| Menu | Next Post: Machine Learning - Types of Learning |
We are always generating data. Everything we do, the way we behave, our opinions, our preferences and even things we own, everything is a possible "type" of data, about something or that defines something.

In the image above we see the same situation twice: people going from one place to another and reading something in the meantime. Let's consider that in the second image people are reading news from a news app, while in the first they have a newspaper.
They have their preferences and opinions, in the first image the relevant newspaper data is highlighted with a pen and in the second image with their own finger, on the cell phone.
In the second image the man, sometimes without noticing, scrolls the cell phone screen directly to the type of news he wants to read while the woman in the first image turns the pages until she reaches the page she likes the most.
In this case, they are reading the same type of data, news, at a different time and year and with different content. So, considering that in the two images people are doing exactly the same thing, what would be the difference besides the date, experience and content displayed?
The difference is that in the second image, in addition to generating data, we are collecting data and in the first image we lost this data. At that moment, this woman was the only person who knew about her own preferences and behavior.
Generating data is something that happens all the time without us even realizing it, whether it's about us and who we are, our preferences, routine and plans or even the universe and science. We live in a world full of data.
Collecting data, however, is something that exponentially expands data generation considering the creation of new technologies, which in a cycle generate more data that would not be generated before, now also collected and stored.
We are each day collecting more data and from more sources.
In this graph we can see how this is going and a prediction made in 2018 that so far is consistent:

To give you an idea of what this means, we can remember the past, the retrospectively referred to as the first true smartphone had 1MB of RAM, along with the same amount of internal storage.
1 Byte = 8 bits
1 Kilobyte (KB) = 1024 bytes
1 Megabyte (MB) = 1024 kilobytes
1 Gigabyte (GB) = 1024 megabytes
1 Terabyte (TB) = 1024 gigabytes
1 Petabyte (PB) = 1024 terabytes
1 Exabyte (EB) = 1024 petabytes
1 Zettabyte (ZB) = 1024 exabytes
With data collection growing exponentially, in addition to collecting data giving a meaning is essential, it means transforming data into information that can be analyzed.
In the chart below we can see the volume of data storage during the years divided into structured and unstructured data.
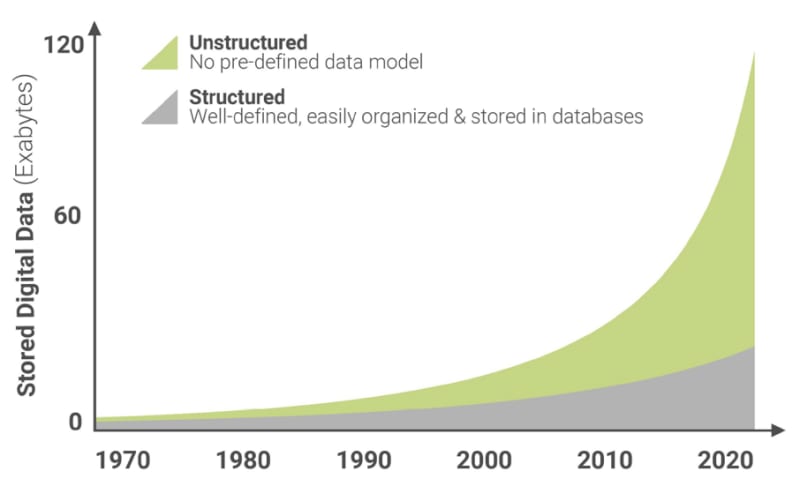
One of the main differences between structured and unstructured data is how easily it can be subjected to analysis. Structured data is overall easy to search and process. Unstructured data is a lot more difficult to search and analyze. Once collected, this data has to be processed to understand its applicability.
Semi-structured data on the other hand, is not purely structured, but not completely unstructured, it is not limited to the structure needed for relational databases but has organizational properties, JavaScript Object Notation (JSON) and Extensible Markup Language (XML) are some of the examples.

While unstructured data represents nearly 80% of all global data, many companies choose to store and analyze structured data.
But with an increasing volume of data and the need for understanding, it is necessary to also analyze unstructured data to obtain new information and insights and consequently have a competitive advantage.
Elasticsearch for example, is a distributed search and analytics engine for all types of data, including textual, numerical, geospatial, structured, and unstructured data, storing data as JSON documents (semi-structured) and making the document data searchable in near real-time.
Once searchable, Artificial Intelligence Algorithms are one of the allies in transforming data into information that can be analyzed, aiming to simulate human intelligence in machines, the models can process data, being able to identify patterns and behavior to provide a better understanding of the dataset.
While it sounds like a new concept, it's not. The birth of Artificial Intelligence took place in the mid-1950s, with several scientists from different fields starting a discussion about the possibility of creating an “Artificial Brain”.

In 1950 Alan Turing published a paper in which he speculated about the possibility of creating machines that think. He noted that "thinking" is difficult to define and devised his famous Turing Test.
At that time many early AI programs used the same type of algorithm to achieve some goal, like proving a theorem, the demands were what we consider Process Driven because it was designed to perform a sequence of actions with a particular purpose, simulating human behavior in performing tasks.
Since then, the concepts and algorithms have continued to improve and with that the need to create statistical models with no need to be explicitly programmed, Data Driven models, with Machine Learning algorithms like Linear Regression, Logistic Regression, Decision Tree, Naive Bayes, SVM, K-Means, Gradient Boosting algorithms, etc.
Years later the use of Deep Learning algorithms, a subset of Machine Learning, also became popular; it was the result of the idea for algorithms to imitate the functioning of the human brain, structuring the algorithms in layers to create an artificial neural network. It has been around since the beginning of AI itself, but it was hard to put into practice as it requires more computing power.
One model is not necessarily better or worse than the other and they are also not mutually exclusive, they can and are often used together, the important thing is to take into account the use case, the available infrastructure, the time for training, processing capacity and the desired input and output.
Elastic machine learning is natively built into the Elastic Platform and you can use it to support the analysis and understanding of data stored in Elasticsearch, detecting anomalies and outliers, classifying, making predictions, processing natural language and applying vector search, for this reason we are going to delve deeper into Machine Learning models and available Elastic solutions.
| Menu | Next Post: Machine Learning - Types of Learning |
This post is part of a series that covers Artificial Intelligence with a focus on Elastic's (Creators of Elasticsearch) Machine Learning solution, aiming to introduce and exemplify the possibilities and options available, in addition to addressing the context and usability.





Top comments (1)
nicely written :)
The thing to be noted here is that Elastic is NOSQL Database, so there is higher scope :)