
Intro
From a DevOps perspective, I can only say what a time to be alive! With the rise of containers all the pain we had with setting up VMs, backup/restore procedures, dynamic provisioning because of scaling because of increased usage volume because of unoptimized architectural setup because of, etc. Everything is gone (well, almost everything from the above list) with a single docker-compose file or a convenient one-liner like helm install my-app.
But, what are containers essentially, and how does Docker work under the hood?
This will be a series describing my journey writing a small, experimental container runtime in what other language than the one perfect for the job — Rust!
Part 0 describes the system features of the Linux OS that Docker and other tools utilize to start a process that is isolated and protected or, in other words, a container. The whole series is based on Linux containers, so any occurrence of the word container is interchangeable with “Linux container”.
The full source code for this post can be found here.
Container
When being asked to describe, with as few words as possible, what a container is, most developers feel disappointed. Described with one tech word, it’s a forked or cloned process. It has a dedicated PID, it’s owned by a user and a group, you can list it with the ps command and send signals to it (yeah, signal #9 too). It’s nothing more than that, nothing super fancy bleeding edge around it, just an old-fashioned process.
But how is it isolated from the rest of the system?
The answer is namespaces.
Namespaces provide the logical isolation of resources for processes running in different sets of namespaces. There are different types of namespaces, for example, MOUNT namespace for all mount points that the current process can see, NETWORK namespaces for the network interfaces and traffic rules, PID for the process tree, and so on. Two processes running in different PID namespaces don’t see the same process tree. A separate NETWORK namespace gets its own network stack, routing table, firewalls and a loopback interface. Two processes with different network namespaces that bind to their respective loopback devices are bound to a separate logical interface so that traffic doesn’t interfere between them.
The MOUNT namespace contains the list of mount points a process can see. When first cloning from a mount namespace (the CLONE_NEWNS flag) all mount points are copied from the parent to the child namespace. Any additional mount point created in the child isn’t propagated to the parent mount namespace. Also, when the child process unmounts any mount point, it’s only being affected inside his mount namespace.

Root (“/”) isn’t an exception either. The root mount point doesn’t have to be (mostly isn’t) the same directory for different mount namespaces. When running a container, Docker (specifically containerd) creates a directory for each container’s root mount point. Before the actual container runs the user-defined process, it’s the container runtime’s responsibility to mount that directory as the container’s root. In that way, each container has its own root mount point that’s separated from the rest of the filesystem and all other containers running on the host.
Each process has a /proc/PID/ns subdirectory on the host containing symlinks for each namespace they belong to (pid, net, user, cgroup, …). If two processes belong to the same namespace, their symlinks will be the same.
Let’s see what namespaces a simple sleep command has (on my machine of course):

Running another process in the same shell and inspecting it’s namespaces gives the same symlinks as the above:

The two processes are run without any extra commands or setup, they have the same namespace symlinks, therefore they belong to the same namespaces.
Linux provides the UNSHARE syscall from the sched.h library to change the process’ execution context and allow it to create and enter new namespaces. After UNSHARE gets called with the specific bit mask (flags combining which namespaces to “unshare” from the execution context), the running process gets detached from the root namespaces into it’s own set of namespaces. Unfortunately, it’s not enough to call UNSHARE and expect to have an isolated container (for example, a parent process that “unshares” the PID namespace, still runs in the root PID namespace, but any child process created afterwards will enter the newly created PID namespace). Usually after the container runtime calls UNSHARE it gets followed by a fork/vfork call to create the actual container process.
CLONE syscall is a far better option and the implementation in Rust’s nix package feels more robust and fine-grained. It gives the ability to specify the namespace flags as in UNSHARE, forks a child process and creates the stack for the child.
SETNS syscall (NSENTER command) gives the option to change the given namespace to an already existing namespace by it’s file descriptor. For example, to fork a shell process that enters the mount namespace of process with PID 15, enter in a new shell (with root permissions):
nsenter --mount=/proc/15/ns/mnt /bin/sh
Enough theory! To confirm everything said above, let’s jump onto a Docker-based example. We’ll run an alpine container, list the process on the host system, inspect it’s namespaces and docker exec into it with SETNS.
Let’s run a long running sleep container:

After inspecting the container’s PID, let’s see the namespace symlinks under /proc/PID/ns:
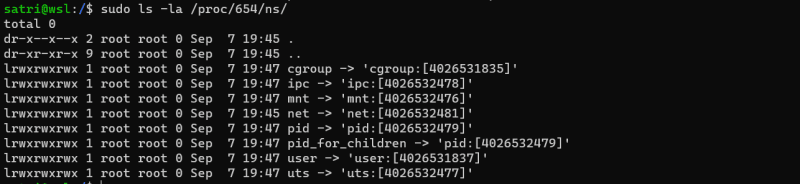
Interesting! Some namespaces are the same as with the above sleep command that we’ve run in our terminal (specifically the user and cgroup namespaces), but most of them are different, which proves that Docker separates containers in different namespaces.
Now, let’s try to exec a shell inside the container to inspect the filesystem:

Starting to make sense? Well, almost…
What’s going on here is that we’ve run NSENTER to start a shell process inside the mount namespace of the container process. The container’s mount namespace is different from the root one because the root directory lists a bit different tree structure than on my WSL instance. Additionally, on my Debian instance, printing the Linux distro info (/etc/os-release) inside the container shows an Alpine Linux distro. So we conclude:
docker exec -it <CONTAINER_ID> <CMD>
equals to:
nsenter -a -t <CONTAINER_PID> <CMD>
- nsenter -a enters all namespace of process with PID specified in the -t arg
Docker
Most readers are already familiar with the Docker client-server model, so it’s unnecessary to explain how the CLI invokes commands on the dockerd service running in the background. Let’s open the front hood and see what’s going underneath.
In the last example, we’ve seen that the docker run command forks a process in a separate namespace set. What’s actually happening is that Docker (again, more specifically containerd, but let’s keep it simple for now) calls the underlying container runtime to create the specified namespaces, prepare the container environment and execute some special commands needed before the actual user-defined command starts.
But if that’s the responsibility of the runtime, what do we use Docker for?
Docker prepares everything before container creation, with the 2 most important parts:
- config.json
- container root directory
These two parts (together with other things that we will discover in this series) are called the container bundle.
The config.json file has the complete layout for the whole container lifecycle, from container start to container deletion. It holds the path for the container root directory, a list of namespaces that need to be unshared, resource limits for the container process, hooks that need to be executed at a specific point in time, and many other settings.
The container root directory is the directory mentioned in the mount namespace section. That’s the subdirectory somewhere on the host system that will be the root directory for the container. The user-defined process MUST NOT know that there’s a whole different world outside the container root directory, which basically “cages” (most literature refers to it as “jails”) the user process inside the container root directory.
Besides these two most important things, Docker does other preparations too (for example, pulls the image layers from the remote repository, sets up the networking interfaces if the container has networking enabled, and so on).
OCI Specification
Standardization is a crucial part of any software integration. From writing REST APIs or gRPC services to designing low-level network protocols, everything starts with a well-defined document describing what needs to be (un)expected behavior and the minimal contract that an implementation needs to fulfill.
The Open Container Initiative (OCI) created and still maintains the OCI runtime specification that can be found here. It’s a spec that still evolves and adds new features that a container runtime can or may execute while launching a container process.
I won’t go into the details of the spec, as it’s described very well in the document, but at least here is what it is in a nutshell.
An OCI-compliant container runtime is a CLI binary that implements the following commands:
create <id> <bundle_path>start <id>state <id>kill <id> <signal>delete <id>
As with any other emerging spec, the OCI runtime spec describes the minimum features for creating a container. Popular container runtime implementations like runc or crun have additional arguments that help setting up the PID file of the process, root folder for the container state, or the socket file for the container terminal.
But don’t worry about these parts. In the upcoming articles in this series, we’ll dive deeper into it with some Rust code.





Top comments (0)