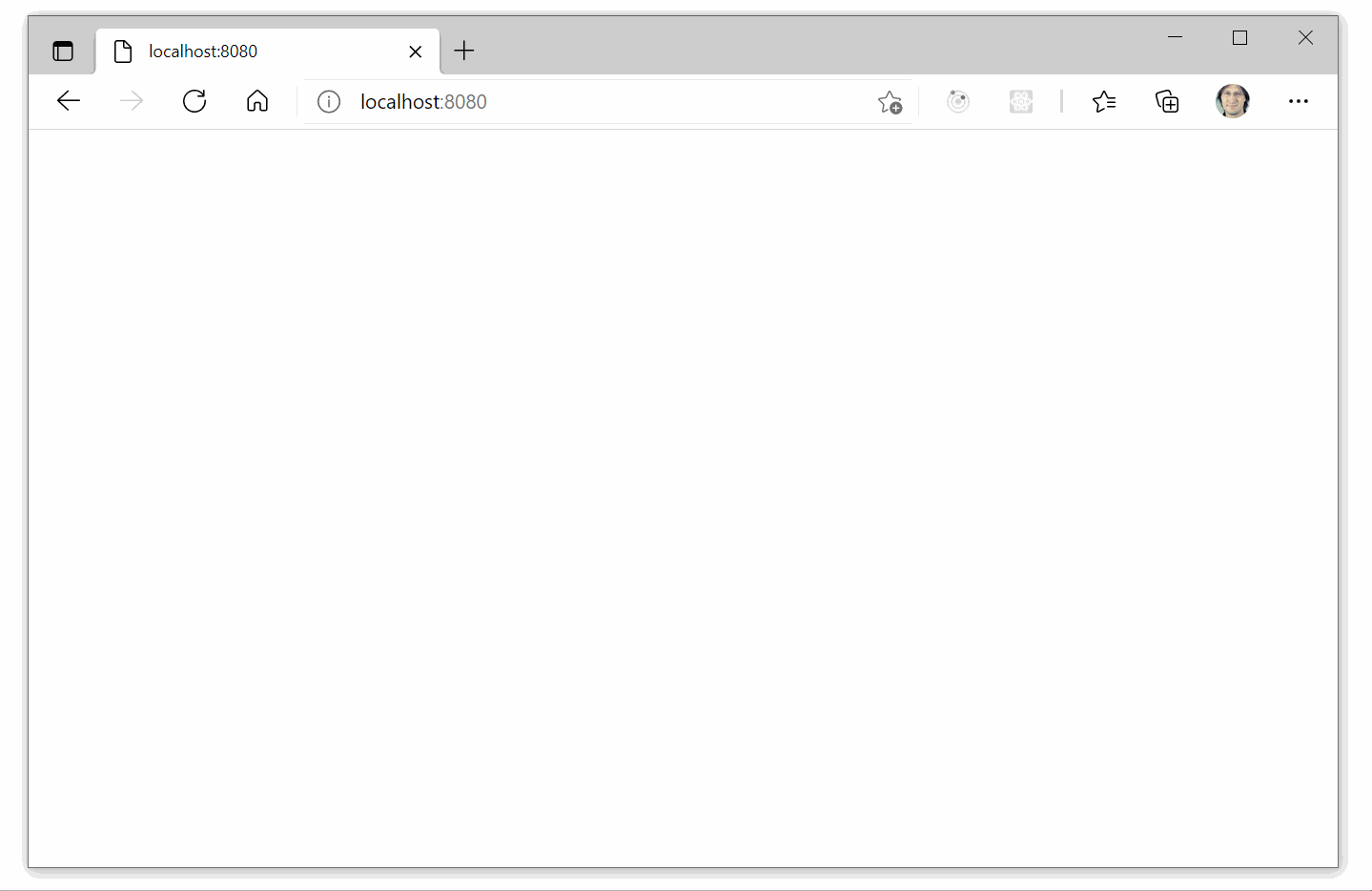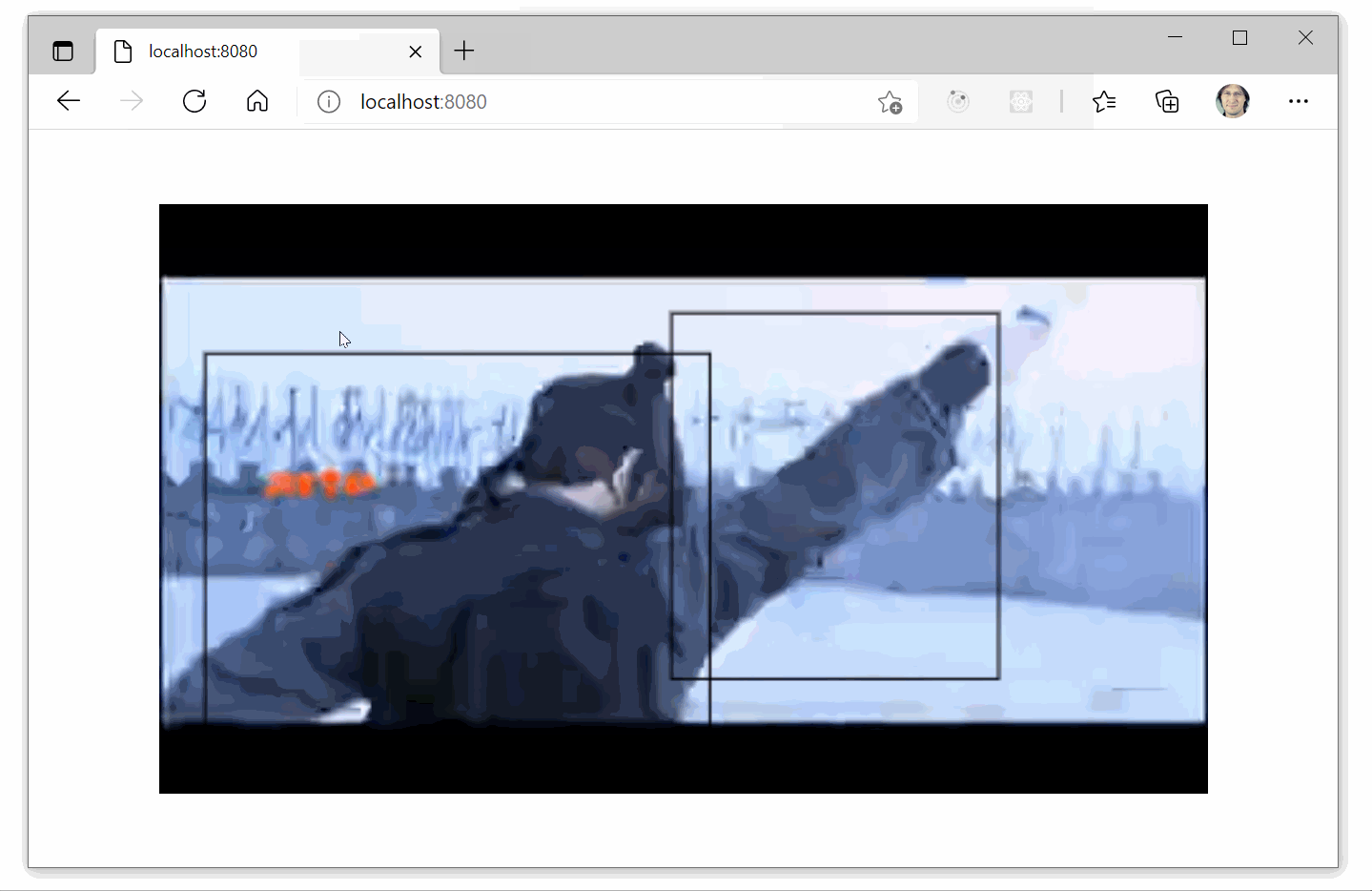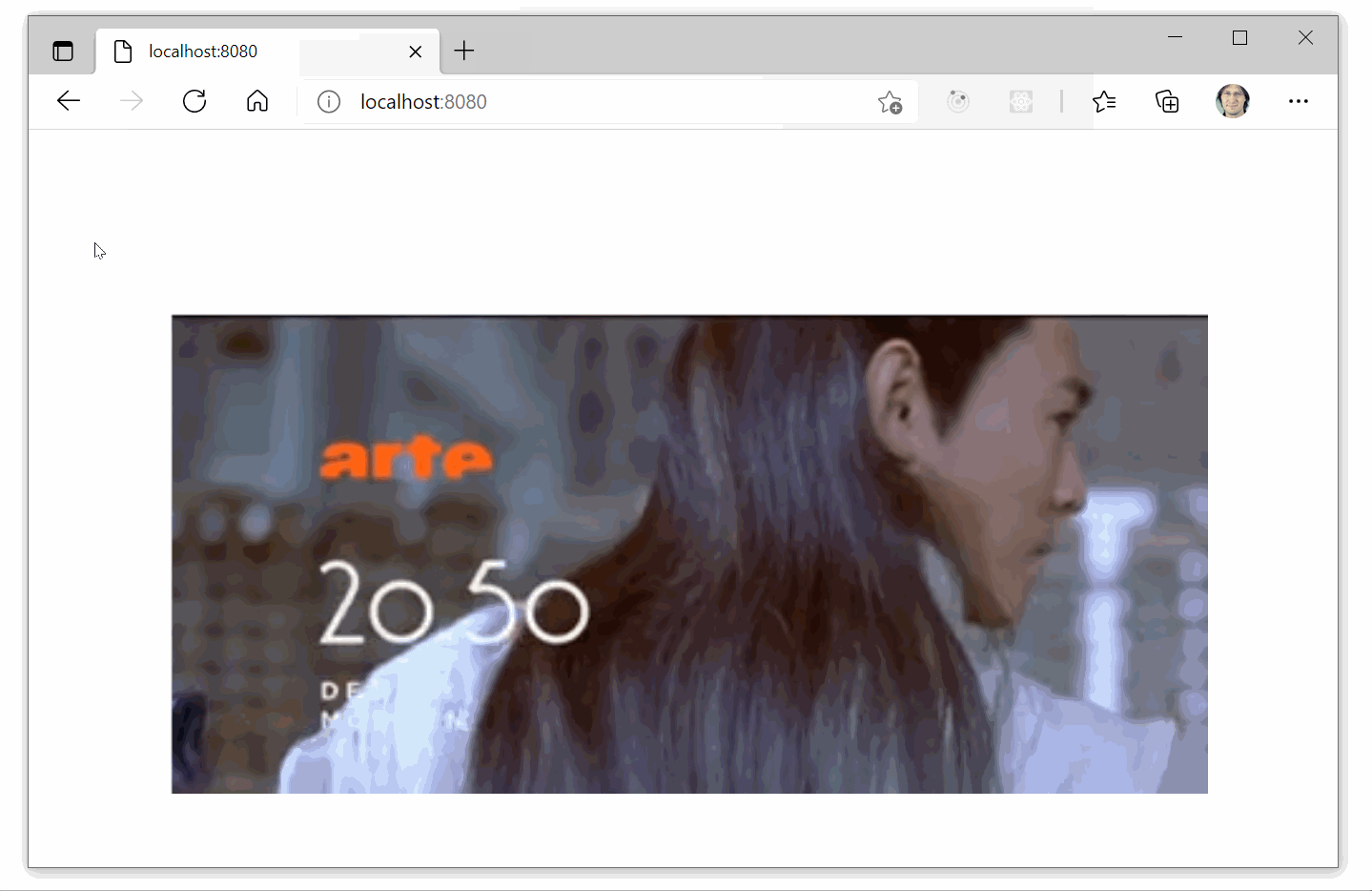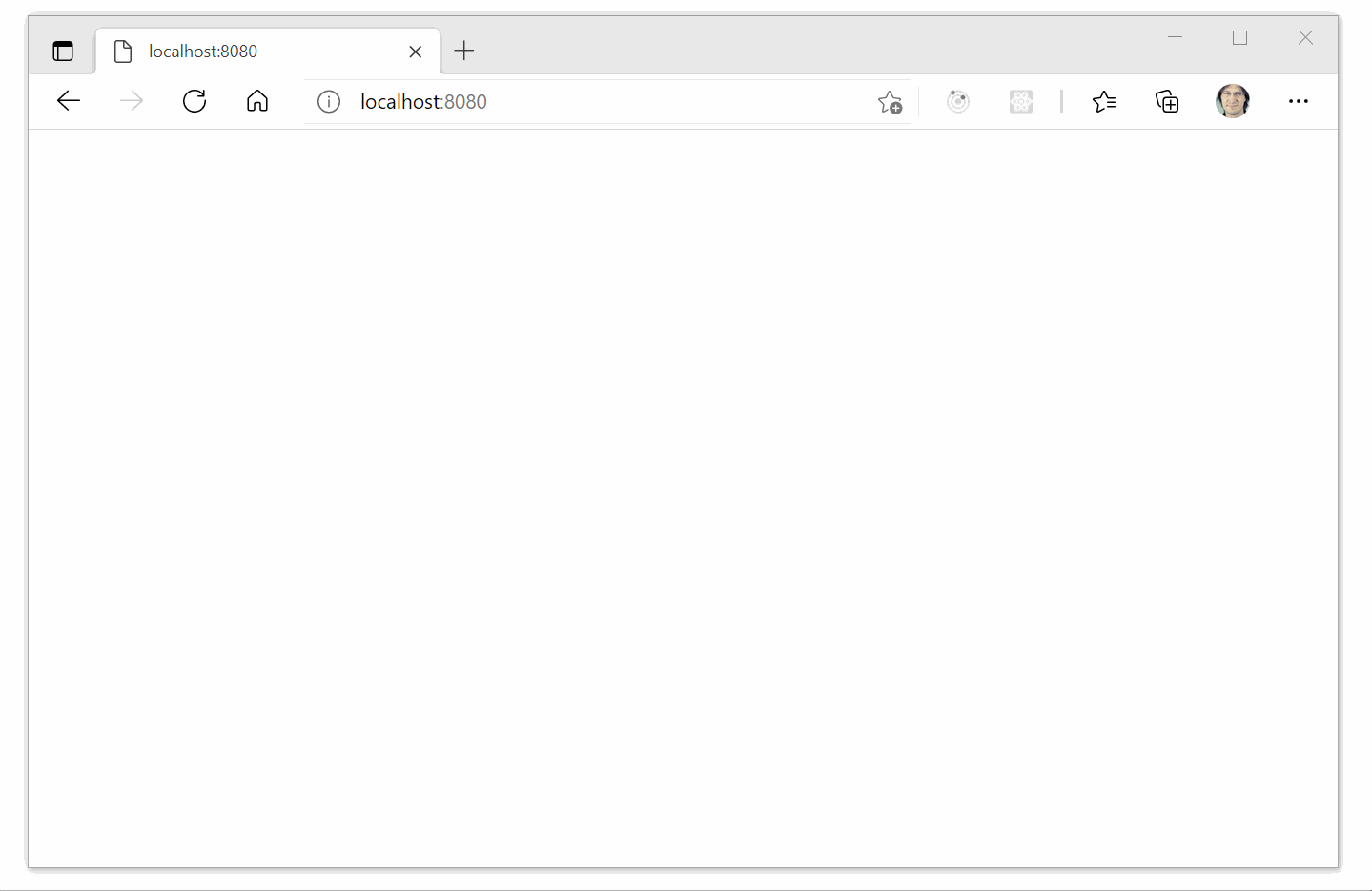
The function returns a function which accepts a callback to process predictions. drawPrediction finally set-up the canvas, and uses the callback function to draw a rectangle above each object identified with a certain confidence. Alternatively, if the mouse is over the canvas then only the content of the frame representing objects are drawn.
function drawPredictions(video, onDetection) {
const canvas = document.createElement("canvas");
const context = canvas.getContext("2d");
canvas.width = video.videoWidth;
canvas.height = video.videoHeight;
const isMouseOver = trackMousePosition(canvas);
onDetection((predictions) => {
const matchingPredictions = getMatchingPredictions(predictions);
if (isMouseOver()) {
showFullVideo(matchingPredictions, context, video);
} else {
showCutOff(matchingPredictions, context, video);
}
});
return canvas;
}
function getMatchingPredictions(predictions) {
const categories = getClasses();
return predictions
.filter(
({ class: category, score }) =>
score > 0.5 && categories.includes(category)
)
.map(({ bbox }) => bbox);
}
function showFullVideo(matchingPredictions, context, video) {
context.drawImage(video, 0, 0);
matchingPredictions.forEach(([x, y, w, h]) => {
context.beginPath();
context.rect(x, y, w, h);
context.stroke();
});
}
function showCutOff(matchingPredictions, context, video) {
context.clearRect(0, 0, context.canvas.width, context.canvas.height);
matchingPredictions.forEach(([x, y, w, h]) => {
context.drawImage(video, x, y, w, h, x, y, w, h);
});
}
The experiment is available on GitHub and a working demo is available on Heroku.
Thanks!



Top comments (0)