
Improve your Server Performance By Caching often Fetched Data using Redis.
Introduction:
Redis is an in-memory database that stores data in key: value format, since it’s in memory, it's ridiculously fast.
Redis provides data structures such as strings, hashes, lists, sets, sorted sets
Redis is an open source (BSD licensed), in-memory data structure store used as a database, cache, message broker, and streaming engine. Redis provides data structures such as strings, hashes, lists, sets, sorted sets with range queries, bitmaps, hyperloglogs, geospatial indexes, and streams. Redis has built-in replication, Lua scripting, LRU eviction, transactions, and different levels of on-disk persistence, and provides high availability via Redis Sentinel and automatic partitioning with Redis Cluster. redi.io
case use:
Why you should implement caching layer in your server and how it will improve the performance of the application.
Regular fetched data
caching data that gets fetched too often is a good practice, you won’t let users wait too long to get basic dataReduce query exec against the database
by using caching you will reduce the number of queries that will be executed against the database, aside from the performance improvement you’ll get, you also save your database from being overwhelmed with duplicate queries that return the same result.
also, you will save your precious bandwidth if you are hosting your app at an expensive hosting providerImproving the app performance
caching will not only improve your database performance and protect it, but it will also improve the overall server-client performance.
to get the idea let's assume your server has a route called getArticle, every request that comes to this route will take about half a second (~500 ms ) to get the response, with caching the first request will take about half a second or more, but every next request will take about (~20 ms)! Magic right ?!
I’ll prove it using my own app
Cache vs no Cache:
I did a simple benchmark test on my server (on a single API to see how it takes to complete the request without caching, and re-test the same API with caching to see the improvement.)
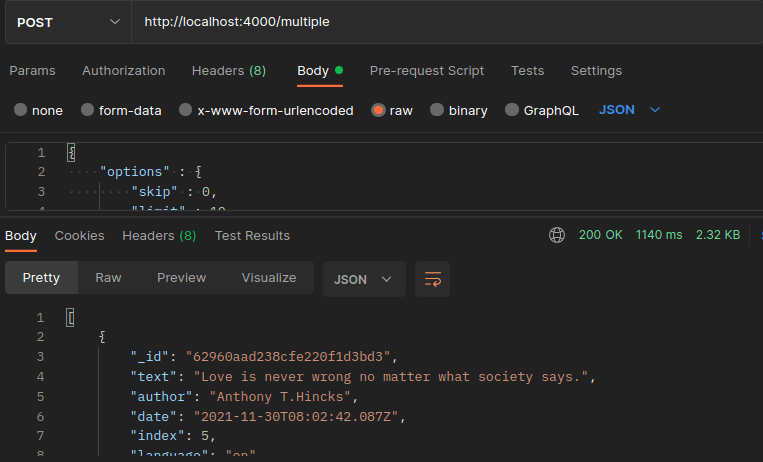
the above image shows you, that it took my server more than a second to complete the request, of course, every time I make a request it will take approximately the same time!
The below image is when I introduced the Caching mechanism to my server’s APIs, you can see the difference in the time by yourself ( i did not change anything in the request)
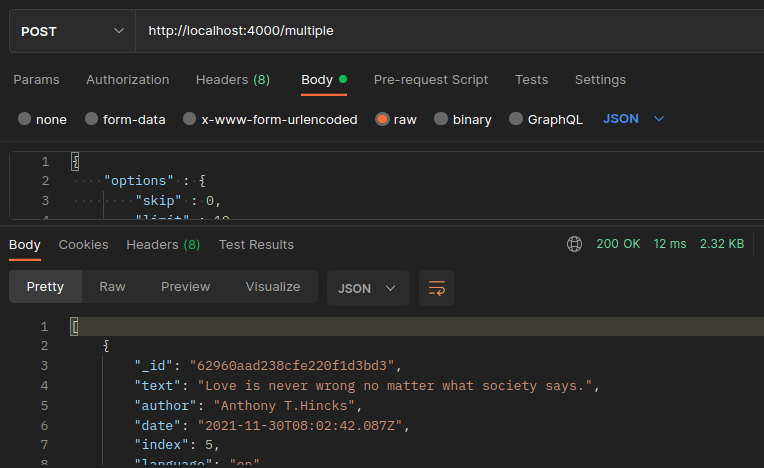
the time to complete the same request in the upcoming times has been reduced to almost ~10 ml, which is a significant improvement!
I hope now you're excited about implementing this technique in your own projects.
Installation:
Install Redis on your machine
in Linux, you can install it by typing in the terminal
sudo apt-get -y install redis
in macOS, in terminal issue the following command
brew install redis
in windows, it's a little bit difficult to get Redis on windows since it’s not officially supported in widows.
Redis is not officially supported on Windows. However, you can install Redis on Windows for development by following the instructions below.
To install Redis on Windows, you’ll first need to enable (Windows Subsystem for Linux). WSL2
WSL2 lets you run Linux binaries natively on Windows. For this method to work, you’ll need to be running Windows 10 version 2004 and higher or Windows 11.https://redis.io/docs/getting-started/installation/install-redis-on-windows/
Install node-Redis to your project:
node-Redis is a modern, high-performance client for Node.js.
npm install redis
Now we installed both Redis and node-redis package, let's do simple work with these great tools and then try it in a real-world example!
Quick start with Redis:
// IMPORTANT : before you can establish connection to redis,
// you must start the redis-server
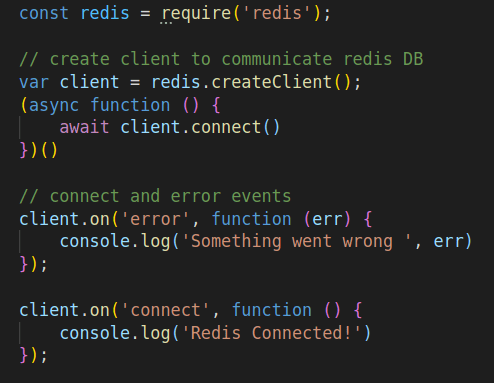
const redis = require('redis');
// create client to communicate redis DB
var client = redis.createClient();
client.connect()
// connect and error events
client.on('error', function (err) {
console.log('Something went wrong ', err)
});
client.on('connect', function () {
console.log('Redis Connected!')
});
connect to Redis server:
To start the Redis server you need to run in the terminal :
redis-server
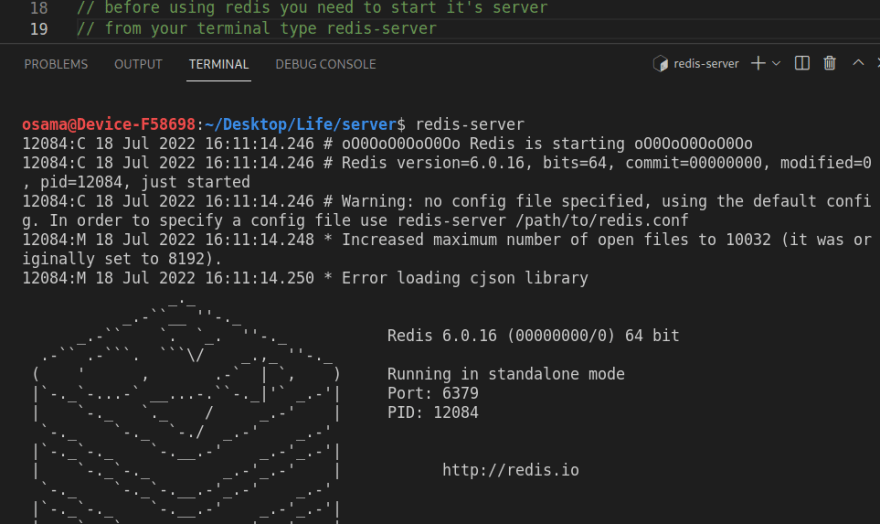
example:

Above we created a client and started the connection to Redis server, now we can use all the features.
// used to put data into redis
client.set("key" , "some value")
// used to get data from redis
client.get("key")
// output = "some value"
Real-world example:
the big question now is how can I make use of these simple functions set() and get(), to improve my server performance?
let’s see my own server (express server to fetch quotes from MongoDB atlas and send it back.)
This Benchmarking test is from my own Quote API (which will be released soon in RapidAPI), we’ll see how the difference in the time it takes when we request 1000, 3000 and 5000 documents of data, I’ll repeat the test by fetching the same data but from the cache this time.
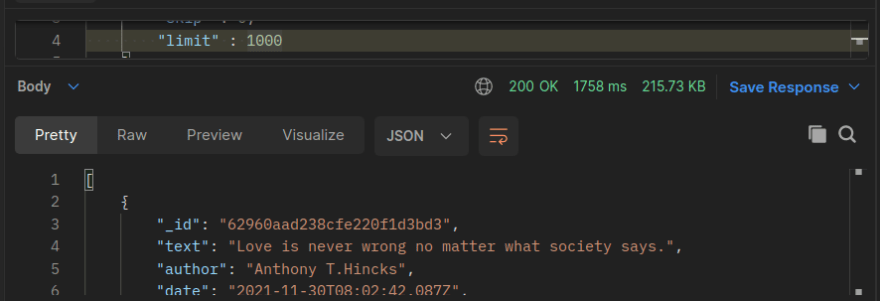
to fetch 1000 documents from the DB took almost 2 seconds

But fetching the same amount of data from the cache it only took 25 milliseconds!

to fetch 3000 documents from the DB it took almost 4 seconds!
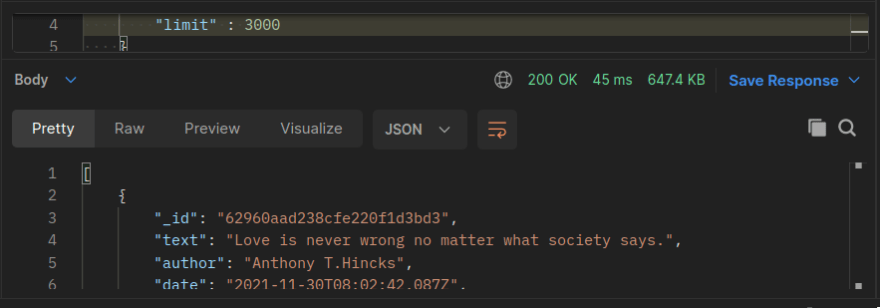
But fetching the same amount of data from the cache it only took 45 milliseconds!

to fetch 5000 documents from the DB took almost 5 seconds!

But from the cache, it only took 60 milliseconds!
Pretty amazing right??
The caching mechanism:
caching is simply adding another layer to your server, this layer will intercept the queries that will be executed by your database, it will search if this query is cached before or not, if so it will return the cached data as a response and will not going to send the query to the database, if the query has not been cached before, it will send the query to the database to get executed and then store the result in the cache (Redis) for the upcoming requests.
](https://res.cloudinary.com/practicaldev/image/fetch/s--2UMU07Ab--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_880/https://cdn-images-1.medium.com/max/2000/0%2ASze6sykRanXIf3PD.png)
So to clarify what we want to do :
connect the server to Redis using the above code
we want to hijack (intercept, interrupt, call it whatever you want) the process of sending the query to the database so we can decide if this query is cached before or not
if cached, return the cached data and end the response. Don’t send anything to the database
if not cached, send the query to get executed and send the result as the response, then store the result in the cache for the new requests.
First of all, you need to create a new file in your project called cache.js, you can name it whatever you want, in the services directory if you have one, if not just put it anywhere.
this file will contain all the logic needed by our server to cache data and retrieve data from Redis.
In the beginning, we’ll need to connect to Redis and make sure it's working fine
key creation:
to store data in Redis we need to give every query a unique and consistent key, so we can retrieve the right query when a request has arrived.
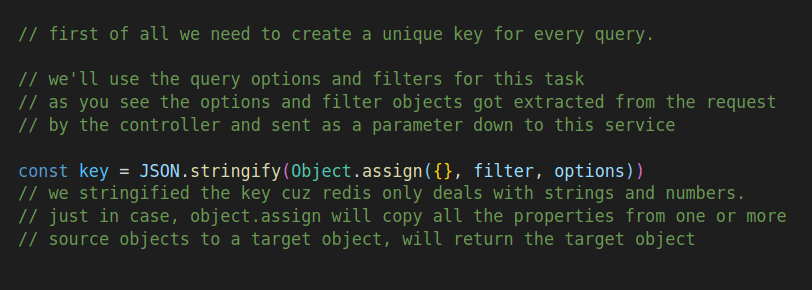
basically, every query to any database has filters and options to get particular documents or records.
we’ll take advantage of this thing and take these filters and turn it into a string
JSON.stringfy({ {title : "story"} , {skip : 10} })
// our key = "{{"title" : "story" }, {"skip" : 10}}"
// everytime any client will request the data that can be fetched
// with this query, the server will repsonse with the cached data
Now we have our key for every query need to be executed in the database, what we’ll do next is to search in Redis for this key, if it does exist, return its value instead of executing the query, if not found, execute the query in the database and store the query result with its key in Redis for next requests and then send the result to the user.
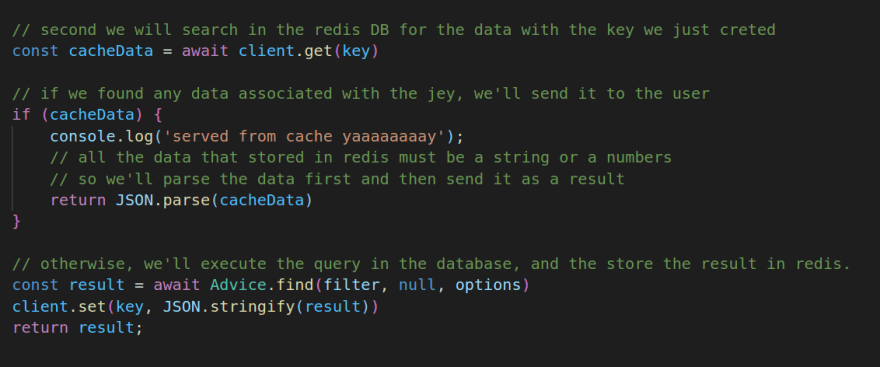
// this line will add the data fetched from mongoDB to redis
client.set(key, JSON.stringify(result))
// always remember, Redis only store values as a string or numbers
Wrap up:
first, you need to create a unique and consistent key for every query.
second, search in Redis for this key, if it's found, return its value as a result, if not, execute the query and store the result in Redis and lastly send it to the user.
References:
The best of all courses to learn node.js in depth.
https://www.udemy.com/course/advanced-node-for-developers/?ranMID=39197&ranEAID=SAyYsTvLiGQ&ranSiteID=SAyYsTvLiGQ-EDfB120pgYcJlhkNSEBp4Q&LSNPUBID=SAyYsTvLiGQ&utm_source=aff-campaign&utm_medium=udemyads
How To Implement Caching in Node.js Using Redis | DigitalOcean
Redis + Node.js: Introduction to Caching - RisingStack Engineering
Caching in Node.js using Redis
Fasten your Node JS Application with a Powerful Caching Mechanism using Redis
Thanks for reading, and feel free to ask any question about javascript or this series, I appreciate any feedback to improve My content.
find me on Twitter, Github and my portfolio.





Top comments (4)
The real world examples you are given here are not real world at all. You’re querying against a MongoDB hosted on Mongo Atlas from a local API Server, on top of that your hosting the Redis Server in your local. That my friend is not even close to a real world setup. I’m not even asking you how far you are from the MongoAtlas server you’re hitting.
Remember that the number one performance culprit is latency. You probably want to put your network army close to the battle (end user), otherwise you lose the war.
Hey Raul,
first of all, I don't have my own server so I rely on cloud providers, I'm sorry I didn't make the benchmarks from my hosted server on heruko I did tests on my local environment.
seconds what I meant by real world I didn't mean the code itself, I mean the server as it is, will be used, I know it's not a typical real-world code but I'm still learning!
third, when I used this code I didn't mean to show off or to teach how to write real world, I just added that as an example to show you how caching can saves a lot of time and improve your deployed server performance and make users happy.
->
Thanks for correcting me, in one article before i thought i need to wrap the connect function with async IIFE, i tried it now without the IIFE and it works perfect!
Thanks.