
Everyone wants their Elasticsearch cluster to index and search faster, but optimizing both at scale can be tricky. In 2015, Kenna’s cluster held 500 million documents and we processed a million of them a day. At the time, Elasticsearch was the least stable piece of our infrastructure and could barely keep up as our data size grew. Today, our cluster holds over 4 billion documents and we process over 350 million of them a day with ease.
Building a cluster to meet all of our indexing and searching demands was not easy. But with a lot of persistence and a few “OH CRAP!” moments, we got it done and learned a hell of a lot along the way. In this two part blog I will share the techniques we used at Kenna to get us to where we are today. However, before I dive into all the Elasticsearch fun, I first want to tell you a little bit about Kenna.
What is Kenna Security?
Kenna helps Fortune 500 companies manage their cybersecurity risk. The average company has 60 thousand assets. An asset is basically anything with an IP address. The average company also has 24 million vulnerabilities. A vulnerability is how you can hack an asset. With all this data it can be extremely difficult for companies to know what they need to focus on and fix first. That's where Kenna comes in. At Kenna, we take all of that data and we run it through our proprietary algorithms. Those algorithms then tell our clients which vulnerabilities pose the biggest risk to their infrastructure so they know what they need to fix first.
We initially store all of this data in MySQL, which is our source of truth. From there, we index the asset and vulnerability data into Elasticsearch:
Elasticsearch is what allows our clients to really slice and dice their data anyway they need so search speed is a top priority. At the same time, the data is constantly changing, so indexing is also extremely important.
Let’s start with how we were able to scale our indexing capacity. Despite our tumultuous start, we did get one thing right from the beginning and that was setting our refresh interval.
Refresh Interval
First off, what is an Elasticsearch refresh? An Elasticsearch refresh is when Elasticsearch flushes it's in-memory buffers and commits the data that you have recently indexed to a segment. When committing to a segment, it is basically just writing it to disk. When you initially index data it is held in a buffer like this:

Then, when a refresh happens, that data is committed to a segment and becomes searchable. This process is illustrated below.
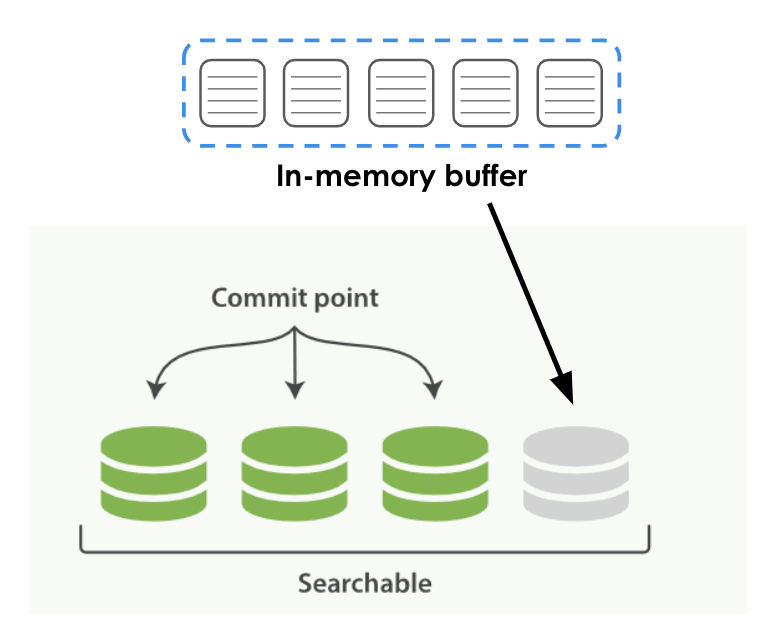
The Elasticsearch refresh interval dictates how often Elasticsearch will execute a refresh. By default, Elasticsearch uses a one-second refresh interval. This means it is flushing those buffers every single second. Refreshing an index takes up considerable resources, which takes away from the resources you could use for indexing. One of the easiest ways to speed up indexing is to increase your refresh interval. By increasing it, you will decrease the number of refreshes executed and thus free up resources for indexing. We have ours set at 30 seconds.

Our client data updates are handled by background jobs, so waiting an extra 30 seconds for data to be searchable is not a big deal. If 30 seconds is too long for your use case, try 10 or 20. Anything greater than one will get you indexing gains.
Once we had our refresh interval set it was smooth sailing — until we got our first big client. This client had 200,000 assets and over 100 million vulnerabilities. After getting their data into MySQL, we started to index it into Elasticsearch, but it was slow going. After a couple days of indexing we had to tell this client that it was going to take two weeks to index all of their data. TWO WEEKS! 😬 Obviously, this wasn't going to work long term. The solution, was bulk processing.
Bulk Processing
Instead of indexing documents individually,

we grouped them into a single batch and indexed them all at once using a bulk request.
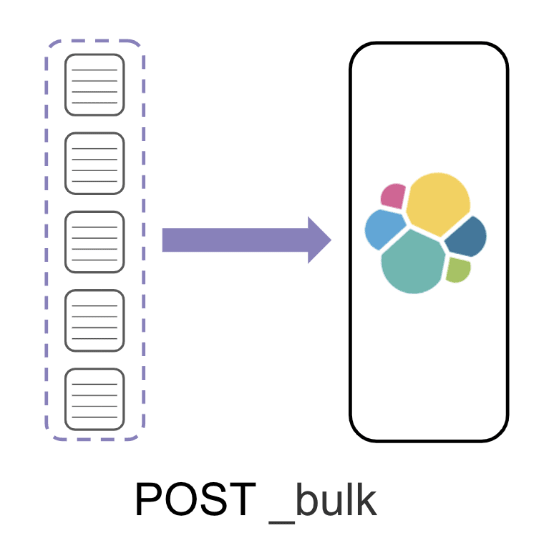
We found that indexing 1000 documents in each bulk request gave us the biggest performance boost. The size you want to make your batches will depend on your document size. For tips on finding your optimal batch size, check out Elastic's suggestions for bulk processing.
Bulk processing alone got us through a solid year of growth. Then, this past year, MySQL got an overhaul and suddenly Elasticsearch couldn't keep up. During peak indexing periods, node CPU would max out and we started getting a bunch of 429 (TOO_MANY_REQUESTS) errors.

YES, that really is a screen shot of our nodes during one of our indexing onslaughts! Our cluster couldn't handle the amount of data we were trying to shove into it and started rejecting requests. After a lot of documentation reading and Googling, we suddenly became very aware of threads and the role they play in indexing. This leads me to my final piece of advice, route your documents!
Route Your Documents
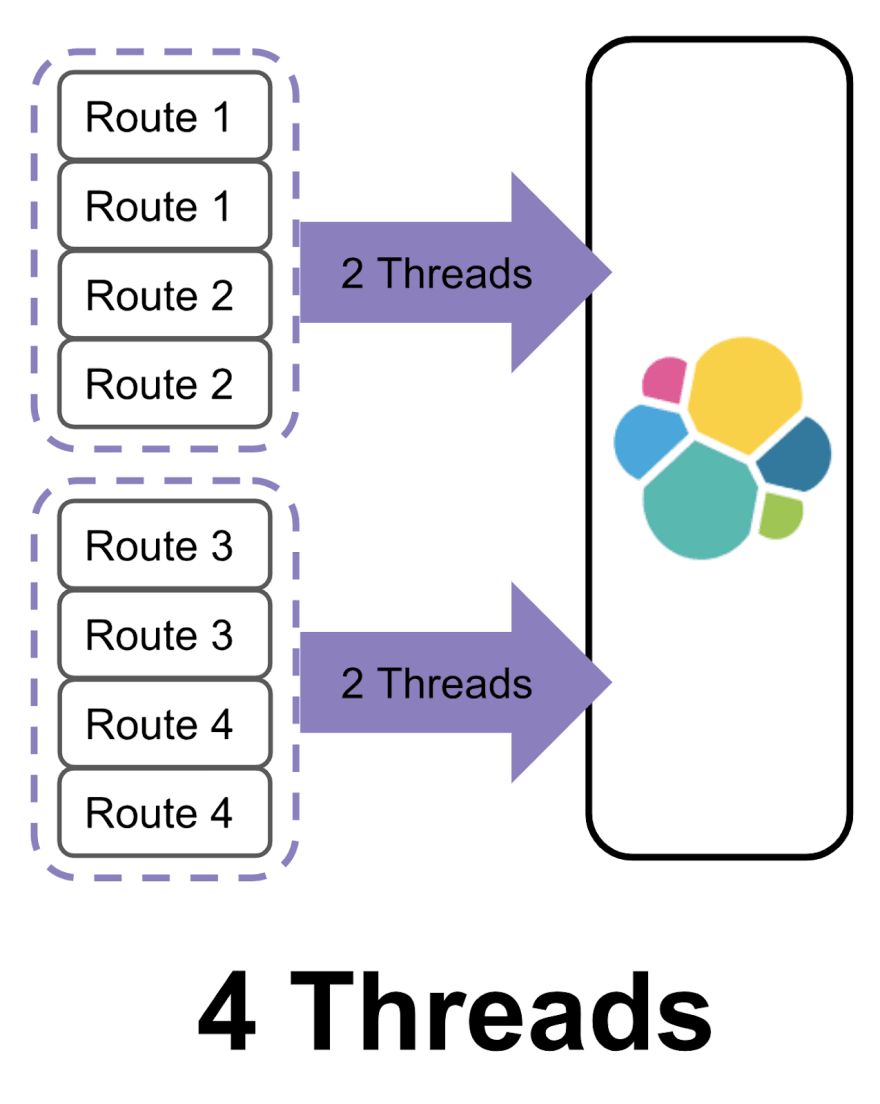
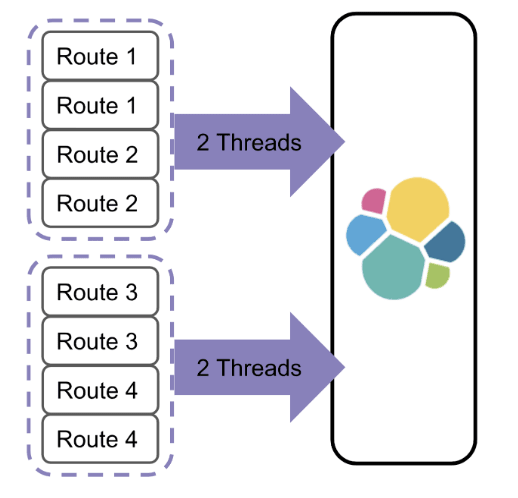
When you are indexing a set of documents, the number of threads needed to complete the request depends on how many shards on which those documents belong. Let's look at two batches of documents:

It's going to take four threads to index each batch because each one needs to talk to four shards. An easy way to decrease the number of threads you need for each request is to group your documents by shard. Going back to our example, if you group the documents by shard, you can cut the number of threads needed to execute the request in half.
Seems easy, right? Except, how do you know what shard a document belongs on? The answer is routing. When Elasticsearch is determining what shard to put a document on it uses this formula:

The routing value will default to the document _id or you can set it yourself. If you set it yourself, then you can use it when you are indexing documents. Let's look at that example again. Since our route value corresponds with the shard a document belongs on, we can use that to group our documents and reduce the number of threads needed to execute each request.
At Kenna, we have a parent/child relationship between assets and vulnerabilities. This means the parent, or asset_id, is used for routing. When we are indexing vulnerabilities, we group them by asset_id to reduce the number of threads needed to fulfill each request.
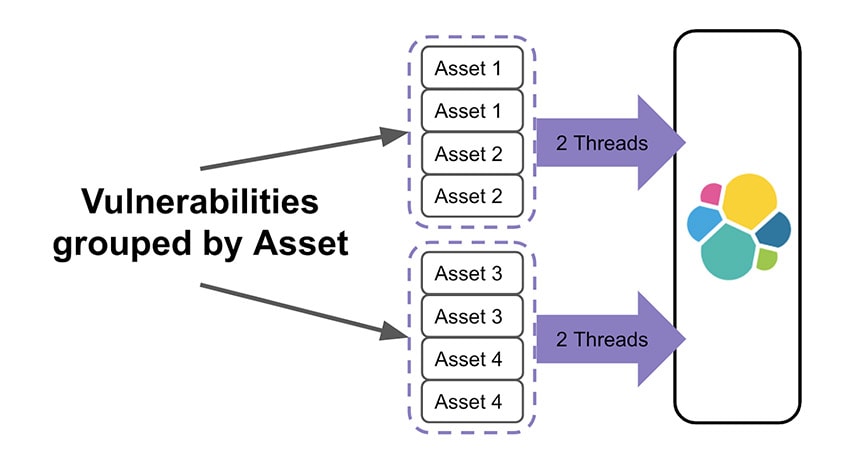
Grouping documents by their routes has allowed us to ramp up our indexing considerably, while keeping the cluster happy.
Recap: Speeding up Indexing at Scale
- Toggle your refresh interval
- Bulk process documents
- Route your documents
Planning Ahead
These techniques have gotten Kenna to the point where we can process over 350 million documents a day and we still have room to grow. When your cluster is small, and you are not processing a lot of data, these small adjustments are easy to overlook. However, as you scale, I guarantee these techniques will be invaluable. Plan ahead and start implementing these indexing strategies now so you can avoid slow downs in the future.
Now, indexing speed is only half of the picture. At Kenna, search is also a top priority for our clients. In part two of this blog post I will dive into all the ways Kenna was able to speed up its search while scaling its cluster.
This blog was originally published on elastic.co





Top comments (9)
Hi Molly, great article. Are you using a self hosted cluster or a managed option? Something like elastic.co or AWS Elastic?
If you have experience in both setups, did you notice any speed differences?
Our cluster is self hosted on AWS. We use Ansible to deploy it. My colleague
Joe Doss
Here are his slides
Thanks!
Hi Molly. Thanks for this article, very useful. Can you say what number of ES nodes do you use, now and historically? How much did this number helped your performance compared to optimizations you wrote about?
We had 21 nodes before we made these optimizations, amongst others, at that time we had 750 million documents, processing a 10-20 million a day
We now have 22 nodes in our cluster which holds over 5 billion documents and processes over 500 million of them a day.
Making optimizations to our data structure and the way we handled the data allowed us to scale without having to increase the size of our cluster. The extra node was added very recently to added additional space for our growing set of documents. We haven't seen really any big performance boost from having it.
Always glad to see more Elasticsearch articles here! Congrats on 350mm per day, that's great!
edit: Just realized this is "part 1", can't wait!
Yay! I am glad it was useful! Please feel free to reach out anytime, I love talking ES shop with people 😊
Thank Molly, very useful article