
Aggregate functions are mathematical computations that return a single value from a range of values which expresses the significance of the aggregated data. They are used to derive descriptive statistics and provide key numbers in different sectors like the health, economic, and business sectors.
The diagram below shows the typical operation on an aggregate function on a specific column and what the result looks like.
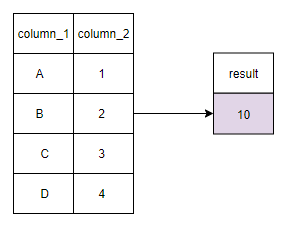
In the diagram above we can see the dataset with two columns (column 1 & column 2). Using the SUM function on column 2 we can see that it adds up all the values in that column and returns a single value in the "result" column.
For this article, we shall be using PostgreSQL and Pgadmin4 as the GUI which is one of the best Graphical user interface platforms for PostgreSQL and is very beginner-friendly. You can download it here for your PostgreSQL needs.
Getting back into it, the different aggregate functions are:
SUM: adds up all the values of a specified column.
MIN: the minimum value of a specified column.
MAX: the maximum value of a specified column.
AVG: the average number of values of a specified column.
COUNT: the number of values (rows) of a specified column/table.
Aggregate functions can only be used in the SELECT and HAVING clause where:
The SELECT clause lists or specifies the column that will be returned for the SQL query and
The HAVING clause specifies a search condition for a group or an aggregate.
I created a dataset of movie downloads for this article which contains certain movie names, genres, and the number of downloads. This can be created using the SQL statement below:

Using the dataset above, we will look at the applications of the different aggregate functions.
🔥Let's go!!
COUNT()
The COUNT function is the most straightforward function and the best to start with:
The "COUNT(*)" in line 1 above is used to count all the rows in the dataset. This gives the result in the image below:

However, when the COUNT function is used on a column, it counts only the values in that column that are, not NULL:
looking at the count_aggregate_function_2 snippet of code above and the count_aggregate_function_1 snippet before that, we can see that the only difference is the "genre" column which is in the COUNT function and not "*" which denotes all the columns in the table.
The result as seen in the image below is not the same as the COUNT for the entire table because that column contains two NULL values:
![]()
Apart from the COUNT function, all the other aggregate functions are only used on one column at a time. Following this, let's look at the other functions!!
SUM()
The SUM function was used to illustrate aggregate functions visually in the image at the start of this article, so it's pretty clear that it adds up the values of a column. Unlike the COUNT function, the SUM function can only be used on columns with a numeric data type:
![]()
From line 1 in the code snippet above, we can see that the SUM function is applied to the downloads column (a numeric data type column).
AVG()
The AVG function gets the mean of all values of a specified column. The mean of a set of numbers is the sum of all the numbers in that set divided by the number of values (count) in the set.
Same as the SUM function, the AVG function can only be used on numeric columns:
![]()
MIN() & MAX()
The MIN and MAX functions are opposites of the same coin in that the MIN function gets the lowest value of a specified column and the MAX function gets the highest value of a specified column. Unlike the other two functions above, the MIN and MAX functions can be used on columns with numerical, date-time, and even character/string data types as seen below:

Let's take a look at some helpful clauses - AS, GROUP BY and ORDER BY clause.
Take a look at this code below:
![]()
The result for the snippet of code above is confusing without the code.
Now look at this one:

This one is better, isn't it? 😉
The AS command is used to rename a column or table with an alias (which only exists for the duration of the query).
The result for the snippet is easier to understand with the AS command added in. This can be used for all sorts of queries to make your output easier to understand.
There are cases when aggregate functions does not return a single value per column:

In line 3 above, the GROUP BY clause is introduced. It groups the SUM of the downloads according to the different genres.
The GROUP BY clause groups rows with the same values into summary rows. It is used on categorical columns.
Now let's take a look at the URDER BY clause:

The ORDER BY clause is introduced in line 4 above. It is used to order the output of a column(s) in a table in either ascending (ASC) or descending (DESC) order.
HAVING()
The HAVING clause is used as a conditional statement for aggregate functions or/and arithmetic. It is used with the GROUP BY clause to filter groups or aggregates based on a specific condition(s).
It is very similar to the WHERE clause to filter/restrict the results of a query. However, unlike the WHERE clause, it can only be used with the SELECT statement and must be used with the GROUP BY clause.
In this case, we will see how aggregate functions are used to filter a table using the HAVING clause:

In the snippet above, the GROUP BY clause returns the rows grouped according to the "genre" column and the HAVING clause specifies the condition to filter the groups.
Now let's dive into using aggregate functions as window functions.
Aggregate Functions in Window functions
Window functions are functions that perform operations across a set of rows that are related to the row the function is currently operating on. There are different window functions and they are used to simplify complex operations.
To understand the different window functions and how they are used in SQL, check out Window Functions in SQL.
In this article, we shall look at window functions and aggregate functions.
All the aggregate functions can be used as window functions and they each give awesome and unique results depending on what you are looking for.
Let's look at the SUM() as a window function that gives running totals:
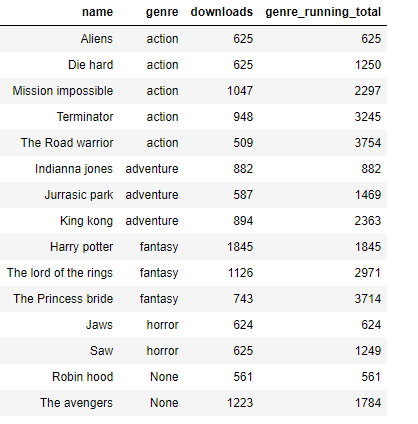
The aggregate window function was used to get the running totals for the number of downloads per genre.
- In Line 1, all the columns were selected because aggregate window functions do not return a single value as a result. They behave completely like window functions whilst retaining their computational qualities.
- Line 2, is where the aggregate window function SUM() OVER() is introduced as a brand new column named "genre_running_total". This new column is a running total on all the downloads that are split into partitions by their genres and ordered by both the name of the movies and their genres.
Using Aggregate functions either on their own (SUM(), COUNT(), e.t.c) or as a filter (with the HAVING clause) or as a window function (SUM() OVER()) gives different results.
They are very useful and make SQL coding and data presentation as well as analysis a lot easier.
I hope this has answered some of your questions and given you some new ideas!!
I'll be Back 😎
Bye for now.





Top comments (0)