
I wanted to write this post because the most common question I get when I issue a pull request for an optimization is, "How the hell did you find that?!" My answer 90% of the time is, "I read the logs."
I think reading logs is a lost art these days. We have so many awesome monitoring tools that allow us to keep tabs on our applications that it's easy to forget about a simple resource like logs. Monitoring tools are great for getting a big picture look at your application. However, when it comes to the nitty gritty about how your code is interacting with your datastores and third party services, nothing beats reading the logs.
Optimizing Code
The next time you are looking to make some code optimizations consider doing this. Go into your development or staging environment and set your logging to debug EVERYWHERE!
Set it for your framework.
pry(main)> Rails.logger.level = 0
Set it for your gems.
pry(main)> Search.connection.transport.logger = Logger.new(STDOUT)
Set it for every one of your related services.
$ redis-cli monitor > commands-redis-2018-10-01.txt
Once your logging configurations are set, let loose on your application. Load webpages, run background workers, even jump into a console and run some commands by hand. When you are done, look at the logs that are produced. Those logs are going to tell you A LOT about how your code is interacting with all of your datastores and third party services. I would bet that some of it, is not interacting how you would expect. I cannot stress enough how valuable something as simple as reading logs can be when it comes to making optimizations in an application.
Fitting Logs into Your Workflow
Finding a piece of code to optimize sometimes is as simple as reading the logs. Other times, it can be a little more involved. Here is one example of how my team used logs to find and fix a piece of code.
The first indication that there was a problem was a Redis High Traffic Alert we got from our monitoring service.
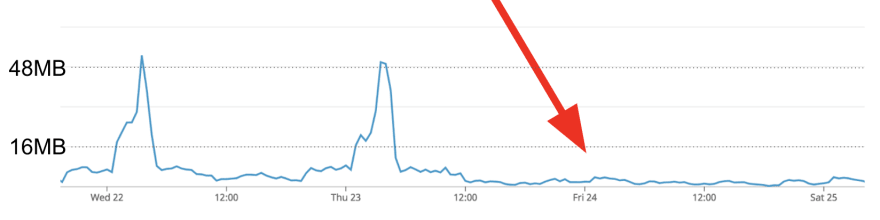
Usually when a piece of code is underperforming in our application the first thing we see is some sort of alert like a high traffic alert, slow query alert, timeout alert, etc. After receiving this alert, the next thing we did was look at the Redis traffic graphs during the timeframe when the alert occurred.

We can see from this graph the problem piece of code is running for a few hours early in the morning. Now that we know the WHERE and WHEN, the next step is to figure out the WHAT. This is where service monitoring comes in handy. Use your monitoring tools to figure out what was running at the time. Using our monitoring service we were able to figure out that during that time window we were running a lot of one specific type of Resque worker.
Once we pinned down the traffic to that one worker, the final piece of the puzzle was figuring what that worker was doing to cause the load. This is where the reading the logs comes in!
Since we knew what worker boxes were causing the issue we jumped onto one of them and fired up redis-cli.
$ redis-cli monitor
We let that run for 30 seconds while the workers were doing work and this is a snippet of what we got.
# REDIS LOG FORMAT
# timestamp [redis_db ip_address:PID] command argument
1544451182.095873 [15 1.1.1.1:15288] "exists" "worker-01-shard-1"
1544451182.095888 [15 1.1.1.6:63462] "exists" "worker-02-shard-3"
1544451182.095941 [15 1.1.1.4:55676] "exists" "worker-05-shard-3"
1544451182.095952 [15 1.1.1.8:55596] "exists" "worker-02-shard-3"
1544451182.095983 [15 1.1.1.8:55682] "exists" "worker-09-shard-2"
1544451182.096225 [0 1.1.1.11:19286] "llen" "batching:indexing-worker:medium_priority"
1544451182.096260 [15 1.1.1.4:55564] "exists" "worker-03-shard-3"
1544451182.096280 [15 1.1.1.7:18378] "exists" "worker-02-shard-3"
1544451182.096309 [15 1.1.1.4:55594] "exists" "worker-02-shard-2"
1544451182.096439 [15 1.1.1.5:14774] "exists" "worker-03-shard-2"
1544451182.096502 [15 1.1.1.7:12098] "exists" "worker-03-shard-3"
1544451182.096672 [15 1.1.1.1:32618] "exists" "worker-03-shard-3"
To our surprise, we found that we were making a ton of EXISTS requests from a specific set of worker boxes. We then traced the EXISTS requests back to a gem that we were using to throttle our Resque workers. We were pretty sure those requests were the ones overwhelming Redis. The last thing left to do was confirm it. We removed the throttling code, and sure enough, that eliminated the Redis traffic.
Big Picture
The code examples I show use Ruby, but honestly, the concept of reading logs can apply to any language. The next time you find yourself faced with slow code or a bug you can't find, consider reading your logs. Best case, they help you solve your problem. Worst case, you get a better understanding about how your code is working.
Happy coding!






Top comments (15)
Great article Molly!
I also give a big priority to my logs because it's the only feedback I can have from my app.
We use a JSON logs specification to have a common logs format on all the apps in my project and to allow to build common kibana dashboards for all of them.
But with a high trafic, logs can become a bottleneck and may sometimes be replaced by some "code instrumentalization" (e.g. Prometheus exporter or whatever).
Interesting! I have never heard of Prometheus, that looks neat. For production we have Fluentd setup for exporting logs to our Elasticsearch logging cluster and we also use Kibana for creating dashboards and saving searches. We have found Fluentd works really nice with Ruby which is why we choose it over something like logstash.
We also use Fluentd rather than logstash in our logs stack.
Prometheus is a great tool, but it's not based on the logs. Your app has to provide an API from which Prometheus will grab your metrics to build real-time aggregated dashboards.
Prometheus + Graphana = graphing heaven. :)
I heart common log formatting. Done right it is very helpfuil; done wrong, the problem you stated.
Delayed follow up (it took a while for grep to finish!): we had a conversation about /how/ to do logging back in '17 that fits nicely with Molly's why & when:
dev.to/grhegde09/logging-done-righ...
That's a great post! I love that we both linked back to Star Trek on it, great minds think alike 😉
Great article!
I used to work in a project, in which my team was developing a windows driver. We invested heavily in logging. The goal was to have a logging system that can be enabled/disabled in runtime at any time. Then we did our own tool to improve log parsing.
What we've achieved was truly impressive. There were single cases when I needed to use WinDbg for something else than extracting logs from a memory dump. However, the most important was, that we were able to diagnose in field issue, by asking a customer to run a command and send us a log output (btw. logs were binary and could only be read if we shared symbol files). One cannot praise enough such feature if your product is shipped with millions of computers.
Excellent article! I have a question: what log level do you set for your production environment?
info! Let me know if you have any other questions :)
LOL! :D
Fabulous post Molly
Thank you! This community you have formed seems really awesome, I am excited to contribute more to it :)
This is one of those things that come with experience
What software development skills only come with experience?
Ben Halpern
Tracking bugs is fun (most of the times).
Nice post :)
So true!
Logs can be really intimidating when you are a new developer bc the first time you see them flash by there are so many. I think in the future I will try to encourage new developers to look more at the logs when they are starting out. Even if it's just for small pieces of code, I think it would help them get more familiar with the code and how logging works.