
Essence of the question
As the operating processes on your cluster are represented by pods, Kubernetes offers graceful termination when pods are no longer required. By imposing a default grace period of 30 seconds after you submit a termination request, Kubernetes offers graceful termination.
The steps listed below make up a typical Kubernetes Pod termination:
- To end the Pod, you send a command or make an API call.
- The duration of time after which a Pod is to be regarded as dead is reflected in Kubernetes changes the Pod status (the time of the termination request plus the grace period).
- When a pod enters the Terminating state, Kubernetes stops transmitting traffic to it.
- The
SIGTERMsignal from Kubernetes instructs the Pod to stop operating.
Pods can be terminated for a variety of reasons over the lifecycle of an application. In Kubernetes, these reasons include user input via kubectl delete or system upgrades, among others.
🖼️ A larger picture is here. Also, you may open it in a new browser's tab to zoom in.
On the other hand, a resource problem could lead to its termination.
Misunderstood action
With some configuration, Kubernetes in this scenario enables gentle termination of the operating containers in the Pod. Let's first understand how the delete / termination process proceeds before moving on to the setup.
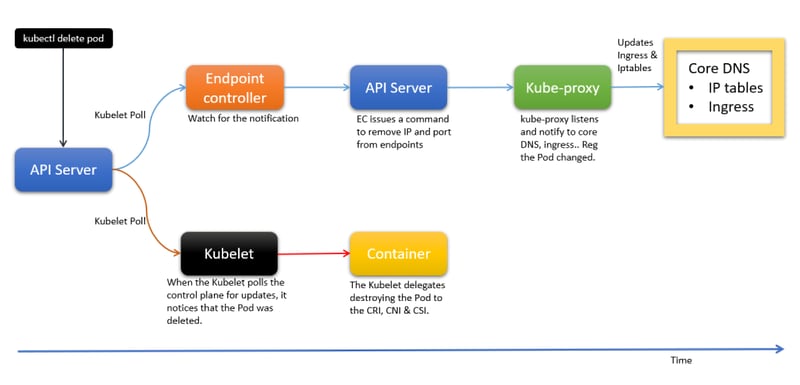
Once the user issues the kubectl delete command, the command is transmitted to the API server, where it is removed from the endpoints object. As we saw when creating the pod, the endpoint is crucial to receive updates when providing any services.
In this action, the endpoint will be immediately removed from the control plane while readiness probes are disregarded. This will start events on the DNS, ingress controller, and kube-proxy.
As a result, all of those components update their references and stop forwarding traffic to the IP address. Please be aware that while this procedure may be speedy, the component may occasionally be preoccupied with other tasks. As a result, a delay might be anticipated, and the reference won't be updated right once.
At the same time, the Pod's status in etcd is changed to Terminating.
The polling alerts Kubelet, which then delegates the activity to components like pod creation.
Here
- By using the Container Storage Interface to unmount all volumes from the container (CSI).
- Relinquishing the IP address to the Container Network Interface and disconnecting the container from the network (CNI).
- To the Container Runtime Interface, destroy the container (CRI).
Note: Kubernetes updates the endpoints after waiting for the kubelet update to provide the IP data during the Pod creation. However, when the Pod terminates, it simultaneously updates the kubelet and removes the endpoint.
Premature termination?
How is this a problem? The hitch, however, is that sometimes it takes some time for components to update endpoints. In this situation, if the pod is killed before endpoints have been propagated, we would experience downtime. Yet why?
As previously indicated, ingress and other high-level services are still not changed, thus traffic is still forwarded to the removed pod. However, we might believe that Kubernetes should update the modifications throughout the cluster and prevent such a problem.
But it unquestionably is not.
Kubernetes does not validate that the changes on the components are current because it distributes the endpoints using endpoint objects and sophisticated abstractions like Endpoint Slices.
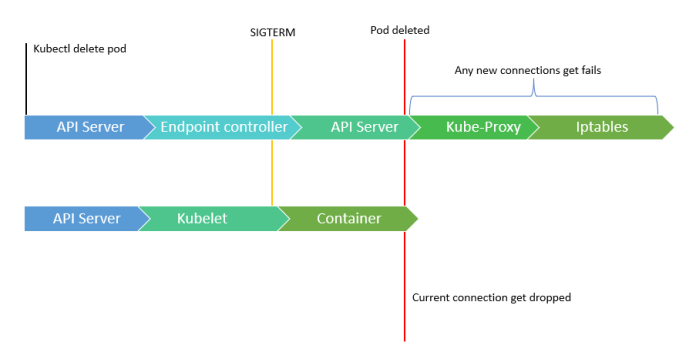
We cannot guarantee a 100% application uptime due to this possibility of downtime. The only way to accomplish this is to wait until the Pod is destroyed before updating the endpoint. We made assumptions based solely on what we observed, but is that really possible? Let's investigate.
API magic?
For that, we must have a thorough understanding of what transpires in containers when the delete command is sent.
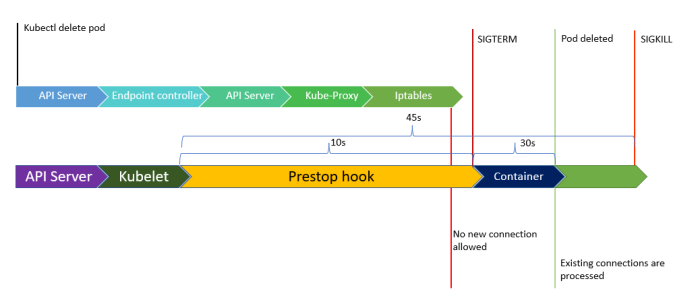
Pod receives the SIGTERM signal after getting kubectl delete. The SIGTERM signal is sent by default by Kubernetes, which then waits 30 seconds before forcibly ending the process. Therefore, we can enable a setting that requires us to wait before acting, such as:
- Prior to leaving, wait a while.
- For another 10 to 20 seconds, the traffic will still be processed.
- Close all backend connections, including those to databases and WebSockets.
- At last, finish the procedure.
You can add or modify terminationGracePeriodSeconds in your pod definition if your application needs longer time (more than 30 seconds) to terminate.
You can add a script that will wait for a while before exiting. In this instance, Kubernetes exposes a pre-stop hook in the pod before the SIGTERM was executed. You can implement this as the following:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: nginx
image: nginx
ports:
- name: nginx
containerPort: 80
lifecycle:
preStop:
exec:
command: ["sleep", "10"]
This option would make the kubelet wait for 30 seconds before advancing the SIGTERM, although it should be noted that this might not be enough since your application might still be handling some older requests. How do you avoid them? This can be done by including terminationGracePeriodSeconds, which will cause the container to wait longer before being terminated. The final manifest will appear:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: nginx
image: nginx
ports:
- name: nginx
containerPort: 80
lifecycle:
preStop:
exec:
command: ["sleep", "10"]
terminationGracePeriodSeconds: 45
Command line hacks
This setting ought to make it easier for the app to handle all requests and shut down connections. This will prevent a shutdown that is forced.
When manually deleting a resource, you may also modify the default grace period by providing the --grace-period=SECONDS argument to the kubectl delete command. For instance:
# kubectl delete deployment test --grace-period=60
What about the Rolling updates?
Pods are removed for yet another reason when we upgrade or deploy a new version. What happens if you upgrade your app from, let's say, v1.1 to v1.2 while operating a v1.1 version with 3 replicas?
- A Pod is created using the new container image.
- Eliminates a current Pod.
- Awaits the completion of the Pod.
- Until every pod has been transferred to the new version, repeat.
Ok, this ensures the deployment of the new version. But what about old pods? Does Kubernetes wait until all the pods have been deleted?
The answer is no.
The old version pods will be gracefully terminated and eliminated as it moves forward. However, as old ones are continuously being removed, there may occasionally be twice as many Pods.
Putting an end to ongoing processes
Even though we have taken all necessary precautions, some apps or WebSockets may require prolonged service, or we may be unable to halt if any lengthy operations are in progress or requests are being made. Rolling updates will be at danger throughout that period. How can we overcome?
There are two options.
The terminationGracePeriodSeconds can be increased to a few hours. Or modifying a current deployment, or starting a new one.
Option 1
If you choose to do so, the pod's endpoint will be out of reach. Also take note that you must manually monitor those pods and cannot use any monitoring software to track them. All monitoring programs gather data from endpoints, and once that data is withdrawn, all monitoring tools will behave similarly.
Option 2
Your old deployment will still be there when you establish the new one. Therefore, all the lengthy processes will continue to run until they are finished. You manually eliminate the previous processes after you can see that they have finished.
You can configure an autoscaler to scale your deployment to zero replicas (third-party tools like KEDA can simplify this) when they run out of jobs if you want to eliminate them automatically. Furthermore, you can keep earlier pods running for longer than the grace period by using this every time.
A less obvious but superior option is to start a fresh Deployment for each update. While the most recent Deployment serves the new users, current users can keep using updates. You can gradually reduce the replication and retire old Deployments as users disconnect from old Pods.
The author hopes this is a helpful article. Consider your options and choose the option that best satisfies your needs!
Pictures courtesy 🐦 @motoskia & 🐦 @foxutech
Some great schematic diagrams can be found here. Thanks, Daniele Polencic.
More to read: How Kubernetes Reinvented Virtual Machines (in a good sense), a great article by Ivan Velichko.





{kind=link}
Top comments (2)
That is great! I think that a preStop hook is great (almost) all workloads. I've made a video about the topic: youtube.com/watch?v=ahCuWAsAPlc
Will have to watch this video.