
In SQL, Window functions are functions that performs operations across a set of rows that are related to the row the function is currently operating on.
Window functions were first introduced in SQL in 2003 with functionality expanded in 2012 and are needed in SQL because they simplify certain complex operations and analysis and can be used to calculate running totals, moving averages, and growth over time amongst others.
The dataset below with a set of rows and columns has a window function operating on a particular column and the result extracted spans an entire new column as shown below.

From the diagram above, we can see a sample dataset with 2 columns (column_1 & column_2). Using the LAG function (which shall be explained later), we can see the result that is produced which spans an entire new column(lag). To get this, all that was needed using window functions was two lines of code as seen below
However, to perform this same operation without window functions in SQL we would need multiple self joins and subqueries.
For this article, we shall be using PostgreSQL and the Pgadmin4 as the GUI which is one of the best Graphical user interface Platforms for PostgreSQL and is very beginner friendly. You can download it here for you PostgreSQL needs.
To start with, we shall look at the basic window functions, which include:
The Ranking functions:- Row number, Rank & Dense rank
The Fetching functions:- Lag, Lead, First_Value & Last_Value.
I created a dataset of Movie downloads which contains certain movie names, genre and number of downloads. This can be created using this SQL statement below.
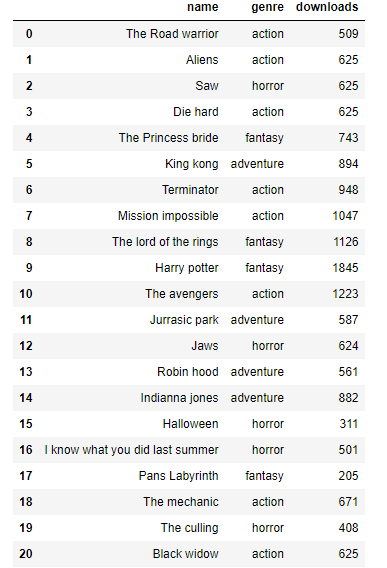
Using the dataset above, we will look at the basic applications of window functions
Ranking Functions. 🥇🥈🥉
Ranking functions are functions that assign numbers to rows in sequential order. To rank a column in a dataset, things like highest and lowest can be easily seen with a glance and it can be used as a reference (index) for other operations in SQL.
The different ranking functions have the same result with very few differences:-
ROW_NUMBER ranks the different rows starting from number 1. It is used mainly as an index for a dataset and can be used for easier reference to each row.
RANK also does the same as ROW_NUMBER above but assigns the same number(s) to identical values and skips the next value(s) for the number of times the number was repeated.
DENSE_RANK also assigns the same number(s) to identical values but doesn’t skip the next value(s) at all.
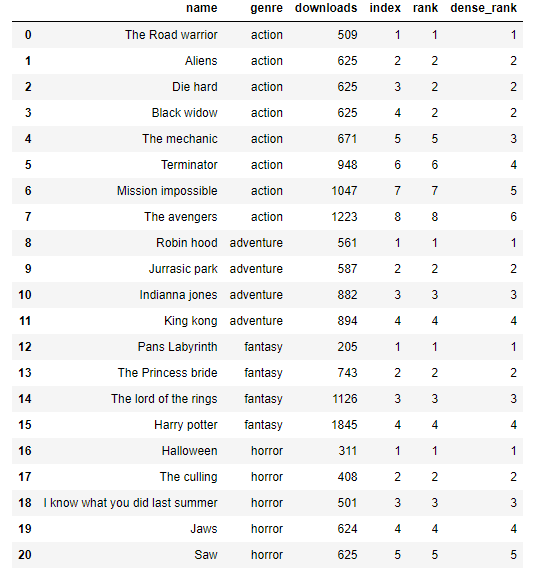
The movies dataset can be ranked as is with the 1st movie recorded as the 1st rank and using the ORDER BY function, it can be ranked from the lowest to the highest number of downloads (as shown below) or vice versa:
The OVER clause in lines 1,2 & 3 is a staple in all window functions and determines exactly how the rows of the query are split up for processing by the window function.
The ORDER BY clause in lines 2 & 3 is used inside the window functions' OVER clause specifying that the ORDER should be determined before the function is executed.

Looking at the output above, we can see the differences between the ROW_NUMBER(), the RANK() and the DENSE_RANK().
Let's take a look at the PARTITION BY clause below:
PARTITION BY, a new clause introduced in this snippet above is used to divide the dataset into different partitions (tables/sections). When this happens, any window function executed in the dataset sees each partition as a table. We can see that inside the OVER clause, we have PARTITION BY genre and the ORDER BY clause. In SQL, the code on the inside is executed 1st which means that the table will be partitioned and ordered accordingly before the window function is applied.
🥏🐕 Fetching Functions
The Fetching functions work a bit differently from the ranking functions:
LAG returns the value at n rows before the current row.
LEAD returns the value at n rows after the current row.
In line 1, we can see LAG(downloads, 1): this tells the LAG function to lag the downloads column by 1 by returning the values of the downloads column but skipping the 1st row (pushes the values of the column down one row 😊).
The LEAD function does the same but instead, it starts at the bottom (pushes up) and since its LEAD(downloads, 2) it skips 2 rows as seen below.

The last two window functions in this article are pretty straight forward.
The FIRST_VALUE returns the value of the first row in a table or partition and LAST_VALUE returns the value of the last row in a table or partition.
Nothing new in this snippet above. The FIRST_VALUE clause is pretty easy to code but take a look at this one below:
The LAST_VALUE clause is followed by RANGE BETWEEN. Normally, window functions read from the beginning of the table/partition to the current row the window function is operating on. So it doesn't extend to the end of the table but rather stops at the specified row, but the LAST_VALUE clause starts at the bottom of the table so the RANGE BETWEEN is used to extend the window function to the end of the table.

Window functions make SQL life much easier and can be used in different ways. Now go grab yourself a dataset and get to work 🔥🔥





Top comments (0)